HDFS是存取数据的分布式文件系统,HDFS文件操作常有两种方式,一种是命令行方式,即Hadoop提供了一套与Linux文件命令类似的命令行工具。HDFS操作之一:hdfs命令行操作 另一种是JavaAPI,即利用Hadoop的Java库,采用编程的方式操作HDFS的文件。
要在java工程中操作hdfs,需要引入一下jar包,我的maven工程中的pom.xml文件中增加如下几个依赖:
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>1.3.0</version> <exclusions> <exclusion> <artifactId>jdk.tools</artifactId> <groupId>jdk.tools</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency>
工程里面POM.XML提示了一个错误:Missing artifact jdk.tools:jdk.tools:jar:1.8
进过查找之后发现是如下原因:tools.jar包是JDK自带的,pom.xml中以来的包隐式依赖tools.jar包,而tools.jar并未在库中,
只需要将tools.jar包添加到jdk库中即可。
找到了这样的解决方案:在pom文件中添加如下代码即可。
<dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency>
java代码:
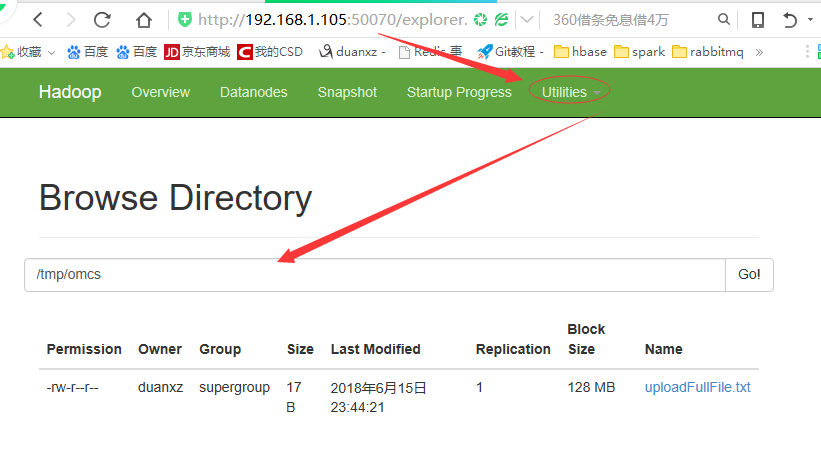
package com.sf.study.hbase; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.net.URI; import java.text.SimpleDateFormat; import java.util.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.LocatedFileStatus; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.RemoteIterator; import org.apache.hadoop.fs.permission.FsPermission; import org.apache.hadoop.hdfs.DistributedFileSystem; public class FileOperateTest { public static DistributedFileSystem dfs=new DistributedFileSystem();; public static String nameNodeUri="hdfs://10.202.33.60:8020"; public static void main(String[] args) throws Exception { FileOperateTest fot = new FileOperateTest(); fot.initFileSystem(); fot.testMkDir(); fot.testDeleteDir(); fot.testFileList(); fot.testUploadFullFile(); fot.testDownloadFile2(); fot.testUploadFile2(); fot.testDownloadFile(); fot.testDownloadFile2(); } public void initFileSystem() throws Exception{ System.out.println("初始化hadoop客户端"); //设置hadoop的登录用户名 System.setProperty("HADOOP_USER_NAME", "hdfs"); //dfs=new DistributedFileSystem(); dfs.initialize(new URI(nameNodeUri), new Configuration()); System.out.println("客户端连接成功"); Path workingDirectory = dfs.getWorkingDirectory(); System.out.println("工作目录:"+workingDirectory); } /** * 创建文件夹 * @throws Exception */ public void testMkDir() throws Exception{ boolean res = dfs.mkdirs(new Path("/tmp/omcs/bbb")); System.out.println("目录创建结果:"+(res?"创建成功":"创建失败")); } /** * 删除目录/文件 * @throws Exception */ //@Test public void testDeleteDir() throws Exception{ dfs.delete(new Path("/tmp/omcs/bbb"), false); } /** * 获取指定目录下所有文件(忽略目录) * @throws Exception * @throws IllegalArgumentException * @throws FileNotFoundException */ public void testFileList() throws Exception{ RemoteIterator<LocatedFileStatus> listFiles = dfs.listFiles(new Path("/"), true); SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); while (listFiles.hasNext()) { LocatedFileStatus fileStatus = (LocatedFileStatus) listFiles.next(); //权限 FsPermission permission = fileStatus.getPermission(); //拥有者 String owner = fileStatus.getOwner(); //组 String group = fileStatus.getGroup(); //文件大小byte long len = fileStatus.getLen(); long modificationTime = fileStatus.getModificationTime(); Path path = fileStatus.getPath(); System.out.println("-------------------------------"); System.out.println("permission:"+permission); System.out.println("owner:"+owner); System.out.println("group:"+group); System.out.println("len:"+len); System.out.println("modificationTime:"+sdf.format(new Date(modificationTime))); System.out.println("path:"+path); } } /** * 【完整】文件上传 * 注意:文件上传在Window开发环境下,使用apache-common提供的<code>org.apache.commons.io.IOUtils.copy</code>可能存在问题 */ //@Test public void testUploadFullFile() throws Exception{ FSDataOutputStream out = dfs.create(new Path("/tmp/omcs/uploadFile.txt"), true); // InputStream in = FileOperate.class.getResourceAsStream("uploadFile.txt"); FileInputStream in = new FileInputStream(FileOperate.class.getResource("uploadFile.txt").getFile()); org.apache.commons.io.IOUtils.copy(in, out); System.out.println("上传完毕"); } /** * 【完整】文件上传 */ //@Test public void testUploadFullFile2() throws Exception{ dfs.copyFromLocalFile(new Path(FileOperate.class.getResource("uploadFile.txt").getFile()), new Path("/tmp/omcs/uploadFullFile.txt")); } /** * 【分段|部分】文件上传 * 注意:文件上传在Window开发环境下,使用apache-common提供的<code>org.apache.commons.io.IOUtils.copy</code>可能存在问题 */ //@Test public void testUploadFile2() throws Exception{ FSDataOutputStream out = dfs.create(new Path("/tmp/omcs/uploadFile2.txt"), true); FileInputStream in = new FileInputStream(FileOperate.class.getResource("uploadFile.txt").getFile()); org.apache.commons.io.IOUtils.copyLarge(in, out, 6, 12); System.out.println("上传完毕"); } /** * 【完整】下载文件 * 注意:windows开发平台下,使用如下API */ public void testDownloadFile() throws Exception{ //使用Java API进行I/O,设置useRawLocalFileSystem=true dfs.copyToLocalFile(false,new Path("/tmp/omcs/uploadFullFile.txt"), new Path("E:/Workspaces/MyEclipse2014_BigData/hadoop-demo/src/com/xbz/bigdata/hadoop/demo"),true); System.out.println("下载完成"); } /** * 【部分】下载文件 */ public void testDownloadFile2() throws Exception{ //使用Java API进行I/O,设置useRawLocalFileSystem=true FSDataInputStream src = dfs.open(new Path("/tmp/omcs/uploadFullFile.txt")); FileOutputStream des = new FileOutputStream(new File("E:/Workspaces/MyEclipse2014_BigData/hadoop-demo/src/com/xbz/bigdata/hadoop/demo","download_uploadFullFile.txt")); src.seek(6); org.apache.commons.io.IOUtils.copy(src, des); System.out.println("下载完成"); } }
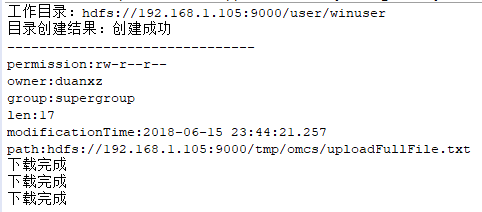
结果:
客户端连接成功
工作目录:hdfs://10.202.34.200:8020/user/hdfs
目录创建结果:创建成功
-------------------------------
permission:rw-r--r--
owner:hdfs
group:supergroup
len:0
modificationTime:2017-03-01 10:00:56.156
path:hdfs://10.202.34.200:8020/hbase/MasterProcWALs/state-00000000000000000190.log
...
...
Q:客户端连不上HDFS,用telnet也连不上,在hadoop机器上用netstat -tpnl查看结果如下:
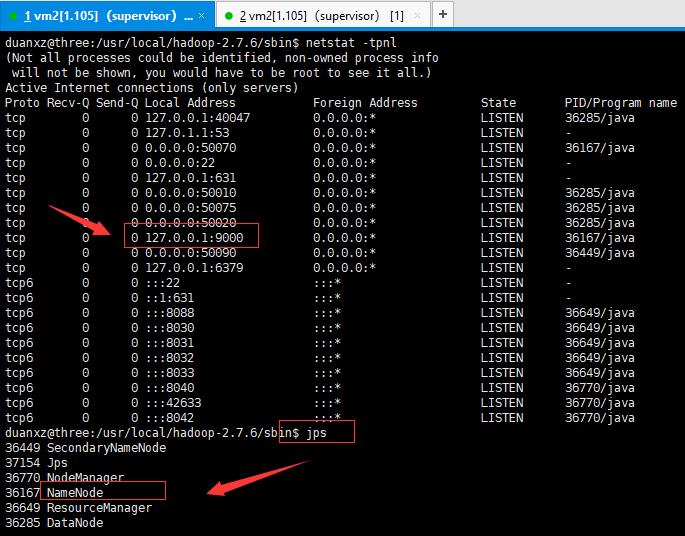
解决办法见:
Q:报如下错误:
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=winuser, access=WRITE, inode="/":duanxz:supergroup:drwxr-xr-x
解决方案:
org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
其实这个错误的原因很容易看出来,用户Administator在hadoop上执行写操作时被权限系统拒绝.
