
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈、交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代。在进行产品研发的过程中,技术小哥哥们能文能武,不断提升产品性能和体验的同时,也把这些提升和优化过程记录下来,现录入“袋鼠云研发手记”专栏中,以和业内童鞋们分享交流。
下为“袋鼠云研发手记”专栏第二期,本期作者为袋鼠云数栈引擎团队。
袋鼠云数栈引擎团队
袋鼠云数栈引擎团队拥有多名专家级别,经验丰富的后端开发工程师,分别支撑公司大数栈产品线的不同子项目的开发需求,从项目中提取并开源了FlinkX(基于Flink的数据同步),Jlogstash(logstash 的java 版本实现),FlinkStreamSQL(扩展原生FlinkSQL,实现流与维表的join)多个项目。
在长期的项目实践与产品迭代过程中,团队成员在 Hadoop技术栈上不断深耕探索,积累了丰富的经验与最佳实践。
第二期
数栈·开源
Github上400+Star的「硬核」分布式同步工具FlinkX
FlinkX 已经开源在Github上目前已获400+Star,查看地址:https://github.com/DTStack/flinkx
1、袋鼠云为什么要自研数据同步工具?
袋鼠云作为一家数据智能公司,自研开发企业级一站式数据中台PaaS产品——数栈。
关于数栈
数栈具有8大产品模块
-
离线/实时开发套件
一站式大数据开发平台,帮助企业快速完全数据中台搭建
-
分析引擎
海量数据秒级查询,极速响应能力,帮助企业自由的数据探索
-
数据质量
对过程数据和结果数据进行质量校验,帮助企业及时发现数据质量问题
-
数据地图
可视化的数据资产中心,帮助企业全盘掌控数据资产情况和数据的来源去向
-
数据模型
使企业数据标准化,模型化,帮助企业实现数据管理规范化
-
数据API
快速生成数据API、统一管理API服务,帮助企业提高数据开放效率
-
Easy[V]
在线拖拉拽的方式快速搭建交互式数据可视化大屏,让数据价值看得见
-
EasyManager
全自动化,全生命周期的运维管家,提供安全稳定的数栈部署与监控服务
其中,「数据同步」是数栈开发套件中一个非常重要的功能,我们对数据同步工具有3点要求:
-
一是支持多种部署模式,比如测试单机部署,生产分布式部署。
-
