MySQL 索引
Index 索引
数据库索引是一种可以有效提高数据查找速度但是会额外增加写入数据时和存储空间的开销的数据结构。
索引不用通过查找数据表的每一行,就可以快速定位到数据。
索引的可以使用一个或者多个数据列columns来创建。
Clustered 聚集
聚集索引,也叫聚簇索引,EN:Clustered Index
聚集索引将数据块更改为与索引匹配的特定顺序,从而使行数据按顺序存储。因此一个数据表中只能创建有一个聚集索引。聚集索引可以极大地提高检索的总体速度,但通常只有在数据按与聚集索引相同或相反的顺序访问时,或者在选择了一系列项的情况下。
由于物理记录在磁盘按顺序排列,那下一行数据就会排在该数据之前或之后,所以只需要很少的读取数据块操作。因此,聚集索引的主要特征是根据指向物理数据行的索引块对物理数据行进行排序。
有的数据库是将数据和索引分离开,有的数据库是将数据和索引 放在一起
Non-clustered 非聚集
数据以任意顺序出现,但逻辑顺序由索引指定。在非聚集索引下,数据行就可以随意在表中分布。而非聚集索引的叶子就包含了指向记录的指针。
一个数据表上面可以创建多个非聚集索引。
MySQL
MySQL支持多种db engine。MyISAM,InnoDB是应用的最广的2个。
MyISAM
-
不支持完整性约束
-
不支持事务
-
查询时锁整表,可能会产生大量的查询积压
-
不提供数据完整性,由于外界因素导致的数据错误,需要对表全部修复或者重建索引
-
支持全文索引
-
不支持ACID
InnoDB
- 支持完整性约束
- 支持事务
- 查询时只会锁查询相关的行
- 发生崩溃,可以通过log恢复
- 5.6.4之前不支持全文索引
- 支持ACID
Explain plan
id
包含一组数字,表示查询中执行select子句或操作表的顺序 id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行
select_type
- SIMPLE:查询中不包含子查询或者UNION
- PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY
- SUBQUERY:在SELECT或WHERE列表中包含了子查询,该子查询被标记为SUBQUERY
- DERIVED:在FROM列表中包含的子查询被标记为:DERIVED(衍生)
- UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在 FROM子句的子查询中,外层SELECT将被标记为:DERIVED
type 列 (性能从高到低)
const: 表中值有且只有一行匹配,或者利用where 查询某个常量的值,主键或唯一索引查询是效率最高的方式
system:system是const类型的特例,当查询的表只有一行的情况下, 使用system
ref: 非唯一索引查找,返回匹配某个单独值的所有行
eq_ref: 常出现在join查询,唯一索引或主键索引查找,对每个索引键,表中只有一条记录与之匹配
ref_or_null:类似于ref 增加了null值的查询
index_merge: 索引合并
range: 索引范围素描(between , > , <)
index: 索引扫描
all: 全表扫描,性能最低
possible_keys:
可能会被使用到的索引
key:
实际被使用到的索引
key_len:
实际使用索引的最大长度 (字节)
ref列
列出哪些列被用于索引查找
rows列
预估扫描行数
extra列
using index: 使用了覆盖索引(直接通过索引获取数据,不访问表)
using where: 表示MySQL服务器在存储引擎收到记录后进行“后过滤”(Post-filter),如果查询未能使用索引,Using where的作用只是提醒我们MySQL将用where子句来过滤结果集。这个一般发生在MySQL服务器,而不是存储引擎层。一般发生在不能走索引扫描的情况下或者走索引扫描,但是有些查询条件不在索引当中的情况下。
Using Index Condition: 在MySQL 5.6版本后加入的新特性(Index Condition Pushdown);会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
using filesort: MySQL中无法利用索引完成的排序操作称为“文件排序”,常见使用order by 或者 group by 查找
using temporary: 使用了临时表,表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询
索引使用
索引之所以能提高查询速度,主要还是依赖于索引特殊的结构B+Tree。
正是根据这个结构,所以查询时,DB会对查询条件做优化,来判断是否能够使用索引,其条件依据的就是最左前缀匹配
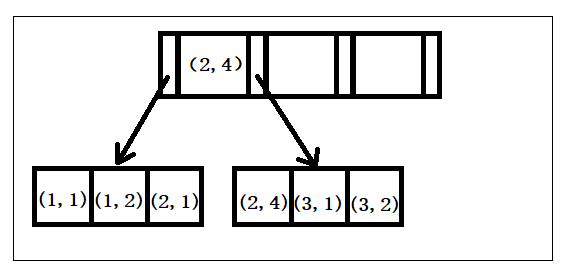
这是一个(A,B)的索引,很明显可以看出结构是按照A的顺序排列,然后再按照B的顺序排列。所以如果在查询的时候只查询B的话,是无法使用这个索引的。
MYSQL版本
10.2.13-MariaDB
因为explain在不同的版本上可能出现的细节不一样,所以具体的需要在各自版本上去验证。

CREATE TABLE `T_Score2` (
`Id` bigint(20) NOT NULL AUTO_INCREMENT,
`StuNo` varchar(255) COLLATE utf8_unicode_ci DEFAULT '',
`A` int(255) DEFAULT 0,
`B` int(255) DEFAULT 0,
`C` int(255) DEFAULT 0,
`D` int(255) DEFAULT 0,
PRIMARY KEY (`Id`),
KEY `ind_A_B_C` (`A`,`B`,`C`) USING BTREE,
KEY `ind_I_A_B` (`Id`,`A`,`B`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
表中建了2个KEY,PK 就不说了。
全值匹配查询
这种属于把所有col都用了,(A,B,C)顺序就算乱了,也可以。

最左匹配
当使用=,满足左匹配的都可以应用索引
col A

col A B

此场景就是不满足左匹配的情况,进入全表扫描
col B

如果出现>,<,>=,<=,理论上很多地方都说会使用索引,但是看来不同的版本下有的场景下也不一定。
可能使用索引,但是最后还是全表扫描

进入range

进入range


如果出现了is not null is null是不会用索引的
如果通配符%不出现在开头,则可以用到索引
索引使用的场景太多,具体都在explain里面,有兴趣可以使用工具。我们只是讨论在大多数场景下,有哪些条件会使用到索引。
Tag
MYSQL DataBase Index