《Redis性能问题排查解决手册》
《Redis的基本操作以及info命令》
《redis object命令》
《清理 redis 死键》
参考:
场景:
在这类项目运行久了之后,一些老的key会不断在redis里积压,导致redis内存越来越高,对redis的使用效率产生影响,因此需要对于redis数据进行定期清理。
1、死key(死键)
所谓死键,在redis里有两个定义:
A、redis中为key设置了过期时间,但是没有在内存中被实际删除的key。【 这种情况是可能发生的,在redis中过期键的删除有两种策略,一般采用的是定期删除(比如每s删除10个),这样的话,如果我们过期键产生的速度是大于删除的速度,则会产生死键。】
B、未设置ttl的key(需要根据业务需求,查看能否删除)
C、死键是指在redis中长期未被访问的key(需要根据业务需求,查看能否删除)
2、轮转时间
轮转时间即idletime,是指该key有多长时间没有被访问过(单位 s)。
3、相关命令
其他命令
SSCAN 命令用于迭代集合键中的元素。
HSCAN 命令用于迭代哈希键中的键值对。
ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
# SCAN 命令是一个基于游标的迭代器(cursor based iterator):SCAN 命令每次被调用之后,都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数,以此来延续之前的迭代过程。
# 注意:当 SCAN 命令的游标参数被设置为 0 时,服务器将开始一次新的迭代,而当服务器向用户返回值为 0 的游标时,表示迭代已结束!
3.1、scan语法
redis Scan 命令基本语法如下:
SCAN cursor [MATCH pattern] [COUNT count]
- cursor - 游标。
- pattern - 匹配的模式。
- count - 指定从数据集里返回多少元素,默认值为 10 。
SCAN命令是一个基于游标的迭代器。这意味着命令每次被调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。
示例说明:
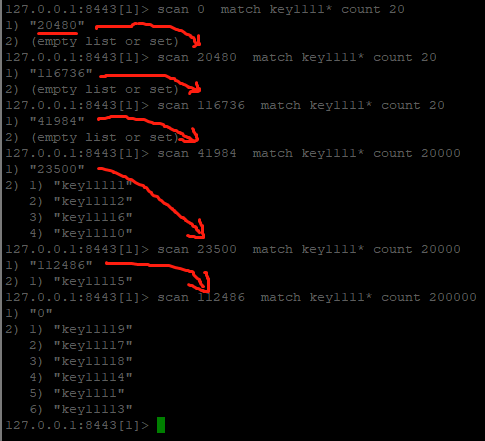
这里使用scan 0 match key1111* count 20命令来完成这个查询,稍显意外的是,使用一开始都没有查询到结果,这个要从scan命令的原理来看。
第一行:scan在遍历key的时候,0就代表第一次,key1111*代表按照key1111开头的模式匹配,count 20中的20并不是代表输出符合条件的key,而是限定服务器单次遍历的字典槽位数量(约等于)。
那么,什么又叫做槽的数据?这个槽是不是Redis集群中的slot?答案是否定的。其实上图已经给出了答案了。
如果上面说的“字典槽”的数量是集群中的slot,又知道集群中的slot数量是16384,那么遍历16384个槽之后,必然能遍历出来所有的key信息,
上面清楚地看到,当遍历的字典槽的数量20000的时候,游标依旧没有走完遍历结果,因此这个字典槽并不等于集群中的slot的概念。
经过测试,在scan的时候,究竟遍历多大的COUNT值能完全match到符合条件的key,跟具体对象的key的个数有关,
如果以超过key个数的count来scan,必定会一次性就查找到所有符合条件的key,比如在key个数为10W个的情况下,一次遍历20w个字典槽,肯定能完全遍历出来结果。
scan 指令是一系列指令,除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。
3.2、zscan 遍历 zset 集合元素
语法
redis Zscan 命令基本语法如下:
redis 127.0.0.1:6379> ZSCAN key cursor [MATCH pattern] [COUNT count]
- cursor - 游标。
- pattern - 匹配的模式。
- count - 指定从数据集里返回多少元素,默认值为 10 。
可用版本:>= 2.8.0
返回值:返回的每个元素都是一个有序集合元素,一个有序集合元素由一个成员(member)和一个分值(score)组成。
示例:
> ZADD site 1 "Google" 2 "Runoob" 3 "Taobao" 4 "Weibo" (integer) 4 > ZSCAN site 0 match "R*" 1) "0" 2) 1) "Runoob" 2) 2.0
3.3、hscan 遍历 hash 字典的元素
语法
redis Sscan 命令基本语法如下:
SSCAN key cursor [MATCH pattern] [COUNT count]
- cursor - 游标。
- pattern - 匹配的模式,match要匹配的是field字段不是value。
- count - 指定从数据集里返回多少元素,默认值为 10 。
可用版本:>= 2.8.0
返回值:返回的每个元素都是一个元组,每一个元组元素由一个字段(field) 和值(value)组成。
示例:

