《被kill问题之1:进程物理内存远大于Xmx的问题分析》
《被kill问题之2:Docker环境下Java应用的JVM设置(容器中的JVM资源该如何被安全的限制)》
问题
Java与Docker的结合,虽然更好的解决了application的封装问题。但也存在着不兼容,比如Java并不能自动的发现Docker设置的内存限制,CPU限制。
这将导致JVM不能稳定服务业务!容器会杀死你JVM进程,而健康检查又将拉起你的JVM进程,进而导致你监控你的pod一天重启次数甚至能达到几百次。
dmesg -T
[Fri Dec 6 08:02:46 2019] Out of memory: Kill process 10204 (java) score 70 or sacrifice child [Fri Dec 6 08:02:46 2019] Killed process 10204 (java) total-vm:13192148kB, anon-rss:2243220kB, file-rss:0kB, shmem-rss:0kB [Fri Dec 6 08:02:47 2019] docker0: port 13(veth9fbc66c) entered disabled state [Fri Dec 6 08:02:47 2019] docker0: port 13(veth9fbc66c) entered disabled state
理论解释:
操作系统(operating system)构建在进程(process)的基础上, 进程由内核作业(kernel jobs)进行调度和维护,其中有一个内核作业称为 “Out of memory killer(OOM终结者)”,Out of memory killer 在可用内存极低的情况下会杀死某些进程。只要达到触发条件就会激活,选中某个进程并杀掉。 通常采用启发式算法,对所有进程计算评分(heuristics scoring),得分最低的进程将被 kill 掉。 Out of memory: Kill process or sacrifice child 既不由JVM触发,也不由JVM代理,而是系统内核内置的一种安全保护措施。如果可用内存(含swap)不足, 就有可能会影响系统稳定,这时候 Out of memory killer 就会设法找出流氓进程并杀死他,也就是引起 Out of memory: kill process or sacrifice child 错误。
为什么设置了-XmX后,jvm被kill了?
docker镜像的内存上限,不能全部给“-Xmx”。因为JVM消耗的内存不仅仅是Heap,看下图:
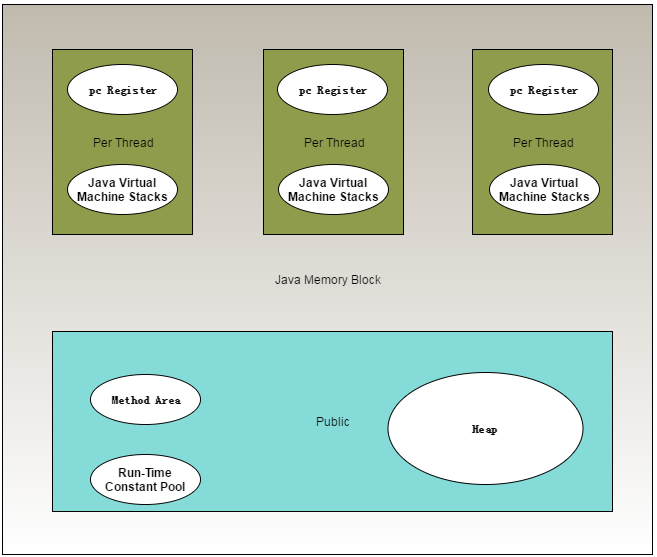
通常情况下, JVM占用的内存不仅仅是-Xmx, -Xms等指定的堆大小, 因为JVM也是一个应用, 它需要额外的空间去完成它的工作, 除了堆外, JVM会分配内存的地方包括以下这些:
Metaspace: 元数据区, 存储类, 及方法的元数据信息
Threads: 线程, 线程里的栈还是比较耗内存的, 在64位操作系统上, 默认栈的大小为1MB, 当然可以通过-Xss配置。因为一般情况下线程的数量是没有限制的, 因此可能会占用极其多的内存。
Code Cache: JVM通过JIT把字节码转换成机器指令, 然后把这些指令放到一个非堆区域Code Cache。
概况一下,JVM占用的内存为:RSS = Heapsize + MetaSpace + OffHeap size (这里OffHeap由线程堆栈,缓冲区,库(* .jars)和JVM代码本身组成。)
根据JDK1.8的特点: JVM运行时的内存=非heap(非heap=元空间+Thread Stack * num of thread+…) + heap + JVM进程运行所需内存+其他数据
所以Xmx的值要小于镜像上限内存。
当xmx的值与镜像的上限内存很接近时,xmx的内存最大值很大,fullGC会被推迟,但是这个时候,jvm的总内存已经超过了镜像上限,而被kill了。这就是为什么容器被kill了,但jvm没有oom日志了。
怎么做?
我们希望当Java进程运行在容器中时,java能够自动识别到容器限制,获取到正确的内存和CPU信息,而不用每次都需要在kubernetes的yaml描述文件中显示的配置完容器,还需要配置JVM参数。
使用JVM MaxRAM参数或者解锁实验特性的JVM参数,升级JDK到10+,我们可以解决这个问题(也许吧~.~)。
首先Docker容器本质是是宿主机上的一个进程,它与宿主机共享一个/proc目录,也就是说我们在容器内看到的/proc/meminfo,/proc/cpuinfo
与直接在宿主机上看到的一致,如下。
/ $ [ec2-user@ip-172-29-165-49 ~]$ cat /proc/meminfo MemTotal: 31960240 kB MemFree: 233200 kB MemAvailable: 4412724 kB
docker
[ec2-user@ip-172-29-165-49 ~]$ docker run -it --rm alpine cat /proc/meminfo Unable to find image 'alpine:latest' locally latest: Pulling from library/alpine 89d9c30c1d48: Pull complete Digest: sha256:c19173c5ada610a5989151111163d28a67368362762534d8a8121ce95cf2bd5a Status: Downloaded newer image for alpine:latest MemTotal: 31960240 kB MemFree: 278460 kB MemAvailable: 4351520 kB
那么Java是如何获取到Host的内存信息的呢?没错就是通过/proc/meminfo来获取到的。
默认情况下,JVM的Max Heap Size是系统内存的1/4,假如我们系统是8G,那么JVM将的默认Heap≈2G。
Docker通过CGroups完成的是对内存的限制,而/proc目录是已只读形式挂载到容器中的,由于默认情况下Java
压根就看不见CGroups的限制的内存大小,而默认使用/proc/meminfo中的信息作为内存信息进行启动,
这种不兼容情况会导致,如果容器分配的内存小于JVM的内存,JVM进程会被理解杀死。
让 JVM 感知 cgroup 限制
前文提到还有另外一种方法解决 JVM 内存超限的问题,这种方法可以让 JVM 自动感知 docker 容器的 cgroup 限制,从而动态的调整堆内存大小,感觉挺不错的。我们也来试一下这种方法,看看效果如何 ; )
回到demo项目代码的master分支,将 Dockerfile 中启动命令参数的-Xmx256m替换为-XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap,提交为useCGroupMemoryLimitForHeap分支,推送到代码仓库里。再次运行流水线进行构建部署。
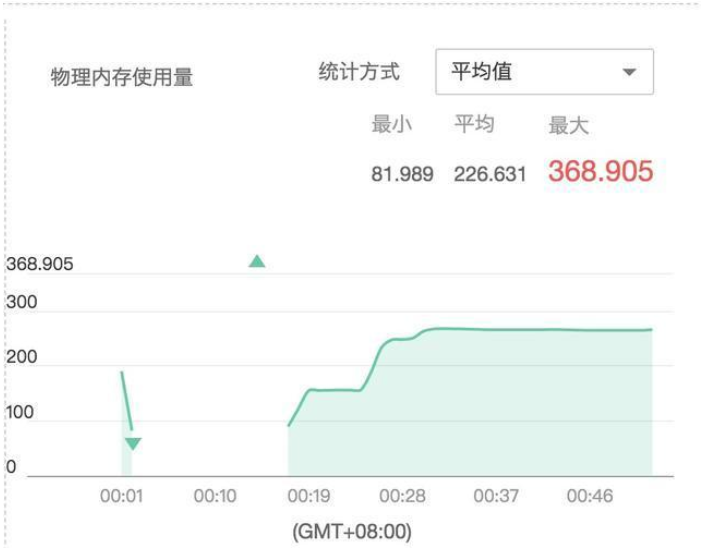
等 demo 服务部署成功后,再次调用/allocateMemory接口,容器的内存占用情况如上图所示(最右边的那一部分连续曲线),内存上升到一定程度后,JVM 抛出了 OOM 错误,没有继续申请堆内存。看来这种方式也是有效果的。不过,仔细观察容器的内存占用情况,可以发现容器所使用的内存仅为不到 300M,而我们对于这个容器的内存配额限制为 512M,也就是还有 200M+ 是闲置的,并不会被 JVM 利用。这个利用率,比起上文中直接设置-Xmx256m的内存利用率要低 : ( 。推测是因为 JVM 并不会感知到自己是部署在一个 docker 容器里的,所以它把当前的环境当成一个物理内存只有 512M 的物理机,按照比例来限制自己的最大堆内存,另一部分就被闲置了。
如此看来,如果想要充分利用自己的服务器资源,还是得多花一点功夫,手动调整好-Xmx参数。
来自网络上的一组经验值
以下参数配置适用于非计算密集型的大部分应用
分配内存 堆配置推荐
1.5G -Xmx1008M -Xms1008M -Xmn336M -XX:MaxMetaspaceSize=128M -XX:MetaspaceSize=128M
2G -Xmx1344M -Xms1344M -Xmn448M -XX:MaxMetaspaceSize=192M -XX:MetaspaceSize=192M
3G -Xmx2048M -Xms2048M -Xmn768M -XX:MaxMetaspaceSize=256M -XX:MetaspaceSize=256M
4G -Xmx2688M -Xms2688M -Xmn960M -XX:MaxMetaspaceSize=256M -XX:MetaspaceSize=256M
