一、背景知识
介绍:KVM 全称是 基于内核的虚拟机(Kernel-based Virtual Machine),它是Linux 的一个内核模块,该内核模块使得 Linux 变成了一个 Hypervisor。
KVM架构:KVM 是基于虚拟化扩展(Intel VT 或者 AMD-V)的 X86 硬件的开源的 Linux 原生的全虚拟化解决方案。KVM 本身不执行任何硬件模拟,需要用户空间程序(QEMU)通过 /dev/kvm 接口设置一个客户机虚拟服务器的地址空间,向它提供模拟 I/O,并将它的显示映射回宿主的显示屏。
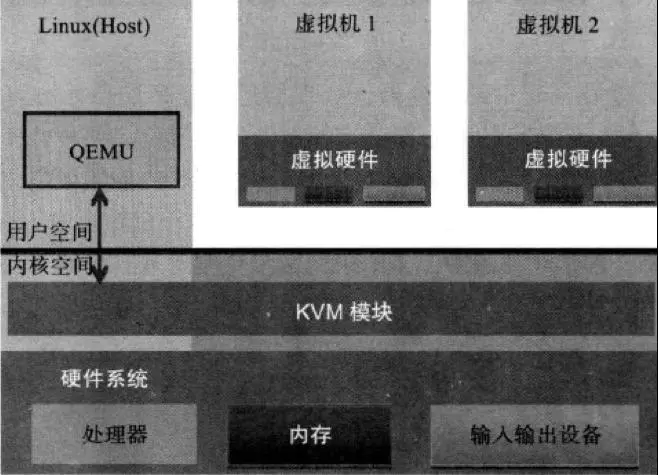
- Guest:客户机系统,包括CPU(vCPU)、内存、驱动(Console、网卡、I/O 设备驱动等),被 KVM 置于一种受限制的 CPU 模式下运行。
- KVM:运行在内核空间,提供 CPU 和内存的虚级化,以及客户机的 I/O 拦截。Guest 的 I/O 被 KVM 拦截后,交给 QEMU 处理。
- QEMU:修改过的被 KVM 虚机使用的 QEMU 代码,运行在用户空间,提供硬件 I/O 虚拟化,通过 IOCTL /dev/kvm 设备和 KVM 交互。
KVM 是实现拦截虚机的 I/O 请求的原理:现代 CPU 本身实现了对特殊指令的截获和重定向的硬件支持,以 X86 平台为例,支持虚拟化技术的 CPU 带有特别优化过的指令集来控制虚拟化过程。通过这些指令集,VMM 很容易将客户机置于一种受限制的模式下运行,一旦客户机试图访问物理资源,硬件会暂停客户机运行,将控制权交回给 VMM 处理。
QEMU-KVM: 其实 QEMU 原本不是 KVM 的一部分,它自己就是一个纯软件实现的虚拟化系统,所以其性能低下。但是,QEMU 代码中包含整套的虚拟机实现,包括处理器虚拟化,内存虚拟化,以及 KVM需要使用到的虚拟设备模拟(网卡、显卡、存储控制器和硬盘等)。为了简化代码,KVM 在 QEMU 的基础上做了修改。VM 运行期间,QEMU 会通过 KVM 模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于处理的特殊模式运行。当虚机进行 I/O 操作时,KVM 会从上次系统调用出口处返回 QEMU,由 QEMU 来负责解析和模拟这些设备。从 QEMU 角度看,也可以说是 QEMU 使用了 KVM 模块的虚拟化功能,为自己的虚机提供了硬件虚拟化加速。除此以外,虚机的配置和创建、虚机运行所依赖的虚拟设备、虚机运行时的用户环境和交互,以及一些虚机的特定技术比如动态迁移,都是 QEMU 自己实现的。
虚拟化对比:1.基于二进制翻译的全虚拟化——客户机运行于Ring1,需执行特权指令时触发异常,VMM捕获异常并翻译和模拟,最后返回客户机;性能损耗大。2.半虚拟化(操作系统辅助虚拟化)——修改操作系统内核,替换不能虚拟化的指令,通过hypercall直接和底层的虚拟化层hypervisor来通讯;省去了全虚拟化中的捕获和模拟,效率高,如XEN,但需修改系统所以不支持windows。3.硬件辅助的全虚拟化——Intel VT 或AMD V的CPU,支持两种模式,VMM 可以运行在 VMX root operation模式下,客户 OS 运行在VMX non-root operation模式下,VMM负责进行模式切换(只有模式切换的开销),CPU可以直接执行客户机指令,所以虚拟机性能逼近半虚拟化。
Libvirt:Hypervisor 比如 qemu-kvm 的命令行虚拟机管理工具参数众多,难于使用,而Libvirt提供统一、稳定、开放的源代码的应用程序接口(API)、守护进程 (libvirtd)和一个默认命令行管理工具(virsh)。架构是基于驱动程序的架构,支持多种语言接口,很多虚拟机管理工具和云计算平台都使用了libvirt。