> HMSET sites google "google.com" runoob "runoob.com" weibo "weibo.com" 4 "taobao.com" OK > HSCAN sites 0 match "run*" 1) "0" 2) 1) "runoob" 2) "runoob.com"
> hscan sites 0 match "t*"
1) "0"
2)
>hscan sites 0 match "4*"
1) "0"
2) 1) "4"
2) "taobao.com"
3.4、sscan 遍历 set 集合的元素
语法
redis Sscan 命令基本语法如下:
SSCAN key cursor [MATCH pattern] [COUNT count]
- cursor - 游标。
- pattern - 匹配的模式。
- count - 指定从数据集里返回多少元素,默认值为 10 。
可用版本:>= 2.8.0
返回值:数组列表。
示例:
> SADD myset1 "Google" (integer) 1 > SADD myset1 "Runoob" (integer) 1 > SADD myset1 "Taobao" (integer) 1 > SSCAN myset1 0 match R* 1) "0" 2) 1) "Runoob"
SSCAN 命令、 HSCAN 命令和 ZSCAN 命令的第一个参数总是一个数据库键(某个指定的key)。
另外,使用redis desktop manager的时候,当刷新某个库的时候,控制台自动不断刷新scan命令,也就知道它在干嘛了。
4、扫描未设置ttl的key
4.1、shell脚本方式
好在redis-cli提供了scan的参数,来执行scan逻辑。redis-cli的用法见:
# vim redis_no_ttl_key.sh
#!/bin/bash # Redis 通过 scan 找出不过期的 key # SCAN 命令是一个基于游标的迭代器(cursor based iterator):SCAN 命令每次被调用之后,都会向用户返回一个新的游标,用户在下次迭代时需要使用这个新游标作为 SCAN 命令的游标参数,以此来延续之前的迭代过程。 # 注意:当 SCAN 命令的游标参数被设置为 0 时,服务器将开始一次新的迭代,而当服务器向用户返回值为 0 的游标时,表示迭代已结束! db_ip=10.100.41.148 # redis 连接IP db_port=6379 # redis 端口 password='IootCdgN05srE' # redis 密码 cursor=0 # 第一次游标 cnt=100 # 每次迭代的数量 new_cursor=0 # 下一次游标 redis-cli -c -h $db_ip -p $db_port -a $password scan $cursor count $cnt > scan_tmp_result new_cursor=`sed -n '1p' scan_tmp_result` # 获取下一次游标 sed -n '2,$p' scan_tmp_result > scan_result # 获取 key cat scan_result |while read line # 循环遍历所有 key do ttl_result=`redis-cli -c -h $db_ip -p $db_port -a $password ttl $line` # 获取key过期时间 if [[ $ttl_result == -1 ]];then #if [ $ttl_result -eq -1 ];then # 判断过期时间,-1 是不过期 echo $line >> no_ttl.log # 追加到指定日志 fi done while [ $cursor -ne $new_cursor ] # 若游标不为0,则证明没有迭代完所有的key,继续执行,直至游标为0 do redis-cli -c -h $db_ip -p $db_port -a $password scan $new_cursor count $cnt > scan_tmp_result new_cursor=`sed -n '1p' scan_tmp_result` sed -n '2,$p' scan_tmp_result > scan_result cat scan_result |while read line do ttl_result=`redis-cli -c -h $db_ip -p $db_port -a $password ttl $line` if [[ $ttl_result == -1 ]];then #if [ $ttl_result -eq -1 ];then echo $line >> no_ttl.log fi done done rm -rf scan_tmp_result rm -rf scan_result
只能扫描redis的0号库。
网上看到lua实现的:
----------------------------------------------------------------------------------------------------
网上看到一个redis的scan的命令式踩了坑的过程,背景如下:
公司因为redis服务器内存吃紧,需要删除一些无用的没有设置过期时间的key。大概有500多w的key。虽然key的数目听起来挺吓人。但是自己玩redis也有年头了,这种事还不是手到擒来?
