Spring Cloud Stream 是消息中间件组件,它集成了 kafka 和 rabbitmq 。Spring Cloud Stream是一个用于构建消息驱动的微服务应用程序的框架,是一个基于Spring Boot 创建的独立生产级的,使用Spring Integration提供连接到消息代理的Spring应用。
Spring Cloud Stream与各模块之间的关系是:
SCS 在 Spring Integration 的基础上进行了封装,提出了 Binder, Binding, @EnableBinding, @StreamListener 等概念;
SCS 与 Spring Boot Actuator 整合,提供了 /bindings, /channels endpoint;
SCS 与 Spring Boot Externalized Configuration 整合,提供了 BindingProperties, BinderProperties 等外部化配置类;
SCS 增强了消息发送失败的和消费失败情况下的处理逻辑等功能。
SCS 是 Spring Integration 的加强,同时与 Spring Boot 体系进行了融合,也是 Spring Cloud Bus 的基础。它屏蔽了底层消息中间件的实现细节,希望以统一的一套 API 来进行消息的发送/消费,底层消息中间件的实现细节由各消息中间件的 Binder 完成。
Binder 是提供与外部消息中间件集成的组件,为构造 Binding提供了 2 个方法,分别是 bindConsumer 和 bindProducer ,它们分别用于构造生产者和消费者。目前官方的实现有 Rabbit Binder 和 Kafka Binder, Spring Cloud Alibaba 内部已经实现了 RocketMQ Binder。
了解SpringCloud流的时候,我们会发现,SpringCloud还有个Data Flow(数据流)的项目,下面是它们的区别:
-
Spring Cloud Stream:数据流操作开发包,封装了与Redis,Rabbit、Kafka等发送接收消息。是一套用于创建消息驱动(message-driven)微服务的框架。通过向主程序添加@EnableBinding,可以立即连接到消息代理,通过向方法添加@StreamListener,您将收到流处理事件。
-
Spring Cloud Data Flow:大数据操作工具,作为Spring XD的替代产品,它是一个混合计算模型,结合了流数据与批量数据的处理方式。是构建数据集成和实时数据处理流水线的工具包。
-
Spring Cloud Data Flow的其中一个章节是包含了Spring Cloud Stream,所以应该说Spring Cloud Data Flow的范围更广,是类似于一种解决方案的集合,而Spring Cloud Stream只是一套消息驱动的框架。
-
Spring Cloud Stream是在Spring Integration的基础上发展起来的。它为开发人员提供了一致的开发经验,以构建可以包含企业集成模式以与外部系统(例如数据库,消息代理等)连接的应用程序。
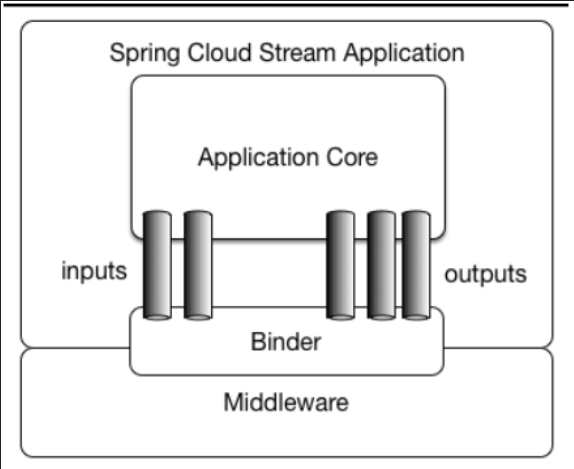
如图所示,Spring Cloud Stream由一个中间件中立的核组成。应用通过Spring Cloud Stream插入的input(相当于消费者consumer,它是从队列中接收消息的)和output(相当于生产者producer,它是从队列中发送消息的。)通道与外界交流。
