如何优化 memcpy 函数
Linux 内核用到了许多方式来加强性能以及稳定性,本文探讨的 memcpy 的汇编实现方式就是其中的一种,memcpy 的性能是否强大,拷贝延迟是否足够低都直接影响着整个系统性能。通过对拷贝函数的理解可以加深对整个系统设计的一个理解,同时提升自身技术实力。
罗马不是一天建设而成的,Linux 内核的拷贝函数也不是一开始就是那么优秀,在 3.14 之前(具体多少版本忘记了),Linux 尚且没有完善对 ARM64 架构的支持,系统的内存拷贝函数就是一个简单的 c 语言版本,也就是目前内核中的通用拷贝函数。
#ifndef __HAVE_ARCH_MEMCPY /** * memcpy - Copy one area of memory to another * @dest: Where to copy to * @src: Where to copy from * @count: The size of the area. * * You should not use this function to access IO space, use memcpy_toio() * or memcpy_fromio() instead. */ void *memcpy(void *dest, const void *src, size_t count) { char *tmp = dest; const char *s = src; while (count--) *tmp++ = *s++; return dest; } EXPORT_SYMBOL(memcpy); #endif
在没有定义 __HAVE_ARCH_MEMCPY 之前,内核就会采用最简单的逐字节拷贝,我相信一个刚入学的大学生也能写得出一个这样的代码,完全不需要考虑对齐,不需要考虑性能等等,就是这么直白,这么暴力的拷贝数据。
当然,我们不可能真的采用这样的代码来运转系统,不然再好的硬件能力也会被粗糙的代码毁掉,那么不如一起来做一个简单的优化?
现代计算机已经不再是 20 世纪时代的 16 位机甚至更早的 8 位机,一个寄存器宽度已经达到了惊人的 64 位(32 位机器也会在这两年被主流淘汰掉,大部分的操作系统已经不再提供 32 位支持),既然如此,何不将这个一个特性利用起来。
void *memcpy(void *d, void *s, size_t count) { int i; for (i = 0; i < count / sizeof(int64_t); i++) { (int64_t *)d++ = (int64_t *)s++; } return d; }
这样是不是舒服多了(代码没有考虑 count 不能被整除的情况,仅仅做一个演示),一条指令下去就可以完成 8 个字节的拷贝,这样整个循环体直接缩减为原来的 1/8,效率是上一版本的 8 倍之多。那么仅此而已吗?
不然,在 CPU 的指令上,跳转指令的耗时是很高的,软件应该尽可能的减少 CPU 跳转,上面的代码没做完一次 8 字节的拷贝之后就需要完成一个跳转,那么是不是可以减少一些跳转呢?当然,那就是循环展开:
void *memcpy(void *d, void *s, size_t count) { int i; for (i = 0; i < count / sizeof(int) / 4; i++) { (int *)d++ = (int *)s++; (int *)d++ = (int *)s++; (int *)d++ = (int *)s++; (int *)d++ = (int *)s++; } return d; }
循环展开也做了,有没有其他的方式可以继续优化呢?当然有,尽管 ARM64 的机器指令宽度为 64 位,最多一次能存储 8 个字节,但是他还有更为高级的寄存器,那就是向量寄存器,通过 NEON 指令处理,可以一次性搬移 128 位数据,也就是 16个字节,这样效率又提升一倍,通过代码演示一下:
#include <arm_neon.h> void *memcpy_128(void *dest, void *src, size_t count) { int i; unsigned long *s = (unsigned long *)src; unsigned long *d = (unsigned long *)dest; for (i = 0; i < count / 64; i++) { vst1q_u64(&d[0], vld1q_u64(&s[0])); vst1q_u64(&d[2], vld1q_u64(&s[2])); vst1q_u64(&d[4], vld1q_u64(&s[4])); vst1q_u64(&d[6], vld1q_u64(&s[6])); d += 8; s += 8; } return dest; }