当时想了下,具体方案是通过lua脚本来过滤出500w的key。然后进行删除动作。lua脚本在redis server上执行,执行速度快,执行一批只需要和redis server建立一次连接。筛选出来key,然后一次删1w。然后通过shell脚本循环个500次就能删完所有的。以前通过lua脚本做过类似批量更新的操作,3w一次也是秒级的。基本不会造成redis的阻塞。这样算起来,10分钟就能搞定500w的key。
然后,我就开始直接写lua脚本。首先是筛选。
用过redis的人,肯定知道redis是单线程作业的,肯定不能用keys命令来筛选,因为keys命令会一次性进行全盘搜索,会造成redis的阻塞,从而会影响正常业务的命令执行。
500w数据量的key,只能增量迭代来进行。redis提供了scan命令,就是用于增量迭代的。这个命令可以每次返回少量的元素,所以这个命令十分适合用来处理大的数据集的迭代,可以用于生产环境。
scan命令会返回一个数组,第一项为游标的位置,第二项是key的列表。如果游标到达了末尾,第一项会返回0。
踩坑1:
所以我写的第一版的lua脚本如下:
local c = 0 local resp = redis.call('SCAN',c,'MATCH','authToken*','COUNT',10000) c = tonumber(resp[1]) local dataList = resp[2] for i=1,#dataList do local d = dataList[i] local ttl = redis.call('TTL',d) if ttl == -1 then redis.call('DEL',d) end end if c==0 then return 'all finished' else return 'end' end
在本地的测试redis环境中,通过执行以下命令mock了1k的测试数据:
在redis的客户端或console输入如下命令执行:
测试环境-不要误删:0>eval "for i = 1, 1000 do redis.call('SET','authToken_' .. i,i) end" 0 null 测试环境-不要误删:0>
成功插入1000个ttl为-1的key-value
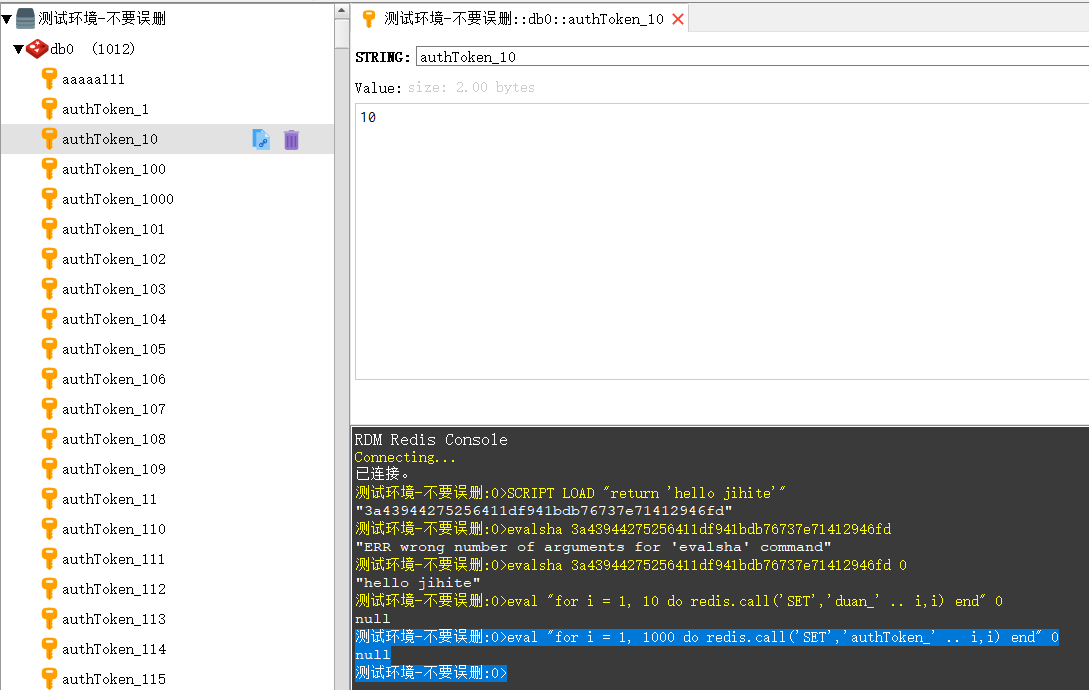
然后执行script load命令上传lua脚本得到SHA值,然后执行evalsha去执行得到的SHA值来运行。具体过程如下:
测试环境-不要误删:0>script load "local c = 0 local resp = redis.call('SCAN',c,'MATCH','authToken*','COUNT',10000) c = tonumber(resp[1]) local dataList = resp[2] for i=1,#dataList do local d = dataList[i] local ttl = redis.call('TTL',d) if ttl == -1 then print(d) redis.call('DEL',d) end end if c==0 then return 'all finished' else return 'end' end" "21df2cc32036b90018d5af738759830144ffa28c" 测试环境-不要误删:0>