结论:
1、Spring Cloud Stream以消息作为流的基本单位,所以它已经不是狭义上的IO流,而是广义上的数据流动,从生产者到消费者的数据流动。
2、Spring Cloud Stream 最大的方便之处,莫过于抽象了事件驱动的一些概念,对于消息中间件的进一步封装,可以做到代码层面对中间件的无感知,甚至于动态的切换中间件,切换topic。使得微服务开发的高度解耦,服务可以关注更多自己的业务流程。
消息中间件几大应用场景
1、异步处理
比如用户在电商网站下单,下单完成后会给用户推送短信或邮件,发短信和邮件的过程就可以异步完成。因为下单付款是核心业务,发邮件和短信并不属于核心功能,并且可能耗时较长,所以针对这种业务场景可以选择先放到消息队列中,有其他服务来异步处理。
2、应用解耦:
假设公司有几个不同的系统,各系统在某些业务有联动关系,比如 A 系统完成了某些操作,需要触发 B 系统及 C 系统。如果 A 系统完成操作,主动调用 B 系统的接口或 C 系统的接口,可以完成功能,但是各个系统之间就产生了耦合。用消息中间件就可以完成解耦,当 A 系统完成操作将数据放进消息队列,B 和 C 系统去订阅消息就可以了。这样各系统只要约定好消息的格式就好了。
3、流量削峰
比如秒杀活动,一下子进来好多请求,有的服务可能承受不住瞬时高并发而崩溃,所以针对这种瞬时高并发的场景,在中间加一层消息队列,把请求先入队列,然后再把队列中的请求平滑的推送给服务,或者让服务去队列拉取。
4、日志处理
kafka 最开始就是专门为了处理日志产生的。
当碰到上面的几种情况的时候,就要考虑用消息队列了。如果你碰巧使用的是 RabbitMQ 或者 kafka ,而且同样也是在使用 Spring Cloud ,那可以考虑下用 Spring Cloud Stream。
使用 Spring Cloud Stream && RabbitMQ
介绍下面的例子之前,假定你已经对 RabbitMQ 有一定的了解。
Destination Binders:目标绑定器,目标指的是 kafka 还是 RabbitMQ,绑定器就是封装了目标中间件的包。如果操作的是 kafka 就使用 kafka binder ,如果操作的是 RabbitMQ 就使用 rabbitmq binder。
Destination Bindings:外部消息传递系统和应用程序之间的桥梁,提供消息的“生产者”和“消费者”(由目标绑定器创建)
Message:一种规范化的数据结构,生产者和消费者基于这个数据结构通过外部消息系统与目标绑定器和其他应用程序通信。
主要概念(Main Concepts)
首先来认识一下 Spring Cloud Stream 中的几个重要概念:
应用模型:应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream 中Binder 交互,通过我们配置来绑定,而 Spring Cloud Stream 的 Binder 负责与中间件交互。所以,我们只需要搞清楚如何与 Spring Cloud Stream 交互就可以方便使用消息驱动的方式。
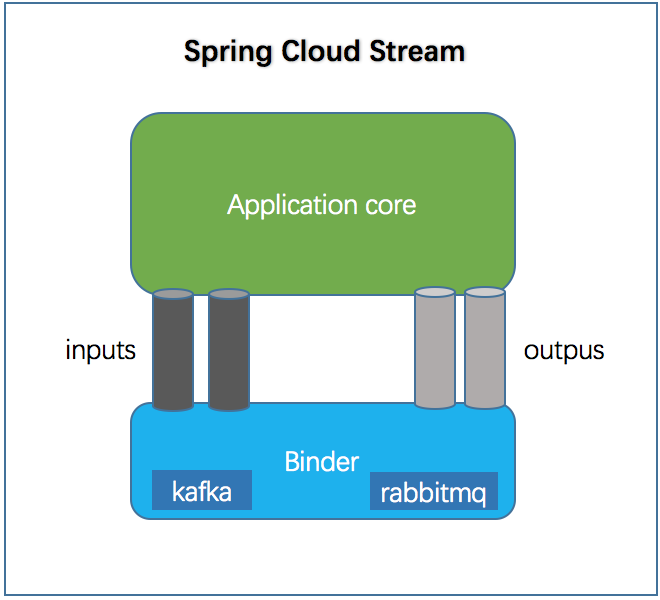
抽象绑定器(The Binder Abstraction)
Spring Cloud Stream实现Kafkat和RabbitMQ的Binder实现,也包括了一个TestSupportBinder,用于测试。你也可以写根据API去写自己的Binder.