5G -Xmx3392M -Xms3392M -Xmn1216M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M
6G -Xmx4096M -Xms4096M -Xmn1536M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M
7G -Xmx4736M -Xms4736M -Xmn1728M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M
8G -Xmx5440M -Xms5440M -XX:MaxMetaspaceSize=512M -XX:MetaspaceSize=512M
内存>=8G 基础配置
-server
-XX:+DisableExplicitGC
-XX:+UseG1GC
-XX:MaxGCPauseMillis=100
-XX:+ParallelRefProcEnabled
-XX:+HeapDumpOnOutOfMemoryError
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCDateStamps
-XX:ErrorFile=/var/app/gc/hs_err_pid%p.log
-XX:HeapDumpPath=/var/app/gc
-Xloggc:/var/app/gc/gc%t.log
内存<8G 基础配置
-server
-XX:+DisableExplicitGC
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=70
-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses
-XX:+CMSClassUnloadingEnabled
-XX:+ParallelRefProcEnabled
-XX:+CMSScavengeBeforeRemark
-XX:+HeapDumpOnOutOfMemoryError
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintHeapAtGC
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCDateStamps
-XX:ErrorFile=/var/app/gc/hs_err_pid%p.log
-XX:HeapDumpPath=/var/app/gc
-Xloggc:/var/app/gc/gc%t.log
----------------------------------------------------------------------------
内存限制
概述
Docker 提供的内存限制功能有以下几点:
容器能使用的内存和交换分区大小。
容器的核心内存大小。
容器虚拟内存的交换行为。
容器内存的软性限制。
是否杀死占用过多内存的容器。
容器被杀死的优先级
一般情况下,达到内存限制的容器过段时间后就会被系统杀死。
内存限制相关的参数
执行docker run命令时能使用的和内存限制相关的所有选项如下。
| 选项 | 描述 |
|---|---|
| -m,–memory | 内存限制,格式是数字加单位,单位可以为 b,k,m,g。最小为 4M |
| –memory-swap | 内存+交换分区大小总限制。格式同上。必须必-m设置的大 |
| –memory-reservation | 内存的软性限制。格式同上 |
| –oom-kill-disable | 是否阻止 OOM killer 杀死容器,默认没设置 |
| –oom-score-adj | 容器被 OOM killer 杀死的优先级,范围是[-1000, 1000],默认为 0 |
| –memory-swappiness | 用于设置容器的虚拟内存控制行为。值为 0~100 之间的整数 |
| –kernel-memory | 核心内存限制。格式同上,最小为 4M |
用户内存限制
用户内存限制就是对容器能使用的内存和交换分区的大小作出限制。使用时要遵循两条直观的规则:-m,–memory选项的参数最小为 4 M。–memory-swap不是交换分区,而是内存加交换分区的总大小,所以–memory-swap必须比-m,–memory大。在这两条规则下,一般有四种设置方式。
你可能在进行内存限制的实验时发现docker run命令报错:WARNING: Your kernel does not support swap limit capabilities, memory limited without swap.
