实验原理
Map、Reduce任务中Shuffle和排序的过程图如下:

流程分析:
1.Map端:
(1)每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
(2)在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
(3)当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:①尽量减少每次写入磁盘的数据量。②尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
(4)将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?
2.Reduce端:
(1)Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
(2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
(3)合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
熟悉MapReduce的人都知道:排序是MapReduce的天然特性!在数据达到reducer之前,MapReduce框架已经对这些数据按键排序了。但是在使用之前,首先需要了解它的默认排序规则。它是按照key值进行排序的,如果key为封装的int为IntWritable类型,那么MapReduce按照数字大小对key排序,如果Key为封装String的Text类型,那么MapReduce将按照数据字典顺序对字符排序。
了解了这个细节,我们就知道应该使用封装int的Intwritable型数据结构了,也就是在map这里,将读入的数据中要排序的字段转化为Intwritable型,然后作为key值输出(不排序的字段作为value)。reduce阶段拿到<key,value-list>之后,将输入的key作为的输出key,并根据value-list中的元素的个数决定输出的次数。
实验步骤
1.在Linux中开启Hadoop
start-all.sh
2.在Linux本地新建/data/mapreduce3目录。
mkdir -p /data/mapreduce3
3.下载hadoop2lib,解压到mapreduce文件夹下
unzip hadoop2lib.zip
4.在HDFS上新建/mymapreduce3/in目录,然后将Linux本地/data/mapreduce3目录下的goods_click文件导入到HDFS的/mymapreduce3/in目录中。
hadoop fs -mkdir -p /mymapreduce3/in
hadoop fs -put /data/mapreduce3/goods_click /mymapreduce3/in
注意:文件需要注意文件格式,数据后有隐藏的空格会导致API中读取失败,行末尾的空格应该取消掉,中间使用逗号分隔开
5.在IDEA中编写代码
package mapreduce3; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class OneSort { public static class Map extends Mapper<Object , Text , IntWritable,Text >{ private static Text goods=new Text(); private static IntWritable num=new IntWritable(); public void map(Object key,Text value,Context context) throws IOException, InterruptedException{ String line=value.toString(); String arr[]=line.split(","); num.set(Integer.parseInt(arr[1])); goods.set(arr[0]); context.write(num,goods); } } public static class Reduce extends Reducer< IntWritable, Text, IntWritable, Text>{ private static IntWritable result= new IntWritable(); public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{ for(Text val:values){ context.write(key,val); } } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf=new Configuration(); Job job =new Job(conf,"OneSort"); job.setJarByClass(OneSort.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path in=new Path("hdfs://192.168.149.10:9000/mymapreduce3/in/goods_visit1"); Path out=new Path("hdfs://192.168.149.10:9000/mymapreduce3/out"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
6.创建resources文件夹,其中创建log4j.properties文件
hadoop.root.logger=DEBUG, console log4j.rootLogger = DEBUG, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.out log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
7.导入hadoop2lib的包
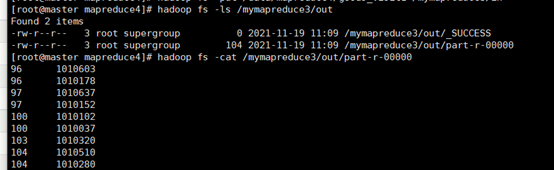
8.运行结果

PS:记得修改权限