Spring Cloud Stream 同样使用了Spring boot的自动配置,并且抽象的Binder使Spring Cloud Stream的应用获得更好的灵活性,比如:我们可以在application.yml或application.properties中指定参数进行配置使用Kafka或者RabbitMQ,而无需修改我们的代码。
在前面我们测试的项目中并没有修改application.properties,自动配置得益于Spring Boot
通过 Binder ,可以方便地连接中间件,可以通过修改application.yml中的spring.cloud.stream.bindings.input.destination 来进行改变消息中间件(对应于Kafka的topic,RabbitMQ的exchanges)
在这两者间的切换甚至不需要修改一行代码。
-
发布-订阅(Persistent Publish-Subscribe Support)
如下图是经典的Spring Cloud Stream的 发布-订阅 模型,生产者 生产消息发布在shared topic(共享主题)上,然后 消费者 通过订阅这个topic来获取消息

其中topic对应于Spring Cloud Stream中的destinations(Kafka 的topic,RabbitMQ的 exchanges)
官方文档这块原理说的有点深,就没写,详见官方文档
消费组(Consumer Groups)
尽管发布-订阅 模型通过共享的topic连接应用变得很容易,但是通过创建特定应用的多个实例的来扩展服务的能力同样重要,但是如果这些实例都去消费这条数据,那么很可能会出现重复消费的问题,我们只需要同一应用中只有一个实例消费该消息,这时我们可以通过消费组来解决这种应用场景, 当一个应用程序不同实例放置在一个具有竞争关系的消费组中,组里面的实例中只有一个能够消费消息
设置消费组的配置为spring.cloud.stream.bindings.<channelName>.group,
下面举一个DD博客中的例子:
下图中,通过网络传递过来的消息通过主题,按照分组名进行传递到消费者组中
此时可以通过spring.cloud.stream.bindings.input.group=Group-A或spring.cloud.stream.bindings.input.group=Group-B进行指定消费组

所有订阅指定主题的组都会收到发布消息的一个备份,每个组中只有一个成员会收到该消息;如果没有指定组,那么默认会为该应用分配一个匿名消费者组,与所有其它组处于 订阅-发布 关系中。ps:也就是说如果管道没有指定消费组,那么这个匿名消费组会与其它组一起消费消息,出现了重复消费的问题。
-
消费者类型(Consumer Types)
1)支持有两种消费者类型:
- Message-driven (消息驱动型,有时简称为
异步) - Polled (轮询型,有时简称为
同步)
在Spring Cloud 2.0版本前只支持 Message-driven这种异步类型的消费者,消息一旦可用就会传递,并且有一个线程可以处理它;当你想控制消息的处理速度时,可能需要用到同步消费者类型。
2)持久化
一般来说所有拥有订阅主题的消费组都是持久化的,除了匿名消费组。 Binder的实现确保了所有订阅关系的消费订阅是持久的,一个消费组中至少有一个订阅了主题,那么被订阅主题的消息就会进入这个组中,无论组内是否停止。
注意: 匿名订阅本身是非持久化的,但是有一些Binder的实现(比如RabbitMQ)则可以创建非持久化的组订阅
通常情况下,当有一个应用绑定到目的地的时候,最好指定消费消费组。扩展Spring Cloud Stream应用程序时,必须为每个输入绑定指定一个使用者组。这样做可以防止应用程序的实例接收重复的消息(除非需要这种行为,这是不寻常的)。
- Message-driven (消息驱动型,有时简称为
-
分区支持(Partitioning Support)
在消费组中我们可以保证消息不会被重复消费,但是在同组下有多个实例的时候,我们无法确定每次处理消息的是不是被同一消费者消费,分区的作用就是为了确保具有共同特征标识的数据由同一个消费者实例进行处理,当然前边的例子是狭义的,通信代理(broken topic)也可以被理解为进行了同样的分区划分。Spring Cloud Stream 的分区概念是抽象的,可以为不支持分区Binder实现(例如RabbitMQ)也可以使用分区。
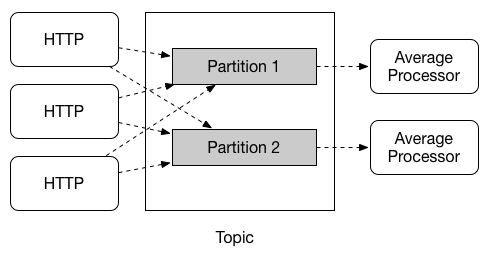
注意:要使用分区处理,你必须同时对生产者和消费者进行配置。
编程模型(Programming Model)
为了理解编程模型,需要熟悉下列核心概念:
- Destination Binders(目的地绑定器): 负责与外部消息系统集成交互的组件
- Destination Bindings(目的地绑定): 在外部消息系统和应用的生产者和消费者之间的桥梁(由Destination Binders创建)
- Message (消息): 用于生产者、消费者通过Destination Binders沟通的规范数据。
-
Destination Binders(目的地绑定器):
Destination Binders是Spring Cloud Stream与外部消息中间件提供了必要的配置和实现促进集成的扩展组件。集成了生产者和消费者的消息的路由、连接和委托、数据类型转换、用户代码调用等。
尽管Binders帮我们处理了许多事情,我们仍需要对他进行配置。之后会讲
-
Destination Bindings (目的地绑定) :
如前所述,Destination Bindings 提供连接外部消息中间件和应用提供的生产者和消费者中间的桥梁。