二、KVM实现
现在很多文章都是在讲怎样用libvirt或者QEMU来实现KVM,本文则是直接从底层实现KVM。从底层实现KVM可参考Using the KVM API,github上还有两个项目kvm-hello-world和kvmtool也很不错,OSDev.org上有很多关于操作系统的文章。
作者实现的内核可以在用户空间执行ELF文件:
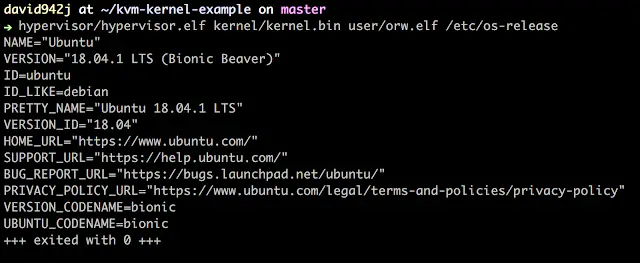
1.Start
通过ioctl与KVM进行通信,设置设备的状态。
创建基于KVM的VM的步骤:
- 打开KVM设备,
kvmfd=open("/dev/kvm", O_RDWR|O_CLOEXEC)。 - 创建VM,
vmfd=ioctl(kvmfd, KVM_CREATE_VM, 0)。 - 设置为客户机设置内存:
ioctl(vmfd, KVM_SET_USER_MEMORY_REGION, ®ion)。 - 创建虚拟CPU:
vcpufd=ioctl(vmfd, KVM_CREATE_VCPU, 0)。 - 为vCPU设置内存:
vcpu_size=ioctl(kvmfd, KVM_GET_VCPU_MMAP_SIZE, NULL)。run=(struct kvm_run*)mmap(NULL, mmap_size, PROT_READ|PROT_WRITE, MAP_SHARED, vcpufd, 0)。
- 将汇编代码放进用户区域,设置vCPU的寄存器,如rip。
- 运行和处理退出:
while(1) { ioctl(vcpufd, KVM_RUN, 0); ... }。
总之,一个VM需要用户内存区域和虚拟CPU。
(1)Step 1-3, 设置新VM
/* step 1~3, 创建VM并设置用户内存区域*/
void kvm(uint8_t code[], size_t code_len) {
// step 1, open /dev/kvm
int kvmfd = open("/dev/kvm", O_RDWR|O_CLOEXEC);
if(kvmfd == -1)
errx(1, "failed to open /dev/kvm");
// step 2, create VM
int vmfd = ioctl(kvmfd, KVM_CREATE_VM, 0);
// step 3, set up user memory region
size_t mem_size = 0x40000000; // size of user memory you want to assign
void *mem = mmap(0, mem_size, PROT_READ|PROT_WRITE,
MAP_SHARED|MAP_ANONYMOUS, -1, 0);
int user_entry = 0x0;
memcpy((void*)((size_t)mem + user_entry), code, code_len);
struct kvm_userspace_memory_region region = {
.slot = 0,
.flags = 0,
.guest_phys_addr = 0,
.memory_size = mem_size,
.userspace_addr = (size_t)mem
};
ioctl(vmfd, KVM_SET_USER_MEMORY_REGION, ®ion);
/* end of step 3 */
// not finished ...
}
以上代码中,给客户机分配1GB(mem_size)内存,并将汇编代码放在第一页,之后设置指令指针指向0x0(user_entry),客户机将从该地址开始执行。
(2)Step 4-6 设置新vCPU
/* step 4~6, 创建和设置 vCPU */
void kvm(uint8_t code[], size_t code_len) {
/* ... step 1~3 omitted */
// step 4, create vCPU
int vcpufd = ioctl(vmfd, KVM_CREATE_VCPU, 0);
// step 5, set up memory for vCPU
size_t vcpu_mmap_size = ioctl(kvmfd, KVM_GET_VCPU_MMAP_SIZE, NULL);
struct kvm_run* run = (struct kvm_run*) mmap(0, vcpu_mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED, vcpufd, 0);
// step 6, set up vCPU's registers
/* standard registers include general-purpose registers and flags */
struct kvm_regs regs;
ioctl(vcpufd, KVM_GET_REGS, ®s);
regs.rip = user_entry;
regs.rsp = 0x200000; // stack address
regs.rflags = 0x2; // in x86 the 0x2 bit should always be set
ioctl(vcpufd, KVM_SET_REGS, ®s); // set registers
/* special registers include segment registers */
struct kvm_sregs sregs;
ioctl(vcpufd, KVM_GET_SREGS, &sregs);
sregs.cs.base = sregs.cs.selector = 0; // let base of code segment equal to zero
ioctl(vcpufd, KVM_SET_SREGS, &sregs);
// not finished ...
}
以上代码中,我们创建vCPU并设置寄存器,每个kvm_run结构对应一个vCPU,可利用该结构来获取CPU状态,注意每个VM可以创建多个vCPU,利用多线程和多个vCPU来模拟1个VM。注意:vCPU默认运行于real mode(20位分页内存,即1M地址空间,地址访问没有限制,不支持内存保护、多任务或代码优先级),也即只执行16-bit汇编代码,若想运行32或64-bit,需设置页表。
(3)Step 7 执行
/* last step, run it! */
void kvm(uint8_t code[], size_t code_len) {
/* ... step 1~6 omitted */
// step 7, execute vm and handle exit reason
while (1) {
ioctl(vcpufd, KVM_RUN, NULL);
switch (run->exit_reason) {
case KVM_EXIT_HLT:
fputs("KVM_EXIT_HLT", stderr);
return 0;
case KVM_EXIT_IO:
/* TODO: check port and direction here */
putchar(*(((char *)run) + run->io.data_offset));
break;
case KVM_EXIT_FAIL_ENTRY:
errx(1, "KVM_EXIT_FAIL_ENTRY: hardware_entry_failure_reason = 0x%llx",
run->fail_entry.hardware_entry_failure_reason);
case KVM_EXIT_INTERNAL_ERROR:
errx(1, "KVM_EXIT_INTERNAL_ERROR: suberror = 0x%x",
run->internal.suberror);
case KVM_EXIT_SHUTDOWN:
errx(1, "KVM_EXIT_SHUTDOWN");
default:
errx(1, "Unhandled reason: %d", run->exit_reason);
}
}
}
这里只需注意两种情况,KVM_EXIT_HLT和KVM_EXIT_IO,指令hlt触发KVM_EXIT_HLT,指令in和out 触发KVM_EXIT_IO。当然in和out不只是用作I/O,也可以作为hypercall,与主机通信,本例只把字符输出到设备。
ioctl(vcpufd, KVM_RUN, NULL)会一直运行,直到退出(如hlt、out、error)。你也可以单步模式,每条指令停一下。
尝试我们的VM:
int main() {
/*
.code16
mov al, 0x61
mov dx, 0x217
out dx, al
mov al, 10
out dx, al
hlt
*/
uint8_t code[] = "xB0x61xBAx17x02xEExB0
xEExF4";
kvm(code, sizeof(code));
}
执行结果:
$ ./kvm
a
KVM_EXIT_HLT
2.执行64-bit程序
执行64位程序,需把vCPU设置为long mode,设置成long mode的过程请参考Setting Up Long Mode。最麻烦的是要为虚拟地址映射到物理地址设置页表。x86-64处理器使用了内存管理特性PAE (Physical Address Extension)(采用三级页表,表入口为64位,使CPU直接访问的物理地址空间大于4G,即232),有4种表PML4T、PDPT、PDT和PT,每个PML4T指向PDPT,每个PDPT指向PDT,每个PDT指向PT。
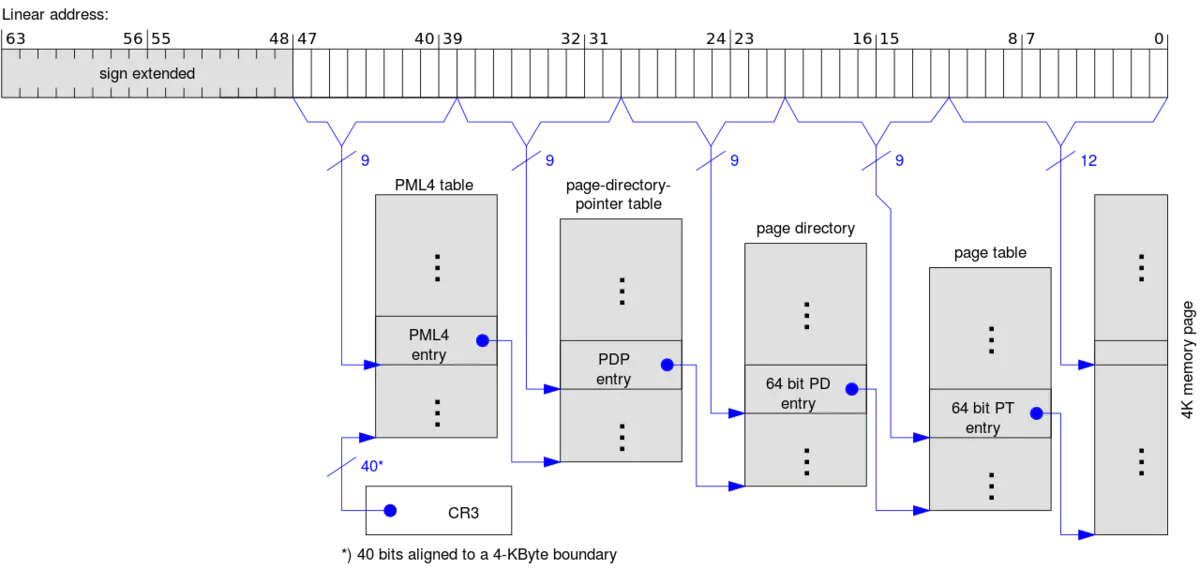
上图表示4K分页方法。还有2M分页方法,移除了PT(页表),PDT直接指向物理地址。
控制寄存器cr*用于设置分页属性,如cr3指向物理地址pml4。更多控制寄存器信息可参见Control_register(CR0—保护模式、写保护等;CR1—访问它时会报错undefined behaviorUD;CR2—页错误线性地址PFLA,当发生页错误时,将被访问的地址存于CR2;CR3—页目录基址寄存器PDBR,若设置CR0的PG位,则CR3高20位存第一个页目录入口的物理地址,若设置CR4的PCIDE位,则低12位用于进程上下文标识符PCID;CR4—SMEP、SMAP等;CR5-7—保留)。
以下代码使用2M分页方法,设置表:
/* Maps: 0 ~ 0x200000 -> 0 ~ 0x200000 */
void setup_page_tables(void *mem, struct kvm_sregs *sregs){
uint64_t pml4_addr = 0x1000;
uint64_t *pml4 = (void *)(mem + pml4_addr);
uint64_t pdpt_addr = 0x2000;
uint64_t *pdpt = (void *)(mem + pdpt_addr);
uint64_t pd_addr = 0x3000;
uint64_t *pd = (void *)(mem + pd_addr);
pml4[0] = 3 | pdpt_addr; // PDE64_PRESENT | PDE64_RW | pdpt_addr
pdpt[0] = 3 | pd_addr; // PDE64_PRESENT | PDE64_RW | pd_addr
pd[0] = 3 | 0x80; // PDE64_PRESENT | PDE64_RW | PDE64_PS
sregs->cr3 = pml4_addr;
sregs->cr4 = 1 << 5; // CR4_PAE;
sregs->cr4 |= 0x600; // CR4_OSFXSR | CR4_OSXMMEXCPT; /* enable SSE instructions */
sregs->cr0 = 0x80050033; // CR0_PE | CR0_MP | CR0_ET | CR0_NE | CR0_WP | CR0_AM | CR0_PG
sregs->efer = 0x500; // EFER_LME | EFER_LMA
}
table中记录着一些控制位,如页是否可mmaped、可写、用户可访问。例如,PDE64_PRESENT | PDE64_RW表示内存可mmaped、可写,0x80(PDE64_PS表示2M分页而不是4K)。
以下代码是为了设置段寄存器:
void setup_segment_registers(struct kvm_sregs *sregs) {
struct kvm_segment seg = {
.base = 0,
.limit = 0xffffffff,
.selector = 1 << 3,
.present = 1,
.type = 11, /* execute, read, accessed */
.dpl = 0, /* privilege level 0 */
.db = 0,
.s = 1,
.l = 1,
