背景
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Mapreduce1 vs YARN
Mapreduce1
我们首先来看一下整体架构
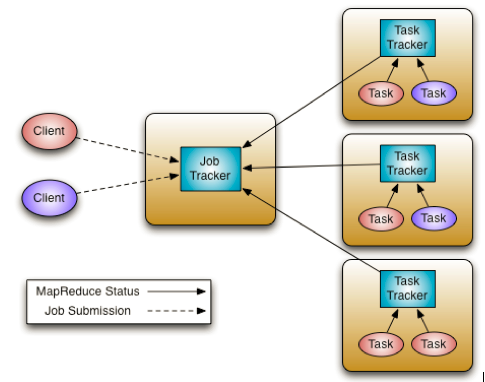
- JobTracker 是 Map-reduce 框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有 job 失败、重启等操作
- TaskTracker 是 Map-reduce 集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。TaskTracker 同时监视当前机器的 tasks 运行状况。TaskTracker 需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job 分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程
我们接下来解释一下一个任务提交的整体流程
- 在客户端启动一个作业。
- 向JobTracker请求一个Job ID。
- 将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
- JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢,呵呵),当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
- TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户
可以看出第一代的mapreduce简洁明了,在刚推出的时候受到了广泛的欢迎,有许多成功的案例。但是随着集群规模越来越大,第一代模型渐渐暴露出了许多问题
- JobTracker 是 Map-reduce 的集中处理点,存在单点故障
- JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限
- 在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM
- 在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题
于是有了第二代的mapreduce框架YARN
YARN
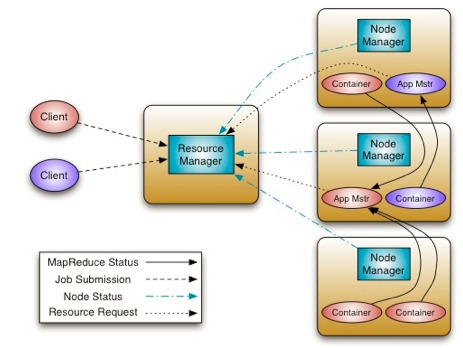
从上图可以看出有如下几种角色:
- ResourceManager: 负责Job的调度、管理,资源的分配、管理的模块。它所管理的单位是Job(更为通用的叫法是Application),不再是具体的Task,因此能比传统的MapReduce支持更大规模的集群;
- NodeManager:负责执行具体Task的模块。它不再有Slots的概念,取而代之的Container,Task都是通过在NodeManager上启动Container的方式来执行的;
- ApplicationMaster:由YARN框架提供的一个Libary,每个用户Application(Job)会对应一个ApplicationMaster,在用户提交Application后,ResourceManager会启动该Application对应的ApplicationMaster, 并把ApplicationMaster的地址反馈给客户端,后续客户端直接跟ApplicationMaster进行交互。ApplicatoinMaster负责向* ResourceManager申请执行用户Task所需要的资源,以及管理用户Application中每一个Task的运行情况;
- Container:抽象出来的资源集合的概念,它代表由ResouceManage授予给Application的资源,包括CPU、内存等。最终用户Task都是通过Container来执行的;
- Client:负责向ResourceManager提交Application(Job)请求,并从ApplicationMaster获取执行结果。
我们接下来解释一下一个任务提交的整体流程
- 用户通过Client向ResourceManager提交Application,ResourceManager根据用户的请求,分配一个合适的Container,然后在指定的NodeManager上启动该Container运行ApplicationMaster;
- ApplicationMaster在NodeManager上启动后,向ResourceManager注册自己;
- ApplicationMaster跟ResourceManager协商、申请用户Task所需要的Container, 申请到后ApplicationMaster把Container描述发给指定的NodeManager,NodeManager启动Container,运行用户Task;
- 用户Task在Container中执行的过程中,会定期向ApplicationMaster汇报执行的进度、状态等信息;
- 在执行过程中,Client可以直接跟ApplicationMaster通信,获取整个Application执行的进度、状态等信息;
- 所有的Task执行结束后,整个Application执行结束,ApplicationMaster会向ResourceManager注销自己,释放资源,并退出运行。
hello world
我们每次学习一门新技术,接触的第一个例子往往都是hello world。在hadoop中的hello world是统计单词计数
mapper.py
import sys
for line in sys.stdin:
words = line.strip().split(' ')
for word in words:
print word
reducer.py
import sys
pred_word = None
pred_cnt = 0
for word in sys.stdin:
if pred_word == word:
pred_cnt += 1
else:
if pred_word:
print " ".join([pred_word, pred_cnt])
pred_word = word
pred_cnt = 1
print " ".join([pred_word, pred_cnt])
shell
bin/hadoop jar hadoop_streaming.jar
-files mapper.py,reducer.py
-D stream.num.map.output.key.fields=1
-input /xxx/ooo/setences.txt
-output /xxx/ooo/wordcnt.txt
-mapper "python mapper.py"
-reducer "python reducer.py"
Map、Reduce任务中Shuffle和排序的过程
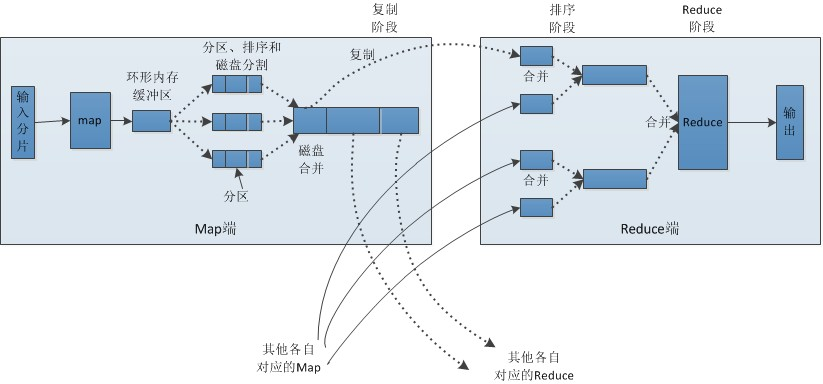
Map阶段分为Read-Map-Collect-Spill-Merge。Read读取数据,拆分为split,对每个Split执行Map函数,然后Map的输出进入Collect阶段。map的输出是(key, value), collect调用partitioner(线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据),获得输出(partition, key, value),存入环形缓冲区(该缓冲区的大小默认为100M,由io.sort.mb属性控制),并按照partition + key进行快速排序,如果有combiner,按照key进行聚合。缓冲区存储达到阈值时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),发生spill,写入磁盘。一次spill吐出一个临时文件,信息还包含每个分区在spill文件中的偏移量,便于快速获取需要的分区。merge阶段,将多个spill临时文件进行归并排序,生成一个大文件,因此每个mapper最后输出一个文件。
Reducer阶段分为Copy-Sort-Reduce。Reducer会定期查看哪些mapper已经完成,并将其output位置放在scheduledCoppies列表里,然后启动多个MapOutputCopier线程,去ScheduledCopies列表里指定的远程位置去拷贝数据。Reducer只拷贝map输出文件里属于自己处理的partition,拷贝的数据存在内存中,放不下则生成文件。Sort阶段,对多个mapper拷贝来的结果进行归并排序,保证全局有序。然后将排序后的结果喂给reduce函数处理,保存处理结果至HDFS。
Shuffle过程就是Collect+Spill+Merge+Copy+Sort,由Hadoop框架实现。这样用户只需要关注业务逻辑相关的map逻辑和reduce逻辑。
控制map和reduce的个数
reduce的个数:
-D mapred.reduce.tasks
map的个数:
我们知道,文件在上传到Hdfs文件系统的时候,被切分成不同的Block块(默认大小为64MB)。但是每个Map处理的分块有时候并不是系统的物理Block块大小。实际处理的输入分块的大小是根据inputSplit来设定的,那么inputSplit是怎么得到的呢
InputSplit = Math.max(minSize, Math.min(maxSize, blockSize)
mapSize = totalSize/InputSplit
- minSize=mapred.min.split.size
- maxSize=mapred.max.split.size
- totalSize 文件总大小
二级排序
二级排序是指Collect过程会在map输出结果的key前加入partition,reduce阶段首先根据自己负责的partition抓取map端的数据,然后再按照key进行排序。也即按照partition和key一起排序
实现join语句
SELECT u.name
, o.orderid
FROM order_info o
JOIN user_info u
ON o.uid = u.uid
可以参考美团点评博客

mapper.py
import os
import sys
def read_input(file):
for line in file:
yield line.rstrip().split()
def map(separator=' '):
file_path = os.environ["mapreduce_map_input_file"]
file_source = os.path.basename(os.path.dirname(file_path))
data = read_input(sys.stdin)
for flds in data:
uid = flds[0]
if file_source == 'user_info':
name = flds[1]
print ' '.join((uid, '1', name))
elif file_source == "order_info":
order_id = flds[1]
print ' '.join((uid, '2', order_id))
if __name__ == "__main__":
map()
reducer.py
from operator import itemgetter
from itertools import groupby
import sys
def read_mapper_output(file, separator=' '):
for line in file:
yield line.rstrip().split(separator)
def reduce(separator=' '):
data = read_mapper_output(sys.stdin, separator=separator)
for sno, group in groupby(data, itemgetter(0)):
name =None
if group[1] == '1':
name = group[2]
elif group[1] == '2':
order_id = group[2]
if name:
print separator.join((sno, name, order_id))
if __name__ == "__main__":
reduce()