解决问题的过程
看到这个错误的,第一步就是将这个错误直接入放到百度google里面进行搜索。找到了N多篇文章,但是主要的思路就如此篇文章所写的两个解决办法:http://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
1、在hdfs的配置文件中,将dfs.permissions修改为False
2、执行这样的操作 hadoop fs -chmod 777 /user/hadoop
对于上面的第一个方法,我试了行不通,不知道是自己设置错误还是其他原因,对我此法不可行,第二个方法可行。第二个方法是让我们来修改HDFS中相应文件夹的权限,后面的/user/hadoop这个路径为HDFS中的文件路径,这样修改之后就让我们的administrator有在HDFS的相应目录下有写文件的权限(所有的用户都是写权限)。
虽然上面的第二步可以解决问题了,上传之后的文件所有者为Administrator,但是总感觉这样的方法不够优雅,而且这样修改权限会有一定的安全问题,总之就是看着不爽,就在想有没有其他的办法?
问题分析
开始仔细的观察了这个错误的详细信息,看到user=Administrator, access=WRITE。这里的user其实是我当前系统(运行客户端的计算机的操作系统)的用户名,实际期望这里的user=hadoop(hadoop是我的HADOOP上面的用户名),但是它取的是当前的系统的用户名,很明显,如果我将当前系统的用户名改为hadoop,这个肯定也是可以行得通的,但是如果后期将开发的代码部署到服务器上之后,就不能方便的修改用户,此方法明显也不够方便。
现在就想着Configuration这个是一个配置类,有没有一个参数是可以在某个地方设置以哪个用户运行呢?搜索了半天,无果。没有找到相关的配置参数。
最终只有继续分析代码, FileSystem fs = FileSystem.get(URI.create(dest), conf);代码是在此处开始对HDFS进行调用,所以就想着将HADOOP的源码下下来,debug整个调用过程,这个user=Administator是在什么时间赋予的值。理解了调用过程,还怕找不到解决问题的办法么?
跟踪代码进入 FileSystem.get-->CACHE.get()-->Key key = new Key(uri, conf);到这里的时候发现key值里面已经有Administrator了,所以关键肯定是在new key的过程。继续跟踪UserGroupInformation.getCurrentUser()-->getLoginUser()-->login.login()到这一步的时候发现用户名已经确定了,但是这个方法是Java的核心源码,是一个通用的安全认证,但对这一块不熟悉,但是debug时看到subject里面有NTUserPrincipal:Administator,所以就想着搜索一下这个东西是啥,结果就找到了下面这一篇关键的文章:
http://www.udpwork.com/item/7047.html
结果:

Q:datanode没有正常启动(java.io.IOException: All specified directories are failed to load)
导致hadoop fs -put localfile /tmp失败
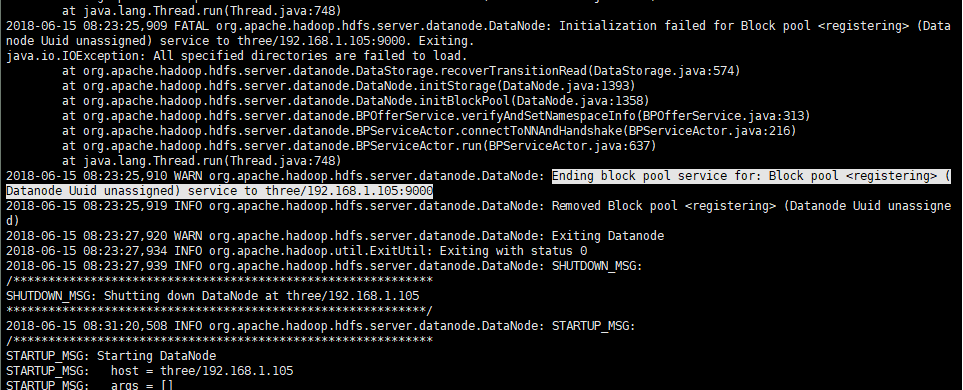
提醒两个cid不一致,原因是Hadoop启动后,在使用格式化namenode,会导致datanode和namenode的clusterID不一致
同时,给我提示的目录是/home/hadoop/app/tmp/dfs/data
所以我对第一反应是tmp下文件未覆盖。所以,解决方案是将tmp文件夹删除后,重新格式化hdfs即可。
检验的方式是在格式化之后,再次启动hdfs。jps一下看看当前进程是否包含namenode
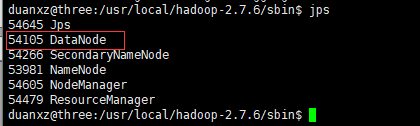
java程序执行结果: