使用分类数据和文本数据
通常情况下,我们主要处理两种类型的数据:分类数据和数值数据。
数值数据都是可以比较的,可以用等于,大于,小于等二进制操作符。
数值数据具有统计属性,这不适用其他类别。
分类数据表示一种可以测量是属性,通常成为等级。
布尔数据是分类数据与数值数据的一个补充,可以将类属特征编码成数值。
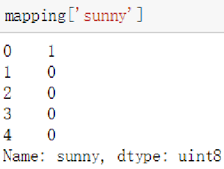
第一个例子是对天气划分的五个类属特征('sunny','cloudy','snowy','rainy','foggy')组成一维序列,对五个类属特征进行虚拟编码(get_dummies)也就是根据布尔数据进行的二值编码

将sunny的编码输出
还可以借助python中的Scikit-Learn库进行编码操作,Scikit-Learn是Python专门针对机器学习应用发展的一款开源框架。
功能:分类、回归、聚类、数据降维、模型选择和数据预处理等。
可以通过使用OneHotEncoder(独热编码)和LabelEncoder(标签编码)进行处理
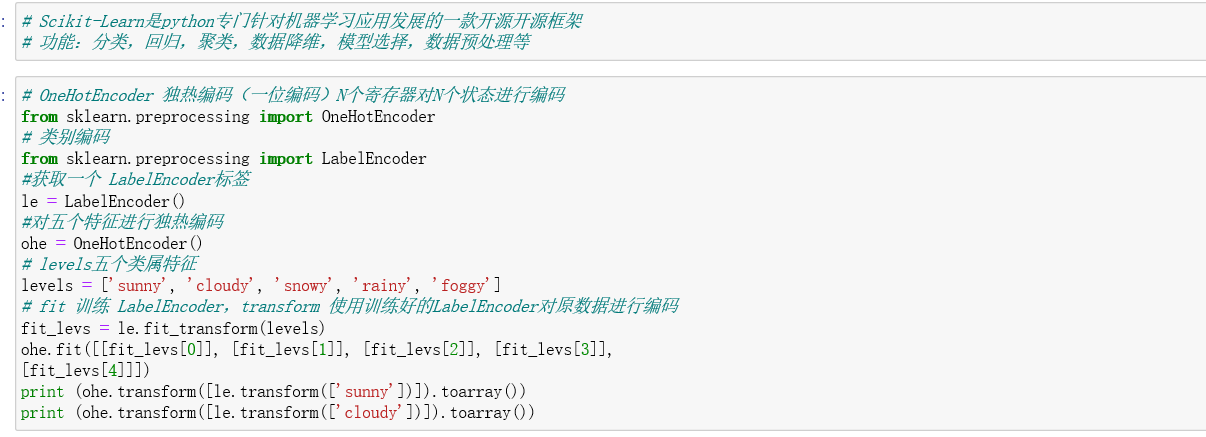
OneHotEncoder 独热编码 又称一位编码,即使用N位状态寄存器堆N个状态进行编码,每个状态有独立发寄存器位,且只有一位有效;
LabelEncoder 标签编码,将原文本类别转换成整形数值,这种情况下数值仍然是一个分类变量,对它排序没有意义。
特殊的数据类型——文本
处理文本最常用的方法是使用词袋——bag of words。就是把文本拆分成单词。
在这种方法中,每一个单词都变成了特征,文本就成了包含其自身特征非零元素的向量(如单词).
第一次运行会自动下载

查看文件地址:
查看文件标签:
查看文本数据:
处理文本最简单的方法是将数据集的主体转换成词语序列
次数统计
CountVectorizer
一个文本特征提取方法,对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。
将文本中的词语转换为词频矩阵,通过fit_transform函数计算各个词语出现的次数。
1187是样本数(文档数),25638特征数(数据集中单词数)
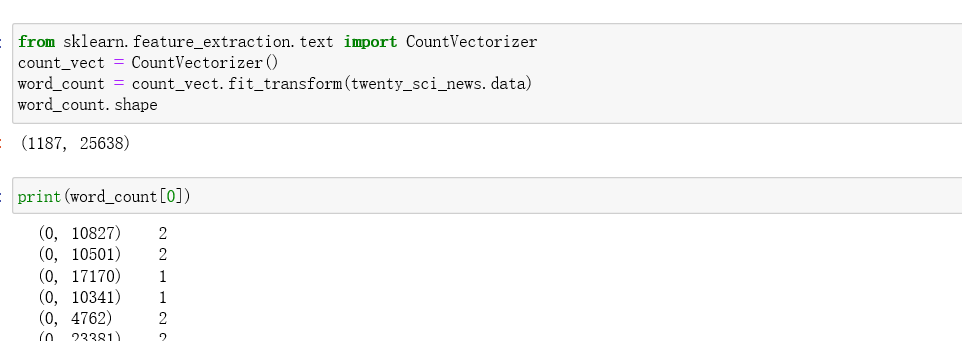
词频统计

TfidfVectorizer
可以把原始文本转化为tf-idf的特征矩阵,从而为后续的文本相似度计算,主题模型(如LSI),文本搜索排序等一系列应用奠定基础。