这是因为宿主机内核的相关功能没有打开。按照下面的设置就行。
step 1:编辑/etc/default/grub文件,将GRUB_CMDLINE_LINUX一行改为GRUB_CMDLINE_LINUX=“cgroup_enable=memory swapaccount=1”
step 2:更新 GRUB,即执行$ sudo update-grub
step 3: 重启系统。
1. 不设置
如果不设置-m,–memory和–memory-swap,容器默认可以用完宿舍机的所有内存和 swap 分区。不过注意,如果容器占用宿主机的所有内存和 swap 分区超过一段时间后,会被宿主机系统杀死(如果没有设置–00m-kill-disable=true的话)。
2. 设置-m,–memory,不设置–memory-swap
给-m或–memory设置一个不小于 4M 的值,假设为 a,不设置–memory-swap,或将–memory-swap设置为 0。这种情况下,容器能使用的内存大小为 a,能使用的交换分区大小也为 a。因为 Docker 默认容器交换分区的大小和内存相同。
如果在容器中运行一个一直不停申请内存的程序,你会观察到该程序最终能占用的内存大小为 2a。
比如$ docker run -m 1G ubuntu:16.04,该容器能使用的内存大小为 1G,能使用的 swap 分区大小也为 1G。容器内的进程能申请到的总内存大小为 2G。
3. 设置-m,–memory=a,–memory-swap=b,且b > a
给-m设置一个参数 a,给–memory-swap设置一个参数 b。a 时容器能使用的内存大小,b是容器能使用的 内存大小 + swap 分区大小。所以 b 必须大于 a。b -a 即为容器能使用的 swap 分区大小。
比如$ docker run -m 1G --memory-swap 3G ubuntu:16.04,该容器能使用的内存大小为 1G,能使用的 swap 分区大小为 2G。容器内的进程能申请到的总内存大小为 3G。
4. 设置-m,–memory=a,–memory-swap=-1
给-m参数设置一个正常值,而给–memory-swap设置成 -1。这种情况表示限制容器能使用的内存大小为 a,而不限制容器能使用的 swap 分区大小。
这时候,容器内进程能申请到的内存大小为 a + 宿主机的 swap 大小。
Memory reservation
这种 memory reservation 机制不知道怎么翻译比较形象。Memory reservation 是一种软性限制,用于节制容器内存使用。给–memory-reservation设置一个比-m小的值后,虽然容器最多可以使用-m使用的内存大小,但在宿主机内存资源紧张时,在系统的下次内存回收时,系统会回收容器的部分内存页,强迫容器的内存占用回到–memory-reservation设置的值大小。
没有设置时(默认情况下)–memory-reservation的值和-m的限定的值相同。将它设置为 0 会设置的比-m的参数大 等同于没有设置。
Memory reservation 是一种软性机制,它不保证任何时刻容器使用的内存不会超过–memory-reservation限定的值,它只是确保容器不会长时间占用超过–memory-reservation限制的内存大小。
例如:
$ docker run -it -m 500M --memory-reservation 200M ubuntu:16.04 /bin/bash
- 1
如果容器使用了大于 200M 但小于 500M 内存时,下次系统的内存回收会尝试将容器的内存锁紧到 200M 以下。
例如:
$ docker run -it --memory-reservation 1G ubuntu:16.04 /bin/bash
- 1
容器可以使用尽可能多的内存。–memory-reservation确保容器不会长时间占用太多内存。
OOM killer
默认情况下,在出现 out-of-memory(OOM) 错误时,系统会杀死容器内的进程来获取更多空闲内存。这个杀死进程来节省内存的进程,我们姑且叫它 OOM killer。我们可以通过设置–oom-kill-disable选项来禁止 OOM killer 杀死容器内进程。但请确保只有在使用了-m/–memory选项时才使用–oom-kill-disable禁用 OOM killer。如果没有设置-m选项,却禁用了 OOM-killer,可能会造成出现 out-of-memory 错误时,系统通过杀死宿主机进程或获取更改内存。
下面的例子限制了容器的内存为 100M 并禁止了 OOM killer:
$ docker run -it -m 100M --oom-kill-disable ubuntu:16.04 /bin/bash
- 1
是正确的使用方法。
而下面这个容器没设置内存限制,却禁用了 OOM killer 是非常危险的:
$ docker run -it --oom-kill-disable ubuntu:16.04 /bin/bash