.g = 1,
};
sregs->cs = seg;
seg.type = 3; /* read/write, accessed */
seg.selector = 2 << 3;
sregs->ds = sregs->es = sregs->fs = sregs->gs = sregs->ss = seg;
}
我们只需修改创建VM的第6步,以支持64位指令:
将
sregs.cs.base = sregs.cs.selector = 0; // let base of code segment equal to zero
改为
setup_page_tables(mem, &sregs);
setup_segment_registers(&sregs);
现在我们可以执行64位汇编代码:
int main() {
/*
movabs rax, 0x0a33323144434241
push 8
pop rcx
mov edx, 0x217
OUT:
out dx, al
shr rax, 8
loop OUT
hlt
*/
uint8_t code[] = "HxB8x41x42x43x44x31x32x33
jYxBAx17x02x00x00xEEHxC1xE8xE2xF9xF4";
kvm(code, sizeof(code));
}
执行结果如下:
$ ./kvm64
ABCD123
KVM_EXIT_HLT
hypervisor的源码可见repository/hypervisor。
到此为止,KVM的介绍已经完毕,接下来将讲解如何实现简单的kernel。
三、 kernel
实现kernel前,需弄明白几个问题:1.CPU怎么区别内核模式和用户模式?2.用户调用syscall时,CPU怎样将控制转移到kernel?3.内核怎样在kernel和user间切换?
1. 背景知识
(1)内核模式vs用户模式
内核模式和用户模式有一个重要的不同,有些指令只能在内核模式下执行,如hlt和wrmsr,两种模式通过段寄存器中的dpl (descriptor privilege level 优先级描述符)来区分,用户模式下cs.dpl=3,内核模式下cs.dpl=0。
注意,real mode模式下,内核需手动处理段寄存器;在x86-64模式下,指令syscall和sysret会自动设置段寄存器,不需要手动设置。
另一个不同是设置页表权限,以上例子中,我们把所有页表入口设置为用户不可访问。
pml4[0] = 3 | pdpt_addr; // PDE64_PRESENT | PDE64_RW | pdpt_addr
pdpt[0] = 3 | pd_addr; // PDE64_PRESENT | PDE64_RW | pd_addr
pd[0] = 3 | 0x80; // PDE64_PRESENT | PDE64_RW | PDE64_PS
如果内核要为用户设置虚拟内存,例如处理用户的 mmap调用,需设置页表第3位(1 << 2),这样就能从用户空间访问页。
pml4[0] = 7 | pdpt_addr; // PDE64_USER | PDE64_PRESENT | PDE64_RW | pdpt_addr
pdpt[0] = 7 | pd_addr; // PDE64_USER | PDE64_PRESENT | PDE64_RW | pd_addr
pd[0] = 7 | 0x80; // PDE64_USER | PDE64_PRESENT | PDE64_RW | PDE64_PS
这只是个例子,在hypervisor中不要有用户能访问到的页,在kernel中可以有。
(2)Syscall
有一个特殊寄存器可以允许syscall/sysenter指令执行: EFER (Extended Feature Enable Register),之前用它来进入long mode 模式。
// 进入long mode
sregs->efer = 0x500; // EFER_LME | EFER_LMA
LME和LMA表示Long Mode Enable和Long Mode Active。
// 允许syscall
sregs->efer |= 0x1; // EFER_SCE
同时需要在kernel里(而非hypervisor)注册syscall处理函数,告诉CPU遇到系统调用时应该跳转到哪里。注册syscall处理器需设置寄存器 MSR (Model Specific Registers),在hypervisor中通过ioctl和vcpufd获取和设置MSR,在kernel中使用指令rdmsr和wrmsr。
// 注册syscall处理函数
lea rdi, [rip+syscall_handler]
call set_handler
syscall_handler:
// handle syscalls!