evalsha执行:
测试环境-不要误删:0>evalsha 21df2cc32036b90018d5af738759830144ffa28c 0 "all finished" 测试环境-不要误删:0>
结果:
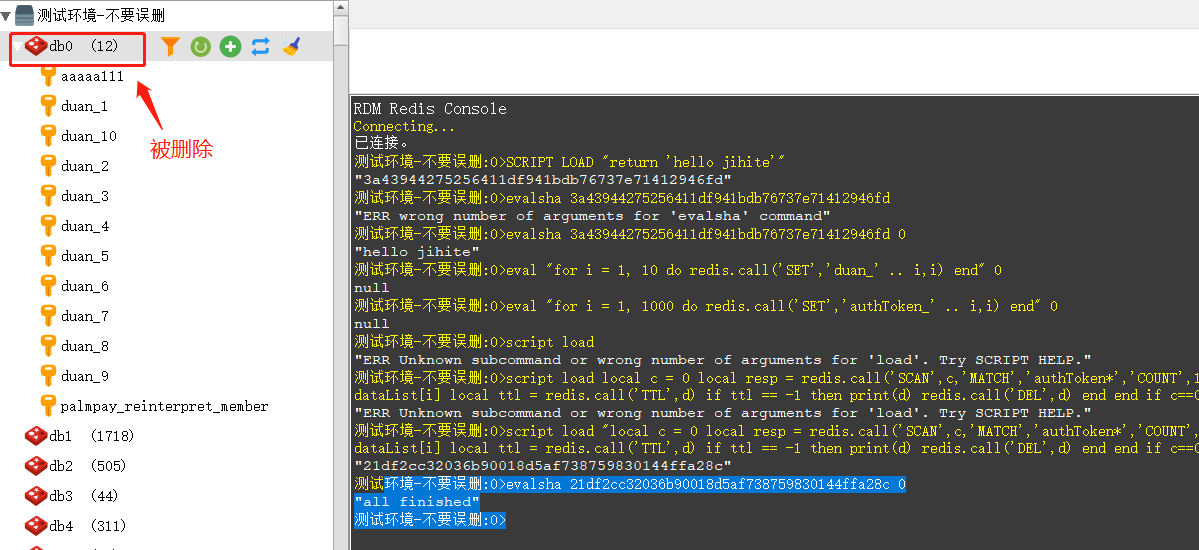
我每删1w数据,执行下dbsize(因为这是我本地的redis,里面只有mock的数据,dbsize也就等同于这个前缀key的数量了)。
奇怪的是,前面几行都是正常的。但是到了第三次的时候,dbsize变成了16999,多删了1个,我也没太在意,但是最后在dbsize还剩下124204个的时候,数量就不动了。之后无论再执行多少遍,数量还依旧是124204个。
随即我直接运行scan命令: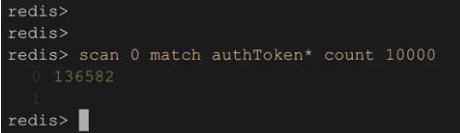
发现游标虽然没有到达末尾,但是key的列表却是空的。
我再去翻看redis的命令文档对count选项的解释:
经过详细研读,发现count选项所指定的返回数量还不是一定的,虽然知道可能是count的问题,但无奈文档的解释实在难以很通俗的理解,依旧不知道具体问题在哪,后来经过某个小伙伴的提示,看到了另外一篇对于scan命令count选项通俗的解释:
看完之后恍然大悟。原来count选项后面跟的数字并不是意味着每次返回的元素数量,而是scan命令每次遍历字典槽的数量。我scan执行的时候每一次都是从游标0的位置开始遍历,而并不是每一个字典槽里都存放着我所需要筛选的数据,这就造成了我最后的一个现象:虽然我count后面跟的是10000,但是实际redis从开头往下遍历了10000个字典槽后,发现没有数据槽存放着我所需要的数据。所以我最后的dbsize数量永远停留在了124204个。
所以在使用scan命令的时候,如果需要迭代的遍历,需要每次调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程。
可用版本:
至此,心中的疑惑就此解开,改了一版lua:
local c = tonumber(ARGV[1]) local resp = redis.call('SCAN',c,'MATCH','authToken*','COUNT',10000) c = tonumber(resp[1]) local dataList = resp[2] for i=1,#dataList do local d = dataList[i] local ttl = redis.call('TTL',d) if ttl == -1 then redis.call('DEL',d) end end return c
在本地上传:
测试环境-不要误删:0>script load "local c = tonumber(ARGV[1]) local resp = redis.call('SCAN',c,'MATCH','authToken*','COUNT',10000) c = tonumber(resp[1]) local dataList = resp[2] for i=1,#dataList do local d = dataList[i] local ttl = redis.call('TTL',d) if ttl == -1 then redis.call('DEL',d) end end return c" "a9e4f8116fec50c81e0716e4fdb2f0bbdd327f5c" 测试环境-不要误删:0>
执行:
测试环境-不要误删:0>eval "for i = 1, 200000 do redis.call('SET','authToken_' .. i,i) end" 0 null 测试环境-不要误删:0>dbsize "200012" 测试环境-不要误删:0>evalsha a9e4f8116fec50c81e0716e4fdb2f0bbdd327f5c 1 0 0 "77104" 测试环境-不要误删:0>dbsize "190012" 测试环境-不要误删:0>evalsha a9e4f8116fec50c81e0716e4fdb2f0bbdd327f5c 1 0 77104 "185490" 测试环境-不要误删:0>
77104的参数是上次evalsha返回的值。
dbsize用于统计删除后的总记录数。
一直反复调用直到执行lua脚本返回为0:
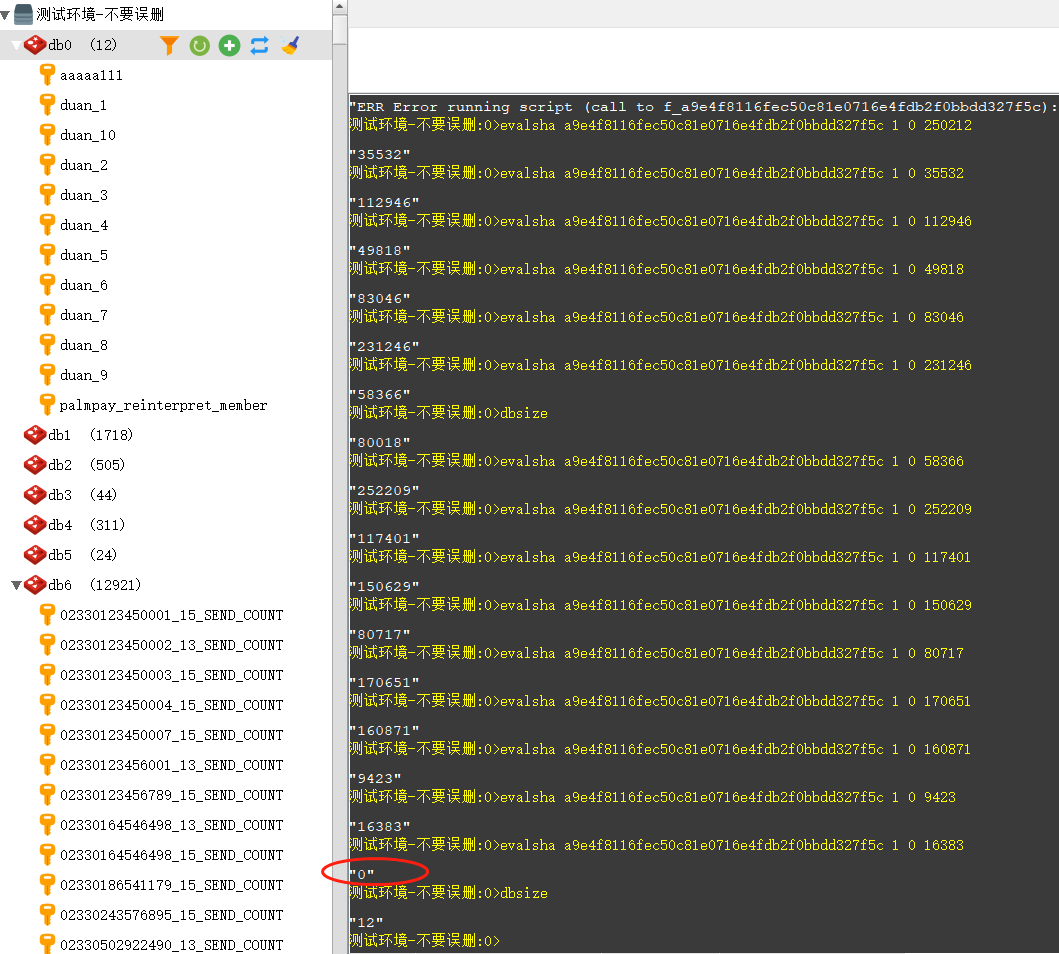
可以看到,scan命令没法完全保证每次筛选的数量完全等同于给定的count,但是整个迭代却很好的延续下去了。最后也得到了游标返回0,也就是到了末尾。至此,测试数据20w被全部删完。
这段lua只要在套上shell进行循环就可以直接在生产上跑了。经过估算大概在12分钟左右能删除掉500w的数据。
知其然,知其所以然。虽然scan命令以前也曾玩过。但是的确不知道其中的细节。况且文档的翻译也不是那么的准确,以至于自己在面对错误的结果时整整浪费了近1个多小时的时间。记录下来,加深理解。
原文链接:https://blog.csdn.net/bryan_zhang_31/article/details/105381999
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
项目实现
语言:shell+lua
shell脚本
redisCom="redis-cli -p 3310 -a password"
start=0
fileNamePre="unUseData_"
time=$(date "+%Y-%m-%d %H:%M:%S")
echo "拆分执行 开始时间:${time} 开始索引 ${start}"
data=`${redisCom} --eval getUnusedData2.0.lua , ${start}`
echo ${data} | sed 's/ / \n/g' > "${fileNamePre}""${start}"
start=`echo ${data} | cut -d ' ' -f1`
