写在前边的话
在看filebeat之前我们先来看下Beats,Beats 平台是 Elastic.co 从 packetbeat 发展出来的数据收集器系统。beat 收集器可以直接写入 Elasticsearch,也可以传输给 Logstash。其中抽象出来的 libbeat,提供了统一的数据发送方法,输入配置解析,日志记录框架等功能。也就是说,所有的 beat 工具,在配置上,除了 input 以外,在output、filter、shipper、logging、run-options 上的配置规则都是完全一致的
而这里的filebeat就是beats 的一员,目前beat可以发送数据给Elasticsearch,Logstash,File,Console四个目的地址。filebeat 是基于原先 logstash-forwarder 的源码改造出来的。换句话说:filebeat 就是新版的 logstash-forwarder,也会是 ELK Stack 在 shipper 端的第一选择。
Filebeat的架构设计
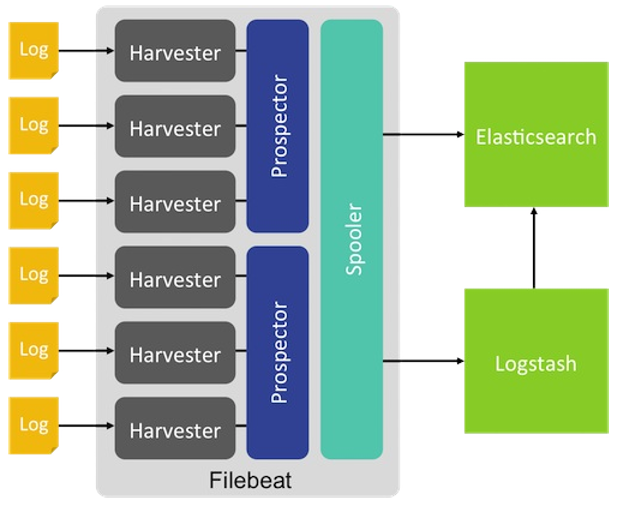
当我们安装完filebeat之后,我们可以在filebeat的安装目录下看到两个文件
filebeat.template.json (输出的文件格式,在filebeat的template中指定,当服务启动时,会被加载)
filebeat.yml(所有的配置都在该文件下进行)
Filebeat由两个主要组成部分组成:prospector和 harvesters。这些组件一起工作来读取文件并将事件数据发送到您指定的output。
什么是harvesters?
harvesters负责读取单个文件的内容。harvesters逐行读取每个文件,并将内容发送到output中。每个文件都将启动一个harvesters。harvesters负责文件的打开和关闭,这意味着harvesters运行时,文件会保持打开状态。如果在收集过程中,即使删除了这个文件或者是对文件进行重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。默认情况下,Filebeat会一直保持文件的开启状态,直到超过配置的close_inactive参数,Filebeat才会把Harvester关闭。
关闭Harvesters会带来的影响:
file Handler将会被关闭,如果在Harvester关闭之前,读取的文件已经被删除或者重命名,这时候会释放之前被占用的磁盘资源。
当时间到达配置的scan_frequency参数,将会重新启动为文件内容的收集。
如果在Havester关闭以后,移动或者删除了文件,Havester再次启动时,将会无法收集文件数据。
当需要关闭Harvester的时候,可以通过close_*配置项来控制。
什么是Prospector?
Prospector负责管理Harvsters,并且找到所有需要进行读取的数据源。如果input type配置的是log类型,Prospector将会去配置度路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。每个Prospector都运行在自己的Go routine里。
Filebeat目前支持两种Prospector类型:log和stdin。每个Prospector类型可以在配置文件定义多个。log Prospector将会检查每一个文件是否需要启动Harvster,启动的Harvster是否还在运行,或者是该文件是否被忽略(可以通过配置 ignore_order,进行文件忽略)。如果是在Filebeat运行过程中新创建的文件,只要在Harvster关闭后,文件大小发生了变化,新文件才会被Prospector选择到。
filebeat工作原理