I P是T C P / I P协议族中最为核心的协议。所有的 T C P、U D P、I C M P及I G M P数据都以I P数据
报格式传输(见图 1 - 4)。许多刚开始接触 T C P / I P的人对I P提供不可靠、无连接的数据报传送
服务感到很奇怪。
- 不可靠(u n r e l i a b l e)的意思是它不能保证 I P数据报能成功地到达目的地。 I P仅提供最好的传输服务。如果发生某种错误时,如某个路由器暂时用完了缓冲区, I P有一个简单的错误处理算法:丢弃该数据报,然后发送 I C M P消息报给信源端。任何要求的可靠性必须由上层来提供(如T C P)
- 无连接(c o n n e c t i o n l e s s)这个术语的意思是I P并不维护任何关于后续数据报的状态信息。每个数据报的处理是相互独立的。这也说明, I P数据报可以不按发送顺序接收。如果一信源向相同的信宿发送两个连续的数据报(先是 A,然后是B),每个数据报都是独立地进行路由选择,可能选择不同的路线,因此 B可能在A到达之前先到达。
1.IP首部
普通的IP首部长20个字节,除非有选项字段。
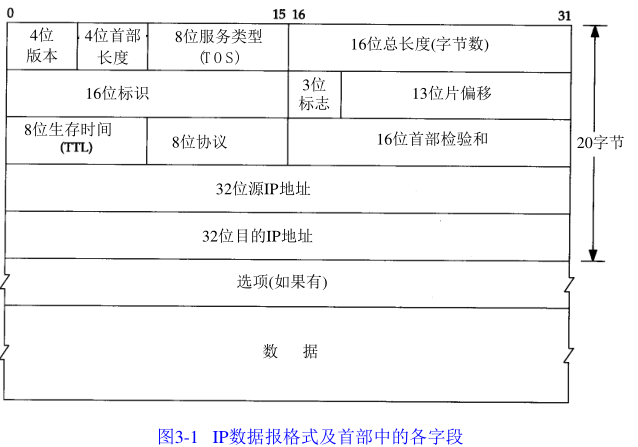
目前的协议版本号是4,因此I P有时也称作I P v 4。3 . 1 0节将对一种新版的I P协议进行讨论。
首部长度指的是首部占 32 bit字的数目,包括任何选项。由于它是一个 4比特字段,因此
首部最长为6 0个字节。在第8章中,我们将看到这种限制使某些选项如路由记录选项在当今已
没有什么用处。普通I P数据报(没有任何选择项)字段的值是 5
关于首部长度计算可以参看
https://blog.csdn.net/fl_dream/article/details/78761713
总长度字段是I P首部中必要的内容,因为一些数据链路(如以太网)需要填充一些数据以达到最小长度。尽管以太网的最小帧长为 4 6字节(见图2 - 1),但是I P数据可能会更短。如果没有总长度字段,那么I P层就不知道4 6字节中有多少是I P数据报的内容。
T T L(t i m e - t o - l i v e)生存时间字段设置了数据报可以经过的最多路由器数。它指定了数据报的生存时间。T T L的初始值由源主机设置(通常为3 2或6 4),一旦经过一个处理它的路由器,它的值就减去1。当该字段的值为 0时,数据报就被丢弃,并发送 I C M P报文通知源主机。第 8章我们讨论Tr a c e r o u t e程序时将再回来讨论该字段
为了计算一份数据报的 I P检验和,首先把检验和字段置为 0。然后,对首部中每个 16 bit进行二进制反码求和(整个首部看成是由一串 16 bit的字组成),结果存在检验和字段中。当收到一份I P数据报后,同样对首部中每个 16 bit进行二进制反码的求和。由于接收方在计算过程中包含了发送方存在首部中的检验和,因此,如果首部在传输过程中没有发生任何差错,那么接收方计算的结果应该为全 1。如果结果不是全1(即检验和错误),那么I P就丢弃收到的数据报。但是不生成差错报文,由上层去发现丢失的数据报并进行重传。
2.IP路由选择
从概念上说,I P路由选择是简单的,特别对于主机来说。如果目的主机与源主机直接相连(如点对点链路)或都在一个共享网络上(以太网或令牌环网),那么I P数据报就直接送到目的主机上。否则,主机把数据报发往一默认的路由器上,由路由器来转发该数据报。大多数的主机都是采用这种简单机制。
在一般的体制中,I P可以从T C P、U D P、I C M P和I G M P接收数据报(即在本地生成的数据报)并进行发送,或者从一个网络接口接收数据报(待转发的数据报)并进行发送。 I P层在内存中有一个路由表。当收到一份数据报并进行发送时,它都要对该表搜索一次。当数据报来自某个网络接口时,I P首先检查目的I P地址是否为本机的I P地址之一或者I P广播地址。如果确实是这样,数据报就被送到由 I P首部协议字段所指定的协议模块进行处理。如果数据报的目的不是这些地址,那么( 1)如果I P层被设置为路由器的功能,那么就对数据报进行转发
(也就是说,像下面对待发出的数据报一样处理);否则( 2)数据报被丢弃
路由表中的每一项都包含下面这些信息:
• 目的I P地址。它既可以是一个完整的主机地址,也可以是一个网络地址,由该表目中的标
志字段来指定(如下所述)。主机地址有一个非0的主机号(见图1 - 5),以指定某一特定的
主机,而网络地址中的主机号为0,以指定网络中的所有主机(如以太网,令牌环网)。
• 下一站(或下一跳)路由器( next-hop router)的I P地址,或者有直接连接的网络 I P地
址。下一站路由器是指一个在直接相连网络上的路由器,通过它可以转发数据报。下
一站路由器不是最终的目的,但是它可以把传送给它的数据报转发到最终目的。
• 标志。其中一个标志指明目的 I P地址是网络地址还是主机地址,另一个标志指明下一
站路由器是否为真正的下一站路由器,还是一个直接相连的接口(我们将在 9 . 2节中
详细介绍这些标志)。
• 为数据报的传输指定一个网络接口。
IP路由选择是逐跳地(h o p - b y - h o p)进行的。从这个路由表信息可以看出, I P并不知道到达任何目的的完整路径(当然,除了那些与主机直接相连的目的)。所有的I P路由选择只为数据报传输提供下一站路由器的 I P地址。它假定下一站路由器比发送数据报的主机更接近目的,而且下一站路由器与该主机是直接相连的。
3.子网寻址
现在所有的主机都要求支持子网编址( RFC 950 [Mogul and Postel 1985])。不是把I P地址看成由单纯的一个网络号和一个主机号组成,而是把主机号再分成一个子网号和一个主机号。这样做的原因是因为 A类和B类地址为主机号分配了太多的空间,可分别容纳的主机数为2 2 4 -2和2 1 6 -2。事实上,在一个网络中人们并不安排这么多的主机(各类 I P地址的格式如图1 - 5所示)。由于全0或全1的主机号都是无效的,因此我们把总数减去 2。
在I n t e r N I C获得某类I P网络号后,就由当地的系统管理员来进行分配,由他(或她)来决定是否建立子网,以及分配多少比特给子网号和主机号。例如,这里有一个 B类网络地址(1 4 0 . 2 5 2),在剩下的16 bit中,8 bit用于子网号,8 bit用于主机号,格式如图3 - 5所示。这样就允许有2 5 4个子网,每个子网可以有2 5 4台主机

4.子网掩码
任何主机在引导时进行的部分配置是指定主机 I P地址。大多数系统把 I P地址存在一个磁盘文件里供引导时读用。在第5章我们将讨论一个无盘系统如何在引导时获得 I P地址。除了I P地址以外,主机还需要知道有多少比特用于子网号及多少比特用于主机号。这是在引导过程中通过子网掩码来确定的。这个掩码是一个 32 bit的值,其中值为1的比特留给网络号和子网号,为0的比特留给主机号。图3 - 7是一个B类地址的两种不同的子网掩码格式。第一个例子是n o a o . e d u网络采用的子网划分方法,如图3 - 5所示,子网号和主机号都是8 bit宽。第二个例子是一个B类地址划分成10 bit的子网号和6 bit的主机号。
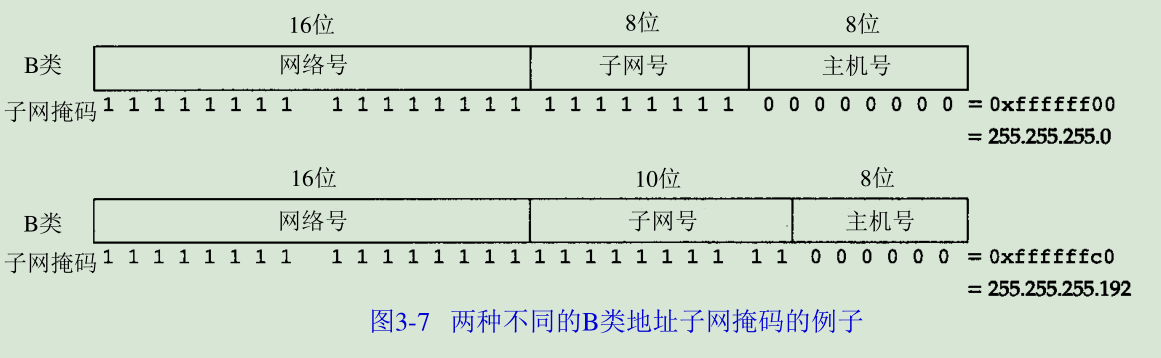
给定I P地址和子网掩码以后,主机就可以确定 I P数据报的目的是:(1)本子网上的主机;(2)本网络中其他子网中的主机;(3)其他网络上的主机。如果知道本机的 I P地址,那么就知道它是否为A类、B类或C类地址(从I P地址的高位可以得知),也就知道网络号和子网号之间的分界线。而根据子网掩码就可知道子网号与主机号之间的分界线。
IP地址是32位的二进制数值,用于在TCP/IP通讯协议中标记每台计算机的地址。通常我们使用点式十进制来表示,如192.168.0.5等等。
每个IP地址又可分为两部分。即网络号部分和主机号部分:网络号表示其所属的网络段编号,主机号则表示该网段中该主机的地址编号。按照网络规模的大小,IP地址可以分为A、B、C、D、E五类,其中A、B、C类是三种主要的类型地址,D类专供多目传送用的多目地址,E类用于扩展备用地址。A、B、C三类IP地址有效范围如下表:
类别 网络号 /占位数 主机号 /占位数 用途
A 1~126 / 8 0~255 0~255 1~254 / 24 国家级
B 128~191 0~255 / 16 0~255 1~254 / 16 跨过组织
C 192~223 0~255 0~255 / 24 1~254 / 8 企业组织
随着互连网应用的不断扩大,原先的IPv4的弊端也逐渐暴露出来,即网络号占位太多,而主机号位太少,所以其能提供的主机地址也越来越稀缺,目前除了使用NAT在企业内部利用保留地址自行分配以外,通常都对一个高类别的IP地址进行再划分,以形成多个子网,提供给不同规模的用户群使用。
这里主要是为了在网络分段情况下有效地利用IP地址,通过对主机号的高位部分取作为子网号,从通常的网络位界限中扩展或压缩子网掩码,用来创建某类地址的更多子网。但创建更多的子网时,在每个子网上的可用主机地址数目会比原先减少。
子网掩码是标志两个IP地址是否同属于一个子网的,也是32位二进制地址,其每一个为1代表该位是网络位,为0代表主机位。它和IP地址一样也是使用点式十进制来表示的。如果两个IP地址在子网掩码的按位与的计算下所得结果相同,即表明它们共属于同一子网中。
在计算子网掩码时,我们要注意IP地址中的保留地址,即“ 0”地址和广播地址,它们是指主机地址或网络地址全为“ 0”或“ 1”时的IP地址,它们代表着本网络地址和广播地址,一般是不能被计算在内的。
下面就来以实例来说明子网掩码的算法:
对于无须再划分成子网的IP地址来说,其子网掩码非常简单,即按照其定义即可写出:如某B类IP地址为 10.12.3.0,无须再分割子网,则该IP地址的子网掩码为255.255.0.0。如果它是一个C类地址,则其子网掩码为 255.255.255.0。其它类推,不再详述。下面我们关键要介绍的是一个IP地址,还需要将其高位主机位再作为划分出的子网网络号,剩下的是每个子网的主机号,这时该如何进行每个子网的掩码计算。
一、利用子网数来计算
在求子网掩码之前必须先搞清楚要划分的子网数目,以及每个子网内的所需主机数目。
1)将子网数目转化为二进制来表示
2)取得该二进制的位数,为 N
3)取得该IP地址的类子网掩码,将其主机地址部分的的前N位置 1 即得出该IP地址划分子网的子网掩码。
如欲将B类IP地址168.195.0.0划分成27个子网:
1)27=11011
2)该二进制为五位数,N = 5
3)将B类地址的子网掩码255.255.0.0的主机地址前5位置 1,得到 255.255.248.0
即为划分成 27个子网的B类IP地址 168.195.0.0的子网掩码。