time=$(date "+%Y-%m-%d %H:%M:%S")
echo "拆分执行 结束时间:${time}"
while(( $start>0 ))
do
time=$(date "+%Y-%m-%d %H:%M:%S")
echo "拆分执行 开始时间:${time} 开始索引 ${start}"
data=`${redisCom} --eval getUnusedData2.0.lua , ${start}`
echo ${data} | sed 's/ / \n/g' > "${fileNamePre}""${start}"
start=`echo ${data} | cut -d ' ' -f1`
time=$(date "+%Y-%m-%d %H:%M:%S")
echo "拆分执行 结束时间:${time}"
done
time=$(date "+%Y-%m-%d %H:%M:%S")
echo "结束时间:${time}"
shell脚本主要是做一个触发作用,循环调用getUnusedData2.0的LUA脚本。LUA脚本的目的就是每次遍历10000条数据,找到死键,然后做相应处理。返回值如果为0表示redis遍历完毕,都则继续进行遍历。
最后shell将遍历后的结果进行简单切割处理后,存储至文件。
LUA脚本-getUnusedData2.0
-- 获取在临界时间外的数据
local function getUnuseData()
data = nextCycle(start, count, match)
start = tonumber(data[1])
--开始判断
for key,value in pairs(data[2])
do
local curTime = 0
curTime = getIdleTime(value)
if(curTime > maxTime)
then
local delData = {}
delData[1] = value
delData[2] = curTime
delData[3] , delData[4] = getkey(value)
--return delData
--delKey(value)
table.insert(keyData , delData)
--delKey(value)
end
end
return keyData , start
end
具体操作可以查看github源代码
LUA脚本-createRaw
-- 测试使用 为数据库创建随机数据
-- 随机数
local num = 1000000
local function createRaw(num)
local value = math.random(num)
local key = "create_rew_data_"..tostring(math.random(num))
--local value = math.randomseed(num)
--return value
return redis.call("SET" , key, value)
end
math.randomseed(num)
--return num
--return createRaw(num)