set_handler:
mov eax, edi
mov rdx, rdi
shr rdx, 32
/* input of msr is edx:eax */
mov ecx, 0xc0000082 /* MSR_LSTAR, Long Syscall TARget */
wrmsr
ret
0xc0000082表示MSR的下标,可以在Linux source code中找到定义。设置完成后,可以调用syscall指令,程序将跳转到注册的处理函数,syscall指令不仅修改rip,也会把rcx设置成返回地址,把r11设置为rflags。还会改变两个段寄存器cs和ss。
register_syscall
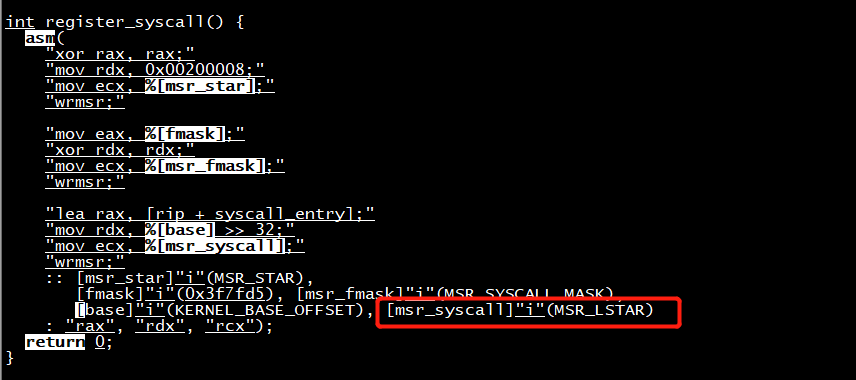
(3)内核与用户切换
通过MSR为内核与用户注册cs选择器。SYSRET和SYSCALL描述了sysret和syscall的细节,从sysret伪代码可以看出cs和ss设置了哪些属性。
CS.Selector ← IA32_STAR[63:48]+16;
CS.Selector ← CS.Selector OR 3; /* RPL forced to 3 */
/* Set rest of CS to a fixed value */
CS.Base ← 0; /* Flat segment */
CS.Limit ← FFFFFH; /* With 4-KByte granularity, implies a 4-GByte limit */
CS.Type ← 11; /* Execute/read code, accessed */
CS.S ← 1;
CS.DPL ← 3;
CS.P ← 1;
CS.L ← 1;
CS.G ← 1; /* 4-KByte granularity */
CPL ← 3;
SS.Selector ← (IA32_STAR[63:48]+8) OR 3; /* RPL forced to 3 */
/* Set rest of SS to a fixed value */
SS.Base ← 0; /* Flat segment */
SS.Limit ← FFFFFH; /* With 4-KByte granularity, implies a 4-GByte limit */
SS.Type ← 3; /* Read/write data, accessed */
SS.S ← 1;
SS.DPL ← 3;
SS.P ← 1;
SS.B ← 1; /* 32-bit stack segment*/
SS.G ← 1; /* 4-KByte granularity */
通过MSR为内核和用户注册cs的值:
xor rax, rax
mov rdx, 0x00200008
mov ecx, 0xc0000081 /* MSR_STAR */
wrmsr
最后设置flags掩码:
mov eax, 0x3f7fd5
xor rdx, rdx
mov ecx, 0xc0000084 /* MSR_SYSCALL_MASK */
wrmsr
掩码0x3f7fd5很重要,当触发syscall时,CPU会做如下操作:
rcx = rip;
r11 = rflags;
rflags &= ~SYSCALL_MASK;
若掩码没有设置正确,内核将继承用户模式下设置的rflags,会引发安全问题。
注册的完整代码如下:
register_syscall:
xor rax, rax
mov rdx, 0x00200008
mov ecx, 0xc0000081 /* MSR_STAR */
wrmsr
mov eax, 0x3f7fd5
xor rdx, rdx
mov ecx, 0xc0000084 /* MSR_SYSCALL_MASK */
wrmsr
lea rdi, [rip + syscall_handler]
mov eax, edi
mov rdx, rdi
shr rdx, 32
mov ecx, 0xc0000082 /* MSR_LSTAR */
wrmsr
接下来就能在用户模式下安全的使用syscall指令。
实现syscall_handler如下:
.globl syscall_handler, kernel_stack
.extern do_handle_syscall
.intel_syntax noprefix
kernel_stack: .quad 0 /* initialize it before the first time switching into user-mode */
user_stack: .quad 0
syscall_handler:
mov [rip + user_stack], rsp
mov rsp, [rip + kernel_stack]
/* save non-callee-saved registers */
push rdi
push rsi
push rdx
push rcx
push r8
push r9
push r10
push r11
/* the forth argument */
mov rcx, r10
call do_handle_syscall
