ULMFiT 阅读笔记
概述
这篇文章从文本分类模型入手,主要提出了两点:一是预训练语言模型在大中小规模的数据集中都能提升分类效果,在小规模数据集中效果尤为显著。二是提出了多种预训练的调参方法,包括Discriminative Fine-tuning(分层微调。我自己取的名字,下同),Slanted triangular learning rates(斜三角学习率),Concat pooling(拼接池化),Gradual unfreezing(逐层解冻),双向语言模型等。
模型
本文以LSTM为基本单元设计了一个单向的语言模型,并将整个训练过程从预训练到最终训练分类器分为3个部分。
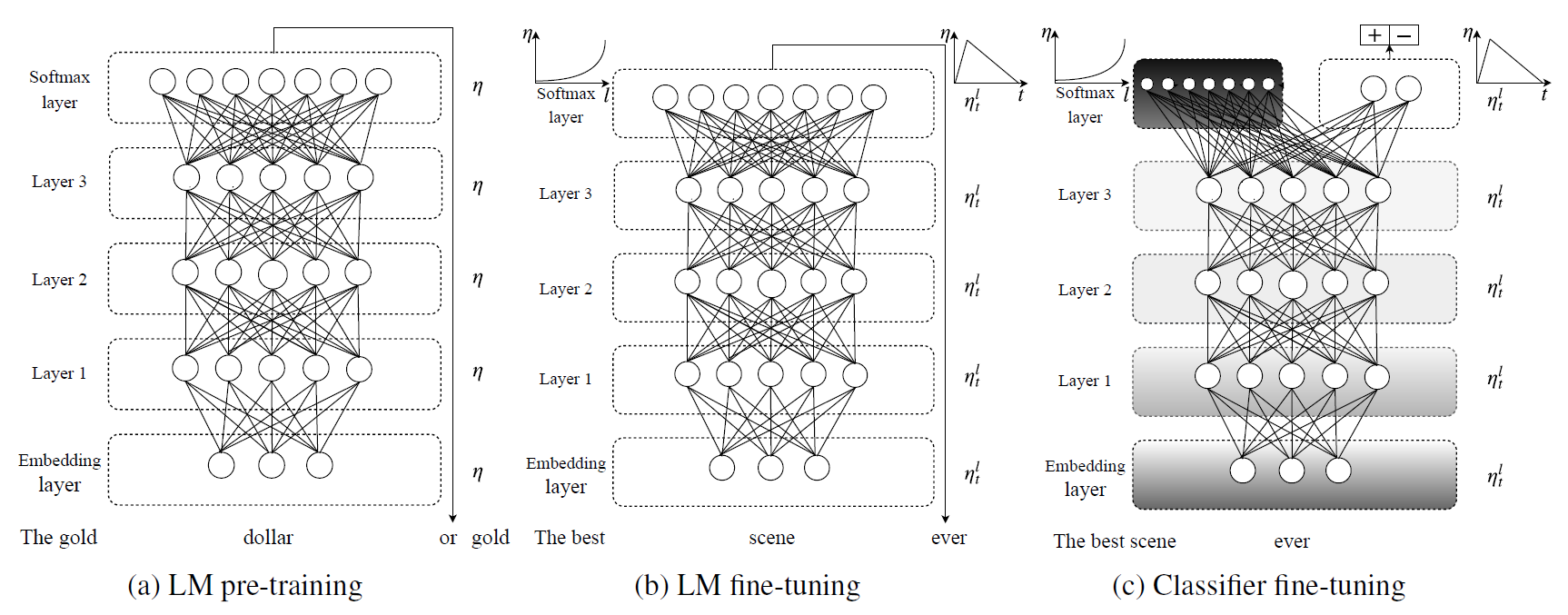
- 第一部分:语言模型预训练。使用Wikitext-103数据集训练语言模型。
- 第二部分:语言模型微调。使用分层微调和斜三角学习率,在目标任务的数据集上微调语言模型的参数,学习该任务的语言特征。
- 第三部分:固定语言模型的softmax层,将分类层加入到模型中,使用逐层解冻、分层微调、斜三角学习率等方法,在保留低层表示信息的情况下,对模型高层参数参数进行微调。
作者还尝试了双向语言模型,不过其本质是两个独立的单向模型,最后再进行拼接整合用于分类。
微调方法
分层微调
每一层使用不同的学习率。通过尝试,作者发现先确定顶层的学习率,其余层与层之间的学习率排列在一起构成一个等比数列,公比取1/2.6效果比较好。即n_l-1 = n_l/2.6。
斜三角学习率
先上图,0.01是设定好的学习率超参:
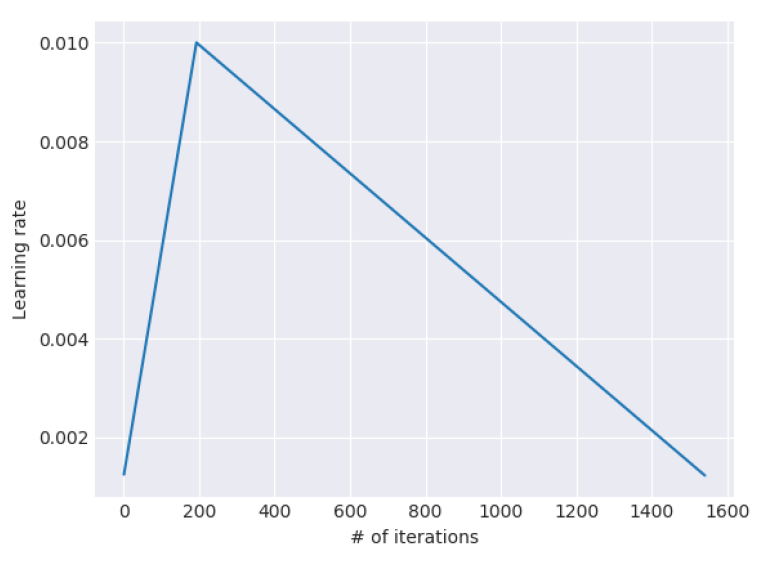
注意横坐标单位是迭代总次数。
上公式:

- T: 预设的总迭代轮数,等于epoch * 每个epoch中的batch数。我感觉可能要尝试一下初次训练在什么时候取得最优值,然后设置稍大一些,可能比较好。
- cut_frac: 学习率上升部分的iteration比例,一般10%。BERT官方代码中,warm up的这个比例也是10%。cut表示上升部分的迭代次数。
- 第二个公式p看起来复杂,我们代入3个点进去就知道了。t=0和t=cut代进去,得到p=0和p=1,表明学习率上升过程的线性变化,t=cut和p=0代进去,得到p=1和t=T,表明学习率下降过程的线性变化。
- ratio的目的是保证学习率不降为0。p->1时,n_t->n_max。这和n_t=p*n_max是等价的。p->0时,n_t->1/ratio,相当于将点(0,0)挪到了(0, 1/ratio),给学习率设置了一个下限,避免学习率变为0。当然,当迭代次数超过T以后,学习率还是可能变为0。
拼接池化
正常在使用单向LSTM进行分类任务时,都是将最后时刻的输出作为softmax的输入,然后进行分类。作者认为决定分类结果的关键词语可能出现在文本的任意位置,而输入文本有可能包含数百个词语,如果只考虑最后时刻的输出,信息可能丢失,因此作者设计了拼接池化。作者将每个时刻的输出放到一起,做了max-pooling和mean-pooling两种操作,得到两个向量,然后将这俩向量拼接到最后时刻的输出h_T后面,构成完整地特征向量,作为softmax层的输入用于分类