- 1
容器没用内存限制,可能或导致系统无内存可用,并尝试时杀死系统进程来获取更多可用内存。
一般一个容器只有一个进程,这个唯一进程被杀死,容器也就被杀死了。我们可以通过–oom-score-adj选项来设置在系统内存不够时,容器被杀死的优先级。负值更教不可能被杀死,而正值更有可能被杀死。
核心内存
核心内存和用户内存不同的地方在于核心内存不能被交换出。不能交换出去的特性使得容器可以通过消耗太多内存来堵塞一些系统服务。核心内存包括:
1)stack pages(栈页面)
2)slab pages
3)socket memory pressure
4)tcp memory pressure
可以通过设置核心内存限制来约束这些内存。例如,每个进程都要消耗一些栈页面,通过限制核心内存,可以在核心内存使用过多时阻止新进程被创建。
核心内存和用户内存并不是独立的,必须在用户内存限制的上下文中限制核心内存。
假设用户内存的限制值为 U,核心内存的限制值为 K。有三种可能地限制核心内存的方式:
1)U != 0,不限制核心内存。这是默认的标准设置方式
2)K < U,核心内存时用户内存的子集。这种设置在部署时,每个 cgroup 的内存总量被过度使用。过度使用核心内存限制是绝不推荐的,因为系统还是会用完不能回收的内存。在这种情况下,你可以设置 K,这样 groups 的总数就不会超过总内存了。然后,根据系统服务的质量自有地设置 U。
3)K > U,因为核心内存的变化也会导致用户计数器的变化,容器核心内存和用户内存都会触发回收行为。这种配置可以让管理员以一种统一的视图看待内存。对想跟踪核心内存使用情况的用户也是有用的。
例如:
$ docker run -it -m 500M --kernel-memory 50M ubuntu:16.04 /bin/bash
- 1
容器中的进程最多能使用 500M 内存,在这 500M 中,最多只有 50M 核心内存。
$ docker run -it --kernel-memory 50M ubuntu:16.04 /bin/bash
- 1
没用设置用户内存限制,所以容器中的进程可以使用尽可能多的内存,但是最多能使用 50M 核心内存。
Swappiness
默认情况下,容器的内核可以交换出一定比例的匿名页。–memory-swappiness就是用来设置这个比例的。–memory-swappiness可以设置为从 0 到 100。0 表示关闭匿名页面交换。100 表示所有的匿名页都可以交换。默认情况下,如果不适用–memory-swappiness,则该值从父进程继承而来。
例如:
$ docker run -it --memory-swappiness=0 ubuntu:16.04 /bin/bash
- 1
将–memory-swappiness设置为 0 可以保持容器的工作集,避免交换代理的性能损失。
CPU 限制
概述
Docker 的资源限制和隔离完全基于 Linux cgroups。对 CPU 资源的限制方式也和 cgroups 相同。Docker 提供的 CPU 资源限制选项可以在多核系统上限制容器能利用哪些 vCPU。而对容器最多能使用的 CPU 时间有两种限制方式:一是有多个 CPU 密集型的容器竞争 CPU 时,设置各个容器能使用的 CPU 时间相对比例。二是以绝对的方式设置容器在每个调度周期内最多能使用的 CPU 时间。
CPU 限制相关参数
docker run命令和 CPU 限制相关的所有选项如下:
| 选项 | 描述 |
|---|---|
--cpuset-cpus="" |
允许使用的 CPU 集,值可以为 0-3,0,1 |
-c,--cpu-shares=0 |
CPU 共享权值(相对权重) |
cpu-period=0 |
限制 CPU CFS 的周期,范围从 100ms~1s,即[1000, 1000000] |
--cpu-quota=0 |
限制 CPU CFS 配额,必须不小于1ms,即 >= 1000 |
--cpuset-mems="" |
允许在上执行的内存节点(MEMs),只对 NUMA 系统有效 |
其中--cpuset-cpus用于设置容器可以使用的 vCPU 核。-c,--cpu-shares用于设置多个容器竞争 CPU 时,各个容器相对能分配到的 CPU 时间比例。--cpu-period和--cpu-quata用于绝对设置容器能使用 CPU 时间。
--cpuset-mems暂用不上,这里不谈。
CPU 集
我们可以设置容器可以在哪些 CPU 核上运行。
例如:
$ docker run -it --cpuset-cpus="1,3" ubuntu:14.04 /bin/bash表示容器中的进程可以在 cpu 1 和 cpu 3 上执行。
$ docker run -it --cpuset-cpus="0-2" ubuntu:14.04 /bin/bash
$ cat /sys/fs/cgroup/cpuset/docker/<容器的完整长ID>/cpuset.cpus