pop r11
pop r10
pop r9
pop r8
pop rcx
pop rdx
pop rsi
pop rdi
mov rsp, [rip + user_stack]
.byte 0x48 /* REX.W prefix, to indicate sysret is a 64-bit instruction */
sysret
注意,必须正确push和pop 非调用者保存的寄存器,syscall/sysret不会修改栈指针rsp,我们需要手动处理。
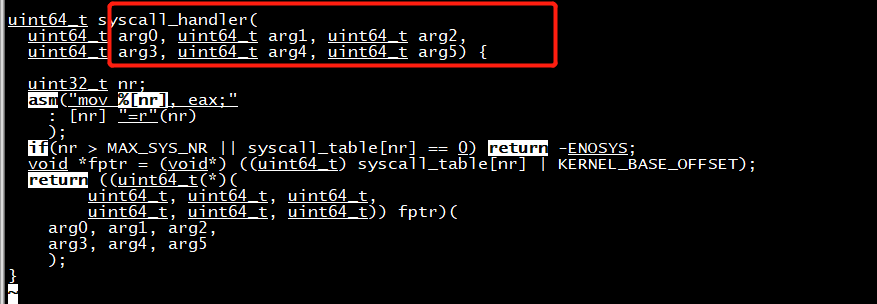
调用 syscall_handler

2.Hypercall
内核需要与hypervisor进行通信,我的内核使用了out/in指令作为hypercall,用out指令向stdout打印字节,其实还能进行拓展。
in/out指令包含两个参数,16-bit dx和32-bit eax,用dx来表示hypercall类型,eax表示参数。例如以下hypercall:
#define HP_NR_MARK 0x8000
#define NR_HP_open (HP_NR_MARK | 0)
#define NR_HP_read (HP_NR_MARK | 1)
#define NR_HP_write (HP_NR_MARK | 2)
#define NR_HP_close (HP_NR_MARK | 3)
#define NR_HP_lseek (HP_NR_MARK | 4)
#define NR_HP_exit (HP_NR_MARK | 5)
#define NR_HP_panic (HP_NR_MARK | 0x7fff)
接着修改hypervisor,当遇到KVM_EXIT_IO时不要只打印字节。
while (1) {
ioctl(vm->vcpufd, KVM_RUN, NULL);
switch (vm->run->exit_reason) {
/* other cases omitted */
case KVM_EXIT_IO:
// putchar(*(((char *)vm->run) + vm->run->io.data_offset));
if(vm->run->io.port & HP_NR_MARK) {
switch(vm->run->io.port) {
case NR_HP_open: hp_handle_open(vm); break;
/* other cases omitted */
default: errx(1, "Invalid hypercall");
}
else errx(1, "Unhandled I/O port: 0x%x", vm->run->io.port);
break;
}
}
以open调用的实现为例,在hypervisor中实现open syscall(本例缺少安全性检查):
/* hypervisor/hypercall.c */
static void hp_handle_open(VM *vm) {
static int ret = 0;
if(vm->run->io.direction == KVM_EXIT_IO_OUT) { // out instruction
uint32_t offset = *(uint32_t*)((uint8_t*)vm->run + vm->run->io.data_offset);
const char *filename = (char*) vm->mem + offset;
MAY_INIT_FD_MAP(); // initialize fd_map if it's not initialized
int min_fd;
for(min_fd = 0; min_fd <= MAX_FD; min_fd++)
if(fd_map[min_fd].opening == 0) break;
if(min_fd > MAX_FD) ret = -ENFILE;
else {
int fd = open(filename, O_RDONLY, 0);
if(fd < 0) ret = -errno;
else {
fd_map[min_fd].real_fd = fd;
fd_map[min_fd].opening = 1;
ret = min_fd;
}
}
} else { // in instruction
*(uint32_t*)((uint8_t*)vm->run + vm->run->io.data_offset) = ret;
}
}
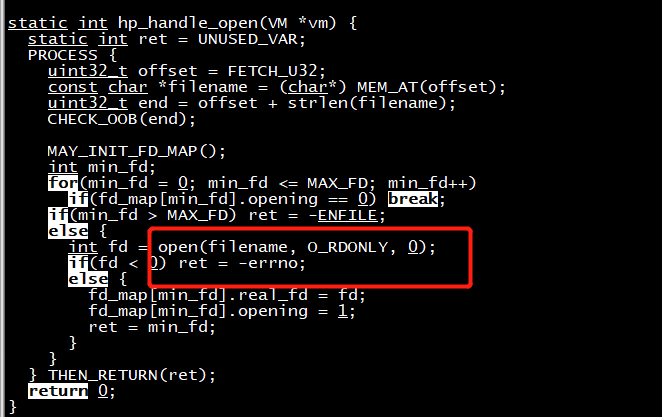
在内核中,我们触发open hypercall:
/* kernel/hypercalls/hp_open.c */
int hp_open(uint32_t filename_paddr) {
int ret = 0;
asm(
"mov dx, %[port];" /* hypercall number */
"mov eax, %[data];"
"out dx, eax;" /* trigger hypervisor to handle the hypercall */
"in eax, dx;" /* get return value of the hypercall */
"mov %[ret], eax;"
: [ret] "=r"(ret)
: [port] "r"(NR_HP_open), [data] "r"(filename_paddr)
: "rax", "rdx"
);
return ret;
}
root@cloud:~/onlyGvisor/kvm-kernel-example# grep hp_open -rn * kernel/hypercalls/hp_open.h:6:int hp_open(uint64_t paddr); kernel/hypercalls/hp_open.c:1:#include <hypercalls/hp_open.h> kernel/hypercalls/hp_open.c:4:int hp_open(uint64_t paddr) { kernel/kernel_main.c:1:#include <hypercalls/hp_open.h> kernel/syscalls/sys_open.c:1:#include <hypercalls/hp_open.h> kernel/syscalls/sys_open.c:12: int fd = hp_open(physical(dst));
sys_open --> hp_open --> hypercall
kernel/hypercalls/hp_open.c
#include <hypercalls/hp_open.h> #include <mm/translate.h> int hp_open(uint64_t paddr) { return hypercall(NR_HP_open, (uint32_t) paddr); }
kernel/syscalls/sys_open.c
int sys_open(const char *path) { if(!access_string_ok(path)) return -EFAULT; void *dst = copy_str_from_user(path); if(dst == 0) return -ENOMEM; int fd = hp_open(physical(dst)); kfree(dst); return fd; }
#include <hypercalls/hypercall.h> int hypercall(uint16_t port, uint32_t data) { int ret = 0; asm( "mov dx, %[port];" "mov eax, %[data];" "out dx, eax;" "in eax, dx;" "mov %[ret], eax;" : [ret] "=r"(ret) : [port] "r"(port), [data] "r"(data) : "rax", "rdx" ); return ret; }
调用sys_open
3.最后:
现在已经弄明白如何在KVM下实现一个简单的内核了,有些细节还需要讨论。
execve:本内核能执行简单的ELF,可以参考linux/fs/binfmt_elf.c#load_elf_binary来了解elf的加载过程。
memory allocator:如果内核需要malloc/free,可以自己实现一个内存分配器。
paging:内核需要处理用户模式的mmap请求,所以你需要在运行时修改页表。注意不要把内核地址和用户地址弄混。
permission checking:所有的用户参数需要仔细检查,本文的项目已经实现了检测方法,见kernel/mm/uaccess.c。若不检查用户参数,可能会导致用户模式下对内核空间的任意读写安全性问题。
总结一下,本文介绍了如何实现一个基于KVM的hypervisor和一个简单的linux内核。
4.KVM安装
# 环境:vmware fusion,ubuntu16.04/ubuntu18.04。先关闭客户机 -> 处理器与内存 -> Intel VT-x
$ sudo apt install qemu-kvm
# 非root时,需赋予用户权限
$ sudo usermod -a -G kvm `whoami`
# 如果总是 'open(/dev/kvm): Permission denied', 可直接chmod
$ sudo chmod 777 /dev/kvm
参考:
- (1)介绍和安装
- (2)CPU 和 内存虚拟化
- (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton)
- (4)I/O PCI/PCIe设备直接分配和 SR-IOV
- (5)libvirt 介绍
- (6)Nova 通过 libvirt 管理 QEMU/KVM 虚机
- (7)快照 (snapshot)
- (8)迁移 (migration)
https://david942j.blogspot.com/2018/10/note-learning-kvm-implement-your-own.html