使用@EnableBinding 注解打在一个配置类上来定义一个Destination Binding,这个注解本身包含有@Configuration,会触发Spring Cloud Stream的基本配置。
接下来的例子展示完全配置且正常运行的Spring Cloud Stream应用,由INPUT接收消息转换成String 类型并打印在控制台上,然后转换出一个大写的信息返回到OUTPUT中。
@SpringBootApplication
@EnableBinding(Processor.class)
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public String handle(String value) {
System.out.println("Received: " + value);
return value.toUpperCase();
}
}通过SendTo注解将方法内返回值转发到其他消息通道中,这里因为没有定义接收通道,提示消息已丢失,解决方法是新建一个接口,如下
public interface MyPipe{ //方法1 @Input(Processor.OUTPUT) //这里使用Processor.OUTPUT是因为要同一个管道,或者名称相同 SubscribableChannel input(); //还可以如下这样=====二选一即可========== //方法2 String INPUT = "output"; @Input(MyPipe.INPUT) SubscribableChannel input(); }然后在在上边的方法下边加一个方法,并在@EnableBinding注解中改成@EnableBinding({Processor.class, MyPipe.class})
@StreamListener(MyPipe.INPUT) public void handleMyPipe(String value) { System.out.println("Received: " + value); }
Spring Cloud Stream已经为我们提供了三个绑定消息通道的默认实现
- Sink:通过指定消费消息的目标来标识消息使用者的约定。
- Source:与Sink相反,用于标识消息生产者的约定。
- Processor:集成了Sink和Source的作用,标识消息生产者和使用者
他们的源码分别为:
public interface Sink {
String INPUT = "input";
@Input("input")
SubscribableChannel input();
}
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
public interface Processor extends Source, Sink {
}Sink和Source中分别通过@Input和@Output注解定义了输入通道和输出通道,通过使用这两个接口中的成员变量来定义输入和输出通道的名称,Processor由于继承自这两个接口,所以同时拥有这两个通道。
注意:拥有多条管道的时候不能有输入输出管道名相同的,否则会出现发送消息被自己接收或报错的情况
我们可以根据上述源码的方式来定义我们自己的输入输出通道,定义输入通道需要返回SubscribaleChannel接口对象,这个接口继承自MessageChannel接口,它定义了维护消息通道订阅者的方法;定义输出通道则需要返回MessageChannel接口对象,它定义了向消息通道发送消息的方法。
自定义消息通道 发送与接收
依照上面的内容,我们也可以创建自己的绑定通道 如果你实现了上边的MyPipe接口,那么直接使用这个接口就好
- 和主类同包下建一个MyPipe接口,实现如下
package com.cnblogs.hellxz;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.SubscribableChannel;
public interface MyPipe {
//方法1
// @Input(Source.OUTPUT) //Source.OUTPUT的值是output,我们自定义也是一样的
// SubscribableChannel input(); //使用@Input注解标注的输入管道需要使用SubscribableChannel来订阅通道
//========二选一使用===========
//方法2
String INPUT = "output";
@Input(MyPipe.INPUT)
SubscribableChannel input();
}这里用Source.OUTPUT和第二种方法 是一样的,我们只要将消息发送到名为output的管道中,那么监听output管道的输入流一端就能获得数据
- 扩展主类,添加监听output管道方法
@StreamListener(MyPipe.INPUT)
public void receiveFromMyPipe(Object payload){
logger.info("Received: "+payload);
}-
在主类的头上的@EnableBinding改为
@EnableBinding({Sink.class, MyPipe.class}),加入了Mypipe接口的绑定 -
在test/java下创建
com.cnblogs.hellxz,并在包下新建一个测试类,如下package com.cnblogs.hellxz; import org.junit.Test; import org.junit.runner.RunWith; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.cloud.stream.annotation.EnableBinding; import org.springframework.cloud.stream.messaging.Source; import org.springframework.messaging.support.MessageBuilder; import org.springframework.test.context.junit4.SpringRunner; @RunWith(SpringRunner.class) @EnableBinding(value = {Source.class}) @SpringBootTest public class TestSendMessage { @Autowired private Source source; //注入接口和注入MessageChannel的区别在于发送时需不需要调用接口内的方法 @Test public void testSender() { source.output().send(MessageBuilder.withPayload("Message from MyPipe").build()); //假设注入了MessageChannel messageChannel; 因为绑定的是Source这个接口, //所以会使用其中的唯一产生MessageChannel的方法,那么下边的代码会是 //messageChannel.send(MessageBuilder.withPayload("Message from MyPipe").build()); } } -
启动主类,清空输出,运行测试类,然后你就会得到在主类的控制台的消息以log形式输出
Message from MyPipe
我们是通过注入消息通道,并调用他的output方法声明的管道获得的MessageChannel实例,发送的消息
管道注入过程中可能会出现的问题
通过注入消息通道的方式虽然很直接,但是也容易犯错,当一个接口中有多个通道的时候,他们返回的实例都是MessageChannel,这样通过@Autowired注入的时候往往会出现有多个实例找到无法确定需要注入实例的错误,我们可以通过@Qualifier指定消息通道的名称,下面举例:
-
在主类包内创建一个拥有多个输出流的管道
/** * 多个输出管道 */ public interface MutiplePipe { @Output("output1") MessageChannel output1(); @Output("output2") MessageChannel output2(); } -
创建一个测试类
@RunWith(SpringRunner.class) @EnableBinding(value = {MutiplePipe.class}) //开启绑定功能 @SpringBootTest //测试 public class TestMultipleOutput { @Autowired private MessageChannel messageChannel; @Test public void testSender() { //向管道发送消息 messageChannel.send(MessageBuilder.withPayload("produce by multiple pipe").build()); } }启动测试类,会出现刚才说的不唯一的bean,无法注入
Caused by: org.springframework.beans.factory.NoUniqueBeanDefinitionException: No qualifying bean of type 'org.springframework.messaging.MessageChannel' available: expected single matching bean but found 6: output1,output2,input,output,nullChannel,errorChannel我们在
@Autowired旁边加上@Qualifier("output1"),然后测试就可以正常启动了通过上边的错误,我们可以清楚的看到,每个MessageChannel都是使用消息通道的名字做为bean的名称。
这里我们没有使用监听这个管道,仅为了测试并发现问题
常用配置
消费组和分区的设置
给消费者设置消费组和主题
- 设置消费组:
spring.cloud.stream.bindings.<通道名>.group=<消费组名> - 设置主题:
spring.cloud.stream.bindings.<通道名>.destination=<主题名>
给生产者指定通道的主题:spring.cloud.stream.bindings.<通道名>.destination=<主题名>
消费者开启分区,指定实例数量与实例索引
- 开启消费分区:
spring.cloud.stream.bindings.<通道名>.consumer.partitioned=true - 消费实例数量:
spring.cloud.stream.instanceCount=1(具体指定) - 实例索引:
spring.cloud.stream.instanceIndex=1#设置当前实例的索引值
生产者指定分区键
- 分区键:
spring.cloud.stream.bindings.<通道名>.producer.partitionKeyExpress=<分区键> - 分区数量:
spring.cloud.stream.bindings.<通道名>.producer.partitionCount=<分区数量>
什么是消息驱动?