表示容器中的进程可以在 cpu 0、cpu 1 及 cpu 3 上执行。
在 NUMA 系统上,我们可以设置容器可以使用的内存节点。
例如:
$ docker run -it --cpuset-mems="1,3" ubuntu:14.04 /bin/bash表示容器中的进程只能使用内存节点 1 和 3 上的内存。
$ docker run -it --cpuset-mems="0-2" ubuntu:14.04 /bin/bash表示容器中的进程只能使用内存节点 0、1、2 上的内存。
CPU 资源的相对限制
默认情况下,所有的容器得到同等比例的 CPU 周期。在有多个容器竞争 CPU 时我们可以设置每个容器能使用的 CPU 时间比例。这个比例叫作共享权值,通过-c或--cpu-shares设置。Docker 默认每个容器的权值为 1024。不设置或将其设置为 0,都将使用这个默认值。系统会根据每个容器的共享权值和所有容器共享权值和比例来给容器分配 CPU 时间。
假设有三个正在运行的容器,这三个容器中的任务都是 CPU 密集型的。第一个容器的 cpu 共享权值是 1024,其它两个容器的 cpu 共享权值是 512。第一个容器将得到 50% 的 CPU 时间,而其它两个容器就只能各得到 25% 的 CPU 时间了。如果再添加第四个 cpu 共享值为 1024 的容器,每个容器得到的 CPU 时间将重新计算。第一个容器的CPU 时间变为 33%,其它容器分得的 CPU 时间分别为 16.5%、16.5%、33%。
必须注意的是,这个比例只有在 CPU 密集型的任务执行时才有用。在四核的系统上,假设有四个单进程的容器,它们都能各自使用一个核的 100% CPU 时间,不管它们的 cpu 共享权值是多少。
在多核系统上,CPU 时间权值是在所有 CPU 核上计算的。即使某个容器的 CPU 时间限制少于 100%,它也能使用各个 CPU 核的 100% 时间。
例如,假设有一个不止三核的系统。用-c=512的选项启动容器{C0},并且该容器只有一个进程,用-c=1024的启动选项为启动容器C2,并且该容器有两个进程。CPU 权值的分布可能是这样的:
PID container CPU CPU share
100 {C0} 0 100% of CPU0
101 {C1} 1 100% of CPU1
102 {C1} 2 100% of CPU2
$ docker run -it --cpu-shares=100 ubuntu:14.04 /bin/bash
$ cat /sys/fs/cgroup/cpu/docker/<容器的完整长ID>/cpu.shares
表示容器中的进程CPU份额值为100。
CPU 资源的绝对限制
Linux 通过 CFS(Completely Fair Scheduler,完全公平调度器)来调度各个进程对 CPU 的使用。CFS 默认的调度周期是 100ms。
关于 CFS 的更多信息,参考CFS documentation on bandwidth limiting。
我们可以设置每个容器进程的调度周期,以及在这个周期内各个容器最多能使用多少 CPU 时间。使用--cpu-period即可设置调度周期,使用--cpu-quota即可设置在每个周期内容器能使用的 CPU 时间。两者一般配合使用。
例如:
$ docker run -it --cpu-period=50000 --cpu-quota=25000 ubuntu:16.04 /bin/bash将 CFS 调度的周期设为 50000,将容器在每个周期内的 CPU 配额设置为 25000,表示该容器每 50ms 可以得到 50% 的 CPU 运行时间。
$ docker run -it --cpu-period=10000 --cpu-quota=20000 ubuntu:16.04 /bin/bash
$ cat /sys/fs/cgroup/cpu/docker/<容器的完整长ID>/cpu.cfs_period_us
$ cat /sys/fs/cgroup/cpu/docker/<容器的完整长ID>/cpu.cfs_quota_us
将容器的 CPU 配额设置为 CFS 周期的两倍,CPU 使用时间怎么会比周期大呢?其实很好解释,给容器分配两个 vCPU 就可以了。该配置表示容器可以在每个周期内使用两个 vCPU 的 100% 时间。
CFS 周期的有效范围是 1ms~1s,对应的--cpu-period的数值范围是 1000~1000000。而容器的 CPU 配额必须不小于 1ms,即--cpu-quota的值必须 >= 1000。可以看出这两个选项的单位都是 us。
正确的理解“绝对”
注意前面我们用--cpu-quota设置容器在一个调度周期内能使用的 CPU 时间时实际上设置的是一个上限。并不是说容器一定会使用这么长的 CPU 时间。比如,我们先启动一个容器,将其绑定到 cpu 1 上执行。给其--cpu-quota和--cpu-period都设置为 50000。