上面的代码通过 NEON 改造之后,一次循环体可以处理 64 字节的数据,大大的加快了拷贝效率。还有没有更好的优化方式?当然是有的,那就是用汇编来写1,结合上面提到的所有的优化方式,以汇编的形式实现,可以获得最佳性能。我们接下来具体分析目前 Linux 内核下的 ARM64 架构 memcpy 的实现方式。
当前 ARM64 构架的实现方式
熟悉 Linux 内核的都知道,Linus 为了让 kernel 跑得更快,更健壮,代码能够重复利用就一定重复利用,不但可以减少生成的二进制 bin 文件大小,而且能减少维护成本,arch/arm64/lib/memcpy.S 就是这样的例子。
ENTRY(__memcpy) ENTRY(memcpy) #include "copy_template.S" ret ENDPIPROC(memcpy) ENDPROC(__memcpy)
memcpy.S 直接 include 了一个 copy_template.S 的文件,其实就是直接贴上了这样的一份代码,这个 copy_template.S 不仅仅只是在 memcpy.S 中用到,在其他的类似 copy_to_user.S 和 copy_from_user.S 中也被包含。
既然如此,我们只需要深入分析 copy_template.S 即可。这里不贴代码进行逐行分析,因为也没有什么好分析的,当你完全理解设计思想,再对着代码你主需要理解每一行的汇编是什么意思即可。

从上图可以看出,拷贝算法将数据分为 3 个大的部分,第一个部分就是不对齐部分,通过对传入的 src 地址进行分析,首先处理掉不能被 16 整除的前面不对齐数据,然后处理对齐的数据。
对齐的数据以 128 为一个界限,每一个 128 字节数据都能通过大块拷贝直接计算完毕,一直循环到最后剩余的尾部 128 以下的字节。
整体设计逻辑流程图如下:
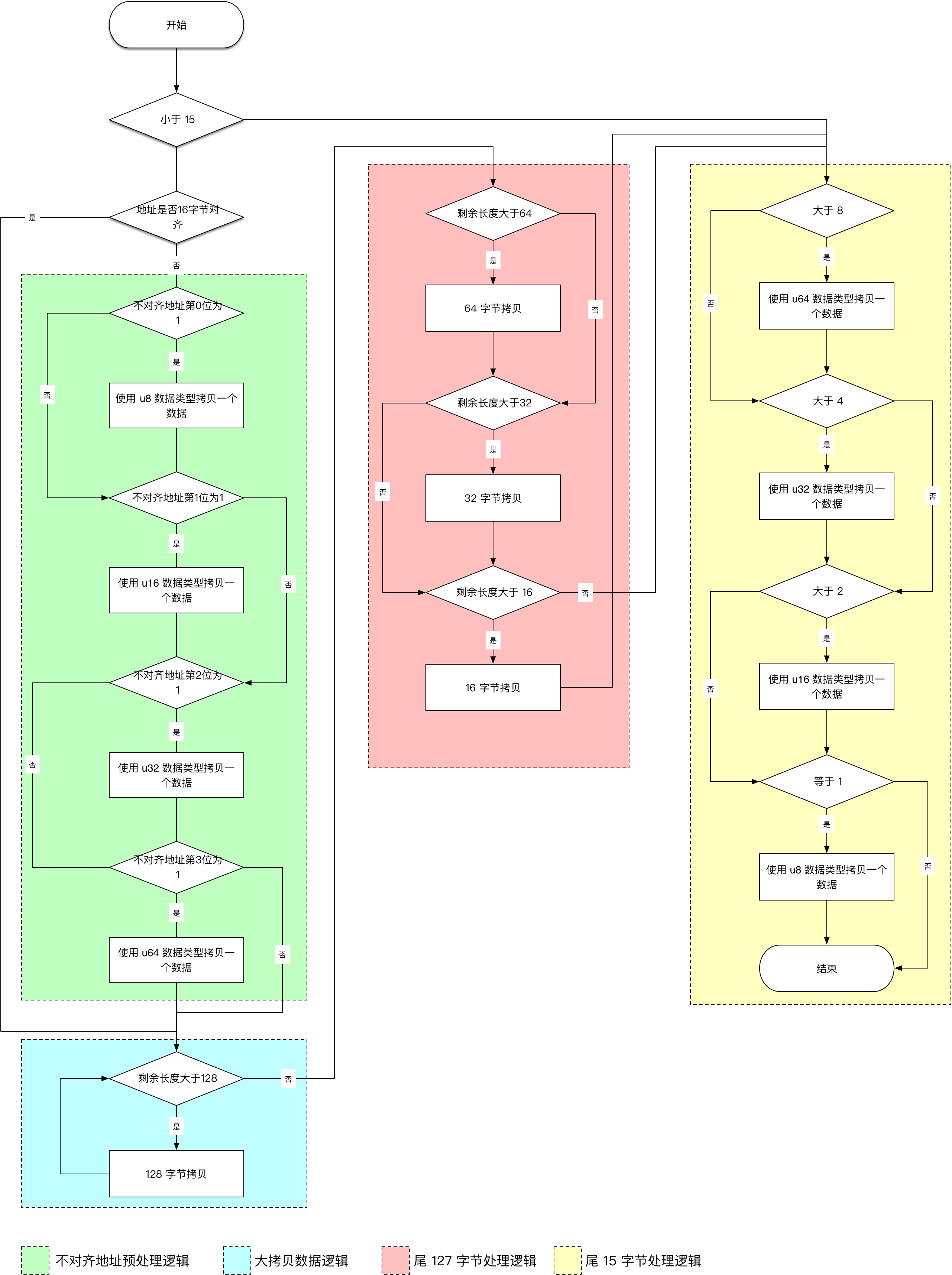
大体思想很简单,那就是首先处理不对齐,之后处理大拷贝部分,然后细分到最小的各个部分,通过利用寄存器宽度来减少拷贝次数。
比如最后的 120 个字节会被分为:120 = 64 + 32 + 16 + 8,这样处理可以得到最佳的性能。
memcpy 拷贝性能测试
编写一个新的算法当然需要对他进行性能测试,那么该如何做性能测试呢?当然是需要编写一个内核驱动,可以随意百度一个 HelloWorld 的模块,参考其逻辑编写一个简单的模块,在 module_init 的函数中写入这样的一段测试代码,等模块加载完毕之后,会附带打印当前输入的测试的 memcpy 算法的性能。
typedef void *(*memcpy_t)(void *, void *, size_t); void memcpy_speed_test(memcpy_t __memcpy, void *b1, void *b2) { int speed; unsigned long now, j; int i, count, max; preempt_disable(); max = 0; for (i = 0; i < 5; i++) { j = jiffies; count = 0; while ((now = jiffies) == j) cpu_relax(); while (time_before(jiffies, now + 1)) { mb(); /* prevent loop optimzation */ __memcpy(bench_size, b1, b2); mb(); count++; mb(); } if (count > max) max = count; } preempt_enable(); speed = max * (HZ * bench_size / 1024); printk(KERN_INFO "memcpy_test: %5d.%03d MB/sec\n", speed / 1000, speed % 1000); }