SpringCloud Stream消息驱动可以简化开发人员对消息中间件的使用复杂度,让系统开发人员更多尽力专注与核心业务逻辑的开发。SpringCloud Stream基于SpringBoot实现,自动配置化的功能可以帮助我们快速上手学习,类似与我们之前学习的orm框架,可以平滑的切换多种不同的数据库。
目前SpringCloud Stream 目前只支持 RabbitMQ和kafka。
stream这个项目让我们不必通过繁琐的自定义ampq来建立exchange,通道名称,以及队列名称和路由方式。只需要简单几步我们就轻松使用stream完成推送到rabbitmq和kafafa,并完成监听工作。
消息驱动原理
绑定器
通过定义绑定器作为中间层,实现了应用程序与消息中间件细节之间的隔离。通过向应用程序暴露统一的Channel通过,是的应用程序不需要再考虑各种不同的消息中间件的实现。当需要升级消息中间件,或者是更换其他消息中间件产品时,我们需要做的就是更换对应的Binder绑定器而不需要修改任何应用逻辑 。

在该模型图上有如下几个核心概念:
- Source: 当需要发送消息时,我们就需要通过Source,Source将会把我们所要发送的消息(POJO对象)进行序列化(默认转换成JSON格式字符串),然后将这些数据发送到Channel中;
- Sink: 当我们需要监听消息时就需要通过Sink来,Sink负责从消息通道中获取消息,并将消息反序列化成消息对象(POJO对象),然后交给具体的消息监听处理进行业务处理;
- Channel: 消息通道是Stream的抽象之一。通常我们向消息中间件发送消息或者监听消息时需要指定主题(Topic)/消息队列名称,但这样一旦我们需要变更主题名称的时候需要修改消息发送或者消息监听的代码,但是通过Channel抽象,我们的业务代码只需要对Channel就可以了,具体这个Channel对应的是那个主题,就可以在配置文件中来指定,这样当主题变更的时候我们就不用对代码做任何修改,从而实现了与具体消息中间件的解耦;
- Binder: Stream中另外一个抽象层。通过不同的Binder可以实现与不同消息中间件的整合,比如上面的示例我们所使用的就是针对Kafka的Binder,通过Binder提供统一的消息收发接口,从而使得我们可以根据实际需要部署不同的消息中间件,或者根据实际生产中所部署的消息中间件来调整我们的配置。
消息驱动有通道,绑定MQ。
生产者消息传递到通道里面之后,通道是跟MQ做绑定,封装的。消息一旦到MQ之后,发送给消费者通道,然后消费者进行消费 。绑定部分是底层帮助实现的。
封装也只是实现了部分功能。MQ的功能不是百分百都实现了的。
Spring Cloud Stream介绍
Spring Cloud Stream是一个用于构建消息驱动的微服务应用程序的框架,是一个基于Spring Boot 创建的独立生产级的,使用Spring Integration提供连接到消息代理的Spring应用。介绍持久发布 - 订阅(persistent publish-subscribe)的语义,消费组(consumer groups)和分区(partitions)的概念。
你可以添加@EnableBinding注解在你的应用上,从而立即连接到消息代理,在方法上添加@StreamListener以使其接收流处理事件,下面的例子展示了一个Sink应用接收外部信息
@SpringBootApplication @EnableBinding(Sink.class) public class VoteRecordingSinkApplication { public static void main(String[] args) { SpringApplication.run(VoteRecordingSinkApplication.class, args); } @StreamListener(Sink.INPUT) public void processVote(Vote vote) { votingService.recordVote(vote); } }
@EnableBinding注解会带着一个或多个接口作为参数(举例中使用的是Sink的接口),一个接口往往声名了输入和输出的渠道,Spring Stream提供了Source、Sink、Processor这三个接口,你也可以自己定义接口。
stream默认提供的消费者和生产者接口:
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
public interface Source {
String OUTPUT = "output";
@Output("output")
MessageChannel output();
}
@Input注解区分了一个输入channel,通过它接收消息到应用中,使用@Output注解 区分输出channel,消息通过它离开应用,使用这两个注解可以带一个channel的名字作为参数,如果未提供channel名称,则使用带注释的方法的名称。
你可以使用Spring Cloud Stream 现成的接口,也可以使用@Autowired注入这个接口,下面在测试类中举例
@RunWith(SpringJUnit4ClassRunner.class) @SpringBootTest public class LoggingConsumerApplicationTests { @Autowired private Sink sink; @Test public void contextLoads() { assertNotNull(this.sink.input()); } }
首先,stream提供了默认的输入和输出通过。如果我们不需要多个通道,可以通过@Enbalebing(Sink.Class)来绑定输入通道。对应的application里面的
# rabbitmq默认地址配置 rabbitmq: host: asdf.me port: 5672 username: guest password: guest cloud: stream: bindings: input: destination: push-exchange output: destination: push-exchange
这样会自动建立一个exchange为push-exchange名字的输出通道。同理@Enbalebing(Input.Class)是绑定输入通道的。下面创建一个生产者和消费者:
@EnableBinding(Source.class) public class Producer { @Autowired @Output(Source.OUTPUT) private MessageChannel channel; public void send() { channel.send(MessageBuilder.withPayload("producer" + UUID.randomUUID().toString()).build()); }
消费者:
@EnableBinding(Sink.class) public class Consumer { @StreamListener(Sink.INPUT) public void receive(Message<String> message) { System.out.println("接收到MQ消息:" + JSONObject.toJSONString(message)); } }
stream默认提供的消费者和生产者接口:
public interface Sink { String INPUT = "input"; @Input(Sink.INPUT) SubscribableChannel input(); } public interface Source { String OUTPUT = "output"; @Output("output") MessageChannel output(); }
可以看出,会去找到我们在application.yaml里面定义的input,output下面的destination。分别作为输入和输出通道。我们也可以自己定义接口来实现:
String WS_INPUT = "ws-consumer"; String EMAIL_INPUT = "email-consumer"; String SMS_INPUT = "sms-consumer"; @Input(MqMessageInputConfig.EMAIL_INPUT) SubscribableChannel emailChannel(); @Input(MqMessageInputConfig.WS_INPUT) SubscribableChannel wsChannel(); @Input(MqMessageInputConfig.SMS_INPUT) SubscribableChannel smChannel();
import org.springframework.cloud.stream.annotation.Output; import org.springframework.messaging.MessageChannel; public interface MqMessageOutputConfig { String MESSAGE_OUTPUT = "message-producter"; @Output(MqMessageOutputConfig.MESSAGE_OUTPUT) MessageChannel outPutChannel(); }
坑1.需要注意的是,最好不要自定义输入输出在同一个类里面。这样,如果我们只调用生产者发送消息。会导致提示Dispatcher has no subscribers for channel。并且会让我们发送消息的次数莫名减少几次。详细情况可以查看gihub官方issue,也给出的这种解决方法 官方解决方式
建立一个testjunit类,然后使用生产者发送消息。消费者监听队列获取消息。
接收到MQ消息:{"headers":{"amqp_receivedDeliveryMode":"PERSISTENT","amqp_receivedRoutingKey":"my-test-channel","amqp_receivedExchange":"my-test-channel","amqp_deliveryTag":1,"amqp_consumerQueue":"my-test-channel.anonymous.vYA2O6ZSQE-S9MOnE0ZoJQ","amqp_redelivered":false,"id":"805e7fc3-a046-e07a-edf5-def58d9c8eab","amqp_consumerTag":"amq.ctag-QwsmRKg5f0DGSp-7wbpYxQ","contentType":"text/plain","timestamp":1523930106483},"payload":"22222222222a7d24456-5b11-4c25-9270-876e7bbc556a"}
坑2.stream生成的exchang默认是topic模式。就是按照前缀匹配,发送消息给对应的队列。

- *(星号):可以(只能)匹配一个单词
-
#(井号):可以匹配多个单词(或者零个)
-
fanout:广播模式,发送到所有的队列
-
direct:直传。完全匹配routingKey的队列可以收到消息。