思考:为什么不使用attention机制呢?池化和attention相比有何优劣
逐层解冻
作者认为同时微调所有层可能为导致模型遗忘了预训练时学到的参数,从而跳出最优解(我们假定预训练时学到的参数已经是全局最小值),最终困于局部极小值而无法回到预训练中学到的全局最小值。
作者先解冻最后一层,固定低层参数不变,然后开始训练。每一轮次训练结束后,由高到低解冻一层参数,直到所有层的参数都被微调并且模型收敛。
该方法和2017年提出的chain-thaw很像,区别是chain-thaw每次只训练一层,作者每次多训练一层。
实验和分析
作者使用了6个数据集进行尝试:
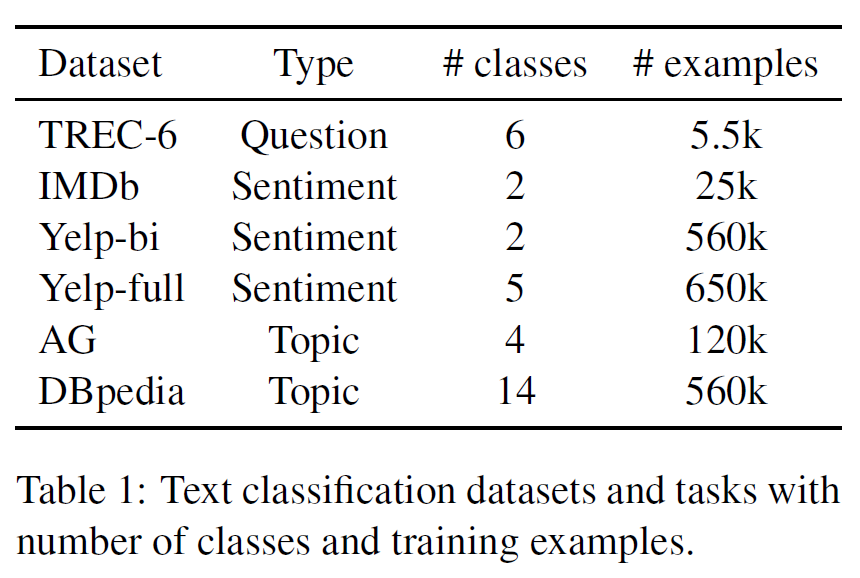
重点关注TREC-6、IMDb和AG,他们分别代表不同类型、不同数据量级的数据集。
-
实验1:验证ULMFiT模型有效性。在所有模型中达到了SOTA,越大的数据集效果越明显。
-
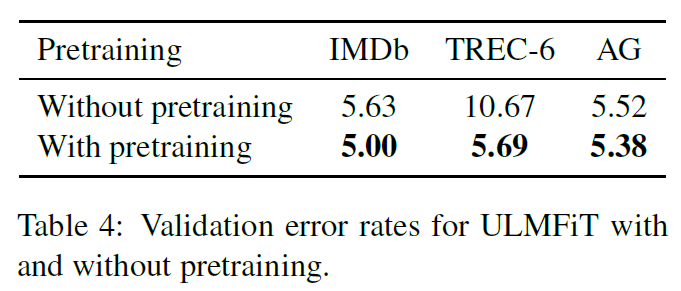
实验2:验证相同模型下,预训练带来的效果提升。越小的数据集效果越明显。
-
实验3:LM fine-tuning过程中分层微调和斜三角学习率的效果。STLR的效果十分明显。
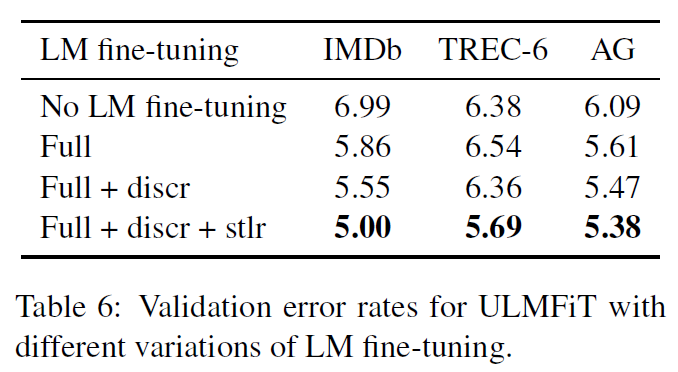
-
实验4:Classifier fine-tuning过程中分层微调、斜三角学习率和逐层解冻的效果。对比有chain-thaw和学习率余弦(cos)衰减。总的来说STLR表现确实好。

思考: STLR和warm-up的异同?