二要基于yarn,mesos或者k8s做资源调度,提高资源利用率。
-
三要支持断点续传。因为在大数据量的传输场景下,由于网络出现抖动等原因,可能导致任务失败,那这个时候不可能重跑任务,这样太耗时了,需要从失败的点继续跑;
当时,市面上,并没有满足以上三点要求的数据同步工具。
2、为什么基于Flink?
Flink是新型的计算框架,支持多种部署方式local(单机),standalone模式,也可以基于yarn,mesos或者k8s做资源调度;并且flink提供了比较高级的API,我们能比较方便地扩展现有的API来满足我们自己的特殊需求;而且Flink提供了完整的状态管理体系(checkpoint),断点续传就是基于checkpoint机制来实现的。
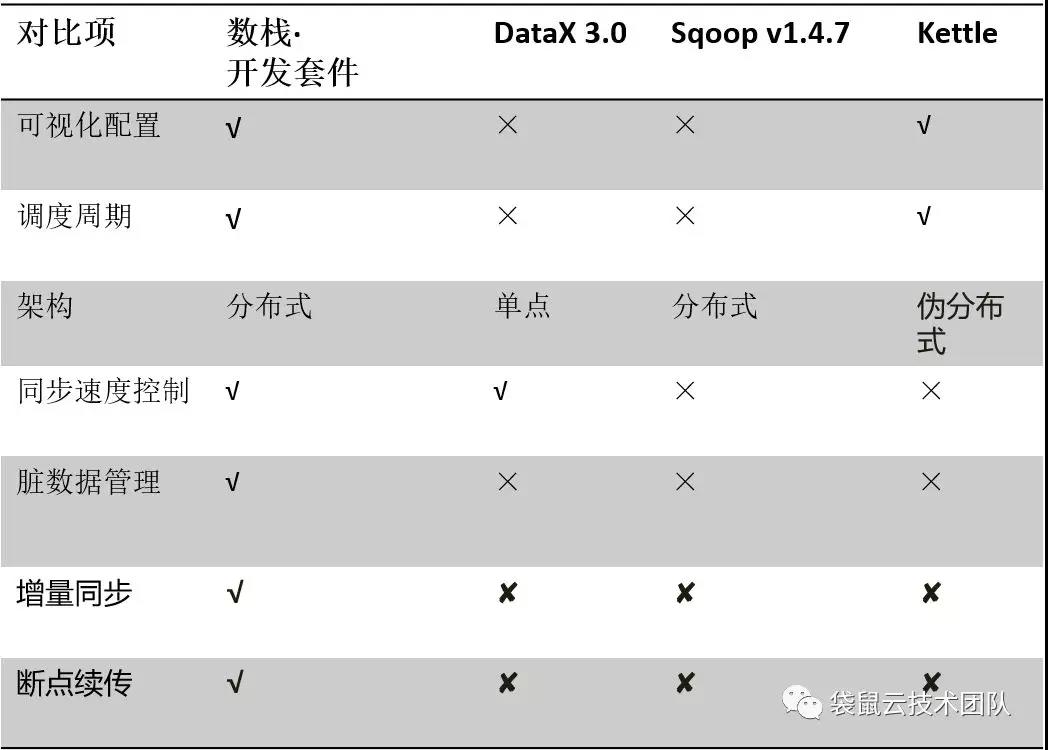
数据同步工具对比
3、FlinkX 概览
FlinkX是在袋鼠云内部广泛使用的一个基于Flink的异构数据源离线同步工具,用于在多种数据源(MySQL、Oracle、SqlServer、Ftp、Hdfs,HBase、Hive、Elasticsearch等)之间进行高效稳定的数据同步。
FlinkX简化了数据同步任务的开发过程,用户只需提供一份数据同步任务的配置,FlinkX会将配置转化为Flink任务,并自动提交到Flink集群上执行。
作为一个面向分布式数据流处理和批量数据处理的开源计算平台,Flink具有分布式、低延迟、高吞吐和高可靠的特性。

FlinkX实现了多种异构数据源之间高效的数据迁移
4、FlinkX的设计思路
2.1 插件式架构
FlinkX采用了一种插件式的架构:
-
不同的源数据库被抽象成不同的Reader插件;
-
不同的目标数据库被抽象成不同的Writer插件;
整个数据同步任务共有的处理逻辑被抽象在Template模块中,该模块根据数据同步任务配置加载对应的Reader和Writer插件,组装Flink任务,并提交到Flink集群执行;
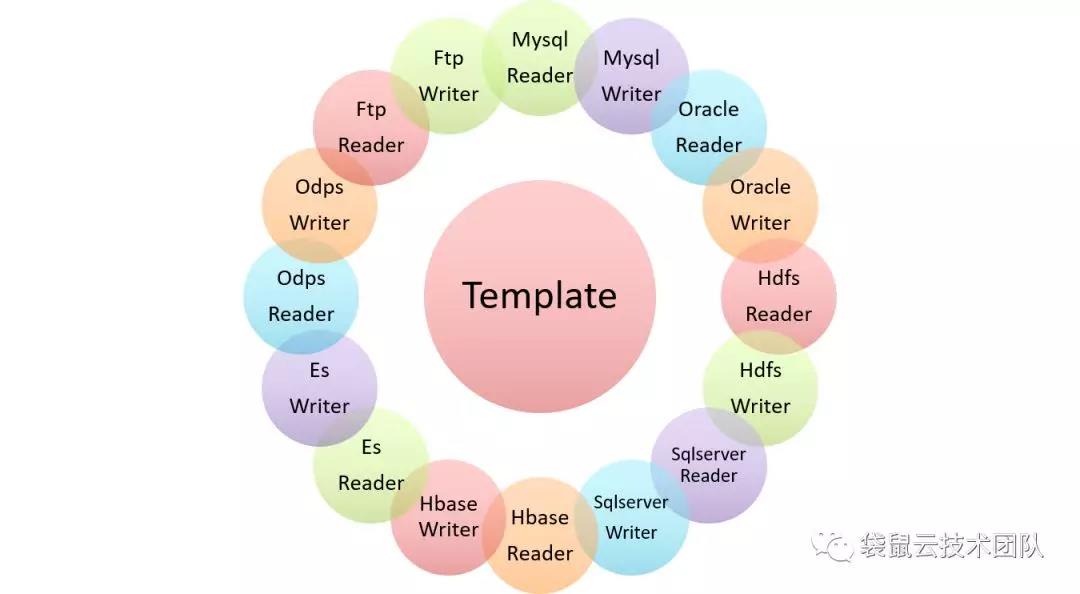
FlinkX支持任意数据源类型的数据同步工作
FlinkX框架可以支持任意数据源类型的数据同步工作。作为一个开放式系统,用户可以根据需要开发新的插件,以接入新的数据库类型。
2.2 Flink任务的自动组装
Template模块根据同步任务的配置信息加载源数据库和目的数据库对应的Reader插件和Writer插件;
