背景

启动hive时,可以看到2.0以后的版本,将要弃用mr引擎,官方建议使用spark,tez等引擎。
spark同时支持批式流式处理,可以减少学习成本。所以选用了spark作为执行引擎。
hive on spark
SET hive.execution.engine = spark;
参数优化
使用hive on spark 默认只用2个container。任务处理时间过长,或者报oom,或code2可以尝试修改如下的参数。
如下:
set mapreduce.map.memory.mb = 8192; set mapreduce.reduce.memory.mb = 8192;
释放session资源
默认使用spark引擎,session资源是不会释放的。
1. 使用hive -f 执行sql文件
需要在sql文件的最后一行,添加
quit
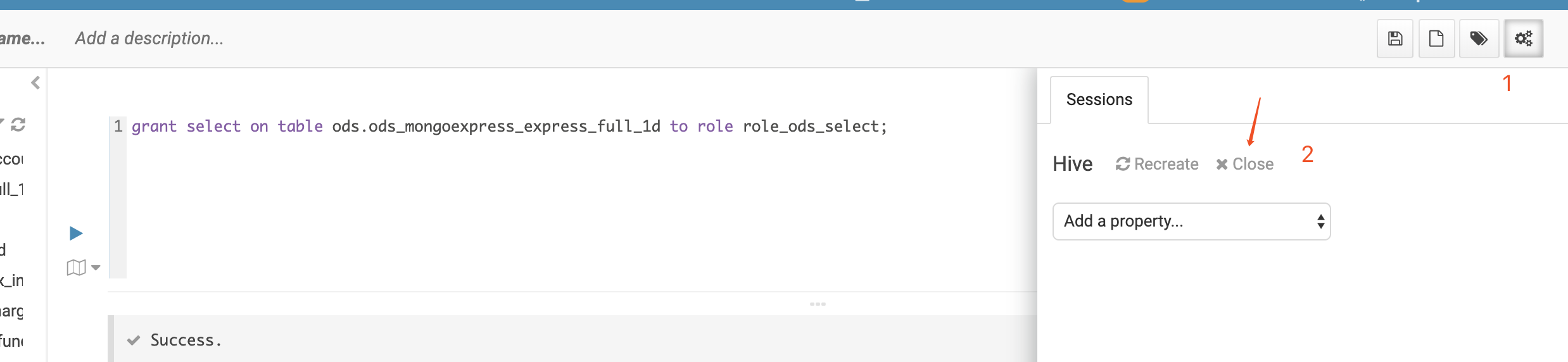
2. 在hue界面
点击会话右面的设置,可以close资源