1、同步代价
同步代码对性能有两个方面的影响。
其一:应用在同步块上所花的时间会影响该应用的可伸缩性。
其二:获取同步锁需要一些CPU周期,所以也会影响性能。
1.1、同步与可伸缩性
当某个应用被分割到多个线程上运行时,加速比(speedup)可以用如下等式定义(即Amdahl定律):
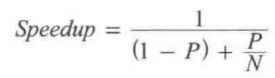
P是程序并行运行部分所花的时间,N是所用到的线程数(假定每个线程总有CPU可用)。
所以,如果20%代码时串行执行的(意味着P是80%),有8个CPU可用,则可以预计存在并发的情况下加速比为3.33。
从这个等式,可以看出一个关键事实,即随着P值得降低(也就是说,有更多代码时串行执行的),引入多个线程所带来的性能优势也会随之下降。限制串行块中的代码量之所以如此重要,原因就在于此。
一个例子:有8个CPU可用,我们可能希望速度提升8倍(8个线程),但是由于有20%的代码串行执行的,此时引入8个多线程的好处并没有提升8倍(只增加了3.33倍)。
1.2、锁定对象的开销
除了对可伸缩性的影响,同步操作本身还有两个基本的开销。
首先是获取同步锁的成本。如果某个锁没有被争用,那么这方面的开销相当小。synchronized和cas指令有轻微差别。非竞争的synchronized锁成为非膨胀(uninflated)锁,获取非膨胀锁的开销在几百纳秒的数量级。非竞争的CAS代码损失会更小。
同步的第二个开销是java特有的,依赖于java内存模型(java memory model)。和C++和C语言不同,java对同步相关的内存语义有严格的保证,而且该保证适用于基于CAS的保护、传统的同步以及volatile关键字。
2、避免同步
两种方法避免 同步:
1、在每个线程中使用不同的对象,这样访问对象时就不存在竞争了。
2、很多java对象创建的成本很高,或者是会占用大量内存。如java.util.Locate实例(国际化),还有NumberFormat实例等。
相反,更好的模式是使用ThreadLocal对象
package com.dxz.thread; import java.text.NumberFormat; public class Thermometer { private static ThreadLocal<NumberFormat> nfLocal = new ThreadLocal<NumberFormat>() { @Override public NumberFormat initialValue() { NumberFormat nf = NumberFormat.getInstance(); nf.setMaximumIntegerDigits(2); return nf; } }; public String toString() { NumberFormat nf = nfLocal.get(); return nf.format(123L); } }
通过使用一个线程局部变量,总的对象数得到了现在(使堆GC的影响最小化),而且每个对象都不会受制于线程竞争。
2、使用基于CAS的替代方案。某种意义上,这不像是避免同步,更像是解决不同的问题,但是在这个背景下,它也可以建设同步带来的性能损失,会得到同样的效果。
基于CAS的保护和传统的同步之间,其差别看上去证适合用微基准测试来测量:编写比较基于CAS的操作和传统同步方法的代码应该并不繁琐。
基于CAS的设施和传统的同步使用原则:
- 如果访问的是不存在竞争的资源,那么基于CAS的保护要稍快于传统的同步(虽然完全不使用保护会更快)。
- 如果访问的资源存在轻度或适度的竞争,那么基于CAS的保护要快于传统的同步(而且往往是快得多)。
- 随着所访问资源的竞争越来越剧烈,在某一时刻,传统的同步就会成为更高效的选择。在实践中,这只会出现在运行着大量线程的非常大型的机器上。
- 当被保护的值有多个读取,但不会被写入时,基于CAS保护不会受竞争的影响。
伪共享
在同步可能的影响方面,有一点很少被讨论到,就是伪共享(false sharing)。在多线程程序中,这个问题过去相当隐蔽,但是随着多核机器成为标配,很多同步性能问题更明显地浮出水面了。伪共享就是一个越来越重要的问题。
伪共享:缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
解决伪共享的办法是使用缓存行填充,具体见:http://www.cnblogs.com/Binhua-Liu/p/5620339.html
Java 8中,可以采用@Contended在类级别上的注释,来进行缓存行填充。
JAVA 6下的方案
解决伪共享的办法是使用缓存行填充,使一个对象占用的内存大小刚好为64bytes或它的整数倍,这样就保证了一个缓存行里不会有多个对象。《剖析Disruptor:为什么会这么快?(三)伪共享》提供了缓存行填充的例子:

public final class FalseSharing
implements Runnable
{
public final static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static
{
for (int i = 0; i < longs.length; i++)
{
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex)
{
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception
{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException
{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads)
{
t.start();
}
for (Thread t : threads)
{
t.join();
}
}
public void run()
{
long i = ITERATIONS + 1;
while (0 != --i)
{
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
}
}
VolatileLong通过填充一些无用的字段p1,p2,p3,p4,p5,p6,再考虑到对象头也占用8bit, 刚好把对象占用的内存扩展到刚好占64bytes(或者64bytes的整数倍)。这样就避免了一个缓存行中加载多个对象。但这个方法现在只能适应JAVA6 及以前的版本了。
(注:如果我们的填充使对象size大于64bytes,比如多填充16bytes– public long p1, p2, p3, p4, p5, p6, p7, p8;。理论上同样应该避免伪共享问题,但事实是这样的话执行速度同样慢几倍,只比没有使用填充好一些而已。还没有理解其原因。所以测试下来,必须是64bytes的整数倍)
JAVA 7下的方案
上面这个例子在JAVA 7下已经不适用了。因为JAVA 7会优化掉无用的字段,可以参考《False Sharing && Java 7》。
因此,JAVA 7下做缓存行填充更麻烦了,需要使用继承的办法来避免填充被优化掉,《False Sharing && Java 7》里的例子我觉得不是很好,于是我自己做了一些优化,使其更通用:
public final class FalseSharing implements Runnable {
public static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
Thread.sleep(10000);
System.out.println("starting....");
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
}
public class VolatileLongPadding {
public volatile long p1, p2, p3, p4, p5, p6; // 注释
}
public class VolatileLong extends VolatileLongPadding {
public volatile long value = 0L;
}
把padding放在基类里面,可以避免优化。(这好像没有什么道理好讲的,JAVA7的内存优化算法问题,能绕则绕)。不过,这种办法怎么看都有点烦,借用另外一个博主的话:做个java程序员真难。
JAVA 8下的方案
在JAVA 8中,缓存行填充终于被JAVA原生支持了。JAVA 8中添加了一个@Contended的注解,添加这个的注解,将会在自动进行缓存行填充。以上的例子可以改为:
public final class FalseSharing implements Runnable {
public static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseSharing(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
Thread.sleep(10000);
System.out.println("starting....");
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
}
import sun.misc.Contended;
@Contended
public class VolatileLong {
public volatile long value = 0L;
}
执行时,必须加上虚拟机参数-XX:-RestrictContended,@Contended注释才会生效。很多文章把这个漏掉了,那样的话实际上就没有起作用。
@Contended注释还可以添加在字段上,见:https://www.cnblogs.com/Binhua-Liu/p/5623089.html