Reader插件实现了InputFormat接口,从源数据库中获取DataStream对象;
Writer插件实现了OutputFormat接口,将目的数据库与DataStream对象相关联;
Template模块通过DataStream对象将Reader和Writer串接在一起,组装成一个Flink任务,并提交到Flink集群上执行。
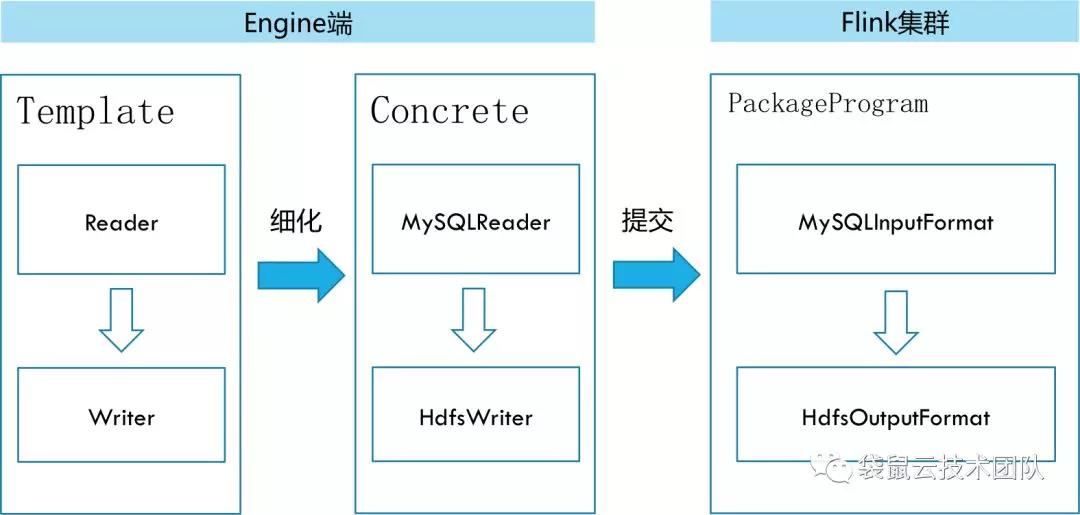
Flink任务的自动组装
5、FlinkX的优势
一、便于使用
用户只需要提供一份数据同步配置信息,无需编写程序,FlinkX会配置信息自动转换为Flink任务并提交到Flink集群执行。
二、性能优越
FlinkX会将数据同步任务提交到Flink集群中的执行,使得FlinkX天然具有Flink的性能优势,主要表现为分布式、低延迟、高吞吐和高可靠。
三、多运行模式
同普通的Flink任务一样,FlinkX支持local、standalone和yarn三种运行模式。
-
「local模式」就是在本地开启一个mini的Flink集群执行Flink任务,这种运行模式的好处是使用方便,不需要预先启动分布式集群,适用于测试和实验环境;缺点是由于单点执行,可靠性差,当数据量大时吞吐量受限;
-
「standalone模式」是指以独立部署的方式启动一个Flink集群,然后将提交Flink任务到该集群上执行;
-
「yarn模式」是指在yarn集群中部署Flink集群,然后将Flink任务提交到部署在yarn集群中的Flink集群上执行;standalone模式和yarn模式都是分布式地执行FlinkX,而yarn模式可以利用yarn的资源管理功能,因而成为部署FlinkX应用时的首选。
四、开放式可扩展
只要你愿意,你可以给任何类型的数据源开发Reader和Writer插件。
五、错误控制和脏数据管理
-
错误控制可以在数据同步配置信息中设置错误记录阈值、错误占比阈值,使得数据同步任务在出错时及时停止,避免系统资源的浪费。
-
脏数据管理可以将错误记录、错误原因、错误类型输出到Hive表中,便于日后的排查工作。
6、FlinkX在数栈产品中的应用
使用数栈的数据开发套件,用户可以通过界面向导可视化的创建一个数据同步任务,而FlinkX正是数据同步的底层执行引擎。

FlinkX在袋鼠云数栈产品中的应用