$ docker run --rm --name test01 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 deadloop:busybox-1.25.1-glibc调度周期为 50000,容器在每个周期内最多能使用 50000 cpu 时间。
再用docker stats test01可以观察到该容器对 CPU 的使用率在100%左右。然后,我们再以同样的参数启动另一个容器。
$ docker run --rm --name test02 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 deadloop:busybox-1.25.1-glibc再用docker stats test01 test02可以观察到这两个容器,每个容器对 cpu 的使用率在 50% 左右。说明容器并没有在每个周期内使用 50000 的 cpu 时间。
使用docker stop test02命令结束第二个容器,再加一个参数-c 2048启动它:
$ docker run --rm --name test02 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 -c 2048 deadloop:busybox-1.25.1-glibc再用docker stats test01命令可以观察到第一个容器的 CPU 使用率在 33% 左右,第二个容器的 CPU 使用率在 66% 左右。因为第二个容器的共享值是 2048,第一个容器的默认共享值是 1024,所以第二个容器在每个周期内能使用的 CPU 时间是第一个容器的两倍。
磁盘IO配额控制
相对于CPU和内存的配额控制,docker对磁盘IO的控制相对不成熟,大多数都必须在有宿主机设备的情况下使用。主要包括以下参数:
- –device-read-bps:限制此设备上的读速度(bytes per second),单位可以是kb、mb或者gb。
- –device-read-iops:通过每秒读IO次数来限制指定设备的读速度。
- –device-write-bps :限制此设备上的写速度(bytes per second),单位可以是kb、mb或者gb。
- –device-write-iops:通过每秒写IO次数来限制指定设备的写速度。
- –blkio-weight:容器默认磁盘IO的加权值,有效值范围为10-100。
- –blkio-weight-device: 针对特定设备的IO加权控制。其格式为DEVICE_NAME:WEIGHT
存储配额控制的相关参数,可以参考Red Hat文档中blkio这一章,了解它们的详细作用。
磁盘IO配额控制示例
blkio-weight
要使–blkio-weight生效,需要保证IO的调度算法为CFQ。可以使用下面的方式查看:
root@ubuntu:~# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
使用下面的命令创建两个–blkio-weight值不同的容器:
docker run -ti –rm –blkio-weight 100 ubuntu:stress
docker run -ti –rm –blkio-weight 1000 ubuntu:stress
在容器中同时执行下面的dd命令,进行测试:
time dd if=/dev/zero of=test.out bs=1M count=1024 oflag=direct
最终输出如下图所示:

在我的测试环境上没有达到理想的测试效果,通过docker官方的blkio-weight doesn’t take effect in docker Docker version 1.8.1 #16173,可以发现这个问题在一些环境上存在,但docker官方也没有给出解决办法。
device-write-bps
使用下面的命令创建容器,并执行命令验证写速度的限制。
docker run -tid –name disk1 –device-write-bps /dev/sda:1mb ubuntu:stress
通过dd来验证写速度,输出如下图示:

可以看到容器的写磁盘速度被成功地限制到了1MB/s。device-read-bps等其他磁盘IO限制参数可以使用类似的方式进行验证。
容器空间大小限制
在docker使用devicemapper作为存储驱动时,默认每个容器和镜像的最大大小为10G。如果需要调整,可以在daemon启动参数中,使用dm.basesize来指定,但需要注意的是,修改这个值,不仅仅需要重启docker daemon服务,还会导致宿主机上的所有本地镜像和容器都被清理掉。
使用aufs或者overlay等其他存储驱动时,没有这个限制。
----------------------------------------------------------------------------