for i=num,1,-1
do
createRaw(num)
end
目的是为了测试,在自己测试库中写入随机数据。
项目运行
生成随机数据
redis-cli --eval createRawData.lua
生成63万数据
查找数据
只查找符合要求的数据,因为我们数据都是新生成的,所以我们设置阈值时间为0,一次查找10000条数据。
修改如下:
运行脚本 耗时16s
查找并落地数据+删除
删掉注释,开始删除数据
运行程序,用时26s 原因(生成数据value均为数字,存储很快):
————————————————
版权声明:本文为CSDN博主「genglintong」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_31794773/article/details/82831024
1、需要清理的keys。
未设置ttl的keys,且半年内无访问。
2、redis 删除过期建策略。
Redis删除过期键有两种策略:passive way和active way
- passive way(惰性删除):当客户端访问到过期键时,发现它已过期,Redis会主动删除它
- active way(定期删除):Redis会定期调用删除过期键,调用频率由参数hz控制,默认每秒调用10次
3、获取keys的idletime
127.0.0.1:6379> set aa bb OK 127.0.0.1:6379> object idletime aa (integer) 12 127.0.0.1:6379> get aa # 访问后,idletime会清零 "bb" 127.0.0.1:6379> object idletime aa (integer) 2
4、清理过期的idletime脚本
#!/bin/bash file_dir="/data/tmp" redis-cli -h jkb-hw-prod-apple1 -p 6391 --scan >$file_dir/$port.keys ruleTime='12960000' while read line do storageTime=$(redis-cli -h jkb-hw-prod-apple1 -p 6391 OBJECT IDLETIME ${line}|awk '{print $1}') if [ ! "${storageTime}x" == "x" ];then if [ ${storageTime} -gt ${ruleTime} ];then redis-cli -h jkb-hw-prod-apple1 -p 6391 del ${delKey} fi fi echo "${rowProcessed}" >/data/tmp/record-number.txt done <$file_dir/$port.keys
github地址这个项目是对于redis中的key进行筛选,查找到轮转时间(长期没有使用的时间)大于某个阈值的key,并将它做一些清理落地处理。
参考:
https://www.cnblogs.com/sunshine-long/p/12582681.html