05.Mapreduce实例——Map端join
实验原理
MapReduce提供了表连接操作其中包括Map端join、Reduce端join还有单表连接,现在我们要讨论的是Map端join,Map端join是指数据到达map处理函数之前进行合并的,效率要远远高于Reduce端join,因为Reduce端join是把所有的数据都经过Shuffle,非常消耗资源。
1.Map端join的使用场景:一张表数据十分小、一张表数据很大。
Map端join是针对以上场景进行的优化:将小表中的数据全部加载到内存,按关键字建立索引。大表中的数据作为map的输入,对map()函数每一对<key,value>输入,都能够方便地和已加载到内存的小数据进行连接。把连接结果按key输出,经过shuffle阶段,reduce端得到的就是已经按key分组并且连接好了的数据。
为了支持文件的复制,Hadoop提供了一个类DistributedCache,使用该类的方法如下:
(1)用户使用静态方法DistributedCache.addCacheFile()指定要复制的文件,它的参数是文件的URI(如果是HDFS上的文件,可以这样:hdfs://namenode:9000/home/XXX/file,其中9000是自己配置的NameNode端口号)。JobTracker在作业启动之前会获取这个URI列表,并将相应的文件拷贝到各个TaskTracker的本地磁盘上。
(2)用户使用DistributedCache.getLocalCacheFiles()方法获取文件目录,并使用标准的文件读写API读取相应的文件。
2.本实验Map端Join的执行流程
(1)首先在提交作业的时候先将小表文件放到该作业的DistributedCache中,然后从DistributeCache中取出该小表进行join连接的 <key ,value>键值对,将其解释分割放到内存中(可以放大Hash Map等等容器中)。
(2)要重写MyMapper类下面的setup()方法,因为这个方法是先于map方法执行的,将较小表先读入到一个HashMap中。
(3)重写map函数,一行行读入大表的内容,逐一的与HashMap中的内容进行比较,若Key相同,则对数据进行格式化处理,然后直接输出。
(4)map函数输出的<key,value >键值对首先经过一个suffle把key值相同的所有value放到一个迭代器中形成values,然后将<key,values>键值对传递给reduce函数,reduce函数输入的key直接复制给输出的key,输入的values通过增强版for循环遍历逐一输出,循环的次数决定了<key,value>输出的次数。
实验步骤:
- 建两个文本文档,用逗号分隔开,数据如下
orders1表
订单ID 订单号 用户ID 下单日期
52304 111215052630 176474 2011-12-15 04:58:21
52303 111215052629 178350 2011-12-15 04:45:31
52302 111215052628 172296 2011-12-15 03:12:23
52301 111215052627 178348 2011-12-15 02:37:32
52300 111215052626 174893 2011-12-15 02:18:56
52299 111215052625 169471 2011-12-15 01:33:46
52298 111215052624 178345 2011-12-15 01:04:41
52297 111215052623 176369 2011-12-15 01:02:20
52296 111215052622 178343 2011-12-15 00:38:02
52295 111215052621 178342 2011-12-15 00:18:43
52294 111215052620 178341 2011-12-15 00:14:37
52293 111215052619 178338 2011-12-15 00:13:07
order_items1表
明细ID 订单ID 商品ID
252578 52293 1016840
252579 52293 1014040
252580 52294 1014200
252581 52294 1001012
252582 52294 1022245
252583 52294 1014724
252584 52294 1010731
252586 52295 1023399
252587 52295 1016840
252592 52296 1021134
252593 52296 1021133
252585 52295 1021840
252588 52295 1014040
252589 52296 1014040
252590 52296 1019043
- 虚拟机中启动Hadoop
- 新建/data/mapreduce5目录
mkdir -p /data/mapreduce5
- 将两个表上传到虚拟机中
- 上传并解压hadoop2lib文件
- 在HDFS上新建/mymapreduce5/in目录,然后将Linux本地/data/mapreduce5目录下的orders1和order_items1文件导入到HDFS的/mymapreduce5/in目录中。
hadoop fs -mkdir -p /mymapreduce5/in
hadoop fs -put /data/mapreduce5/orders1 /mymapreduce5/in
hadoop fs -put /data/mapreduce5/order_items1 /mymapreduce5/in
- IDEA中编写Java代码
- package mapreduce5;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MapJoin {
public static class MyMapper extends Mapper<Object, Text, Text, Text>{
private Map<String, String> dict = new HashMap<>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
String fileName = context.getLocalCacheFiles()[0].getName();
//System.out.println(fileName);
BufferedReader reader = new BufferedReader(new FileReader(fileName));
String codeandname = null;
while (null != ( codeandname = reader.readLine() ) ) {
String str[]=codeandname.split("\t");
dict.put(str[0], str[2]+"\t"+str[3]);
}
reader.close();
}
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String[] kv = value.toString().split("\t");
if (dict.containsKey(kv[1])) {
context.write(new Text(kv[1]), new Text(dict.get(kv[1])+"\t"+kv[2]));
}
}
}
public static class MyReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text text : values) {
context.write(key, text);
}
}
}
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException, URISyntaxException {
Job job = Job.getInstance();
job.setJobName("mapjoin");
job.setJarByClass(MapJoin.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path in = new Path("hdfs://192.168.149.10:9000/mymapreduce5/in/order_items1");
Path out = new Path("hdfs://192.168.149.10:9000/mymapreduce5/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
URI uri = new URI("hdfs://192.168.149.10:9000/mymapreduce5/in/orders1");
job.addCacheFile(uri);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} - 将hadoop2lib目录中的jar包,拷贝到hadoop2lib目录下。
- 拷贝log4j.properties文件
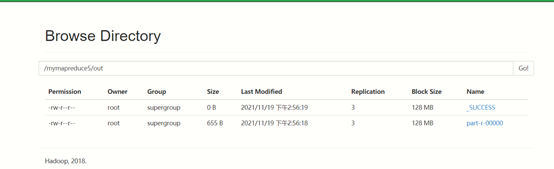
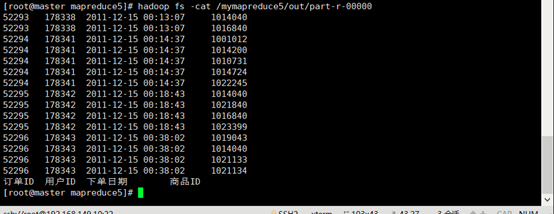
- 运行结果
运行失败,显示找不到文件orders1,报错filename
在filename前加上”Windows中存放orders1文件的地址”
再次运行,运行成功