在第一篇分享中我们介绍了可靠事件模式属于事件驱动架构,微服务完成业务操作后向消息代理发布事件,关联的微服务从消息代理订阅到该事件从而完成相应的业务操作。
我们还强调了实现可靠事件模式的关键在于:可靠事件投递和避免事件重复消费。

可靠事件投递定义为:
(a)每个服务原子性的完成业务操作和发布事件
(b)消息代理确保事件投递至少一次。
避免重复消费要求消费事件的服务实现幂等性。
因为现在流行的消息队列都实现了事件的持久化和at leastonce的投递模式,(b)特性(消息代理确保事件投递至少一次)已经满足,今天不做展开。
一、投递事件存在的问题
下面分享的内容主要从可靠事件投递和实现幂等性两方面来讨论,我们先来看可靠事件投递。
首先我们来看一个实现的代码片段,这是从某生产系统上截取下来的。
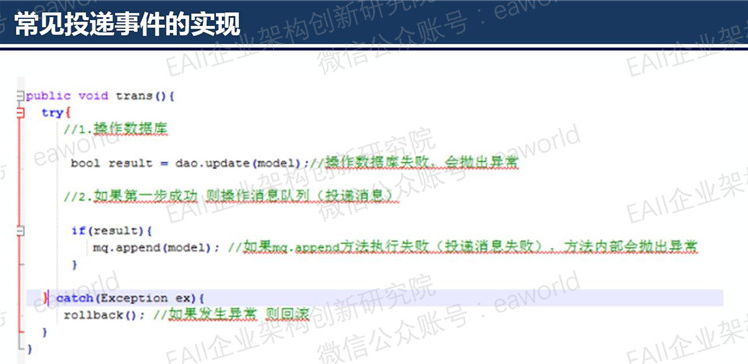
根据上述代码及注释,初看可能出现3种情况:
1.操作数据库成功,向消息代理投递事件也成功
2.操作数据库失败,不会向消息代理中投递事件了
3.操作数据库成功,但是向消息代理中投递事件时失败,向外抛出了异常,刚刚执行的更新数据库的操作将被回滚。
从上面分析的几种情况来看,貌似没有问题。但是仔细分析不难发现缺陷所在,在上面的处理过程中存在一段隐患时间窗口。
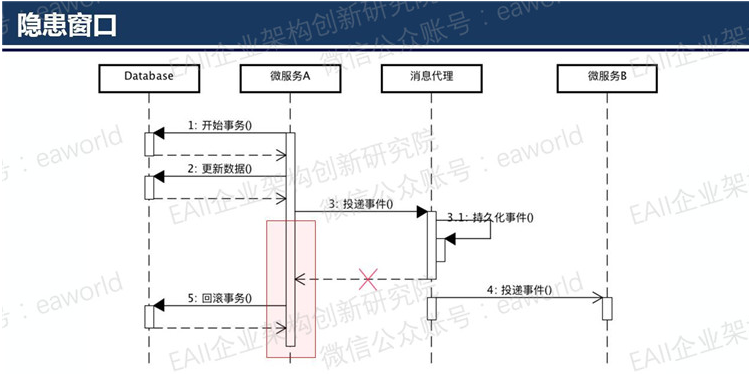
1) 微服务A投递事件的时候可能消息代理已经处理成功,但是返回响应的时候网络异常,导致append操作抛出异常。最终结果是事件被投递,数据库确被回滚。

2) 在投递完成后到数据库commit操作之间如果微服务A宕机也将造成数据库操作因为连接异常关闭而被回滚。最终结果还是事件被投递,数据库却被回滚。
这个实现往往运行很长时间都没有出过问题,但是一旦出现了将会让人感觉莫名很难发现问题所在。
三、下面给出两种可靠事件投递的实现方式
3.1、本地事件表
本地事件表方法将事件和业务数据保存在同一个数据库中,使用一个额外的“事件恢复”服务来恢复事件,由本地事务保证更新业务和发布事件的原子性。考虑到事件恢复可能会有一定的延时,服务在完成本地事务后可立即向消息代理发布一个事件。

1. 微服务在同一个本地事务中记录业务数据和事件。
2. 微服务实时发布一个事件立即通知关联的业务服务,如果事件发布成功立即删除记录的事件。
3. 事件恢复服务定时从事件表中恢复未发布成功的事件,重新发布,重新发布成功才删除记录的事件。
其中第2条的操作主要是为了增加发布事件的实时性,由第三条保证事件一定被发布。
本地事件表方式业务系统和事件系统耦合比较紧密,额外的事件数据库操作也会给数据库带来额外的压力,可能成为瓶颈。
3.2、外部事件表
外部事件表方法将事件持久化到外部的事件系统,事件系统需提供实时事件服务以接受微服务发布事件,同时事件系统还需要提供事件恢复服务来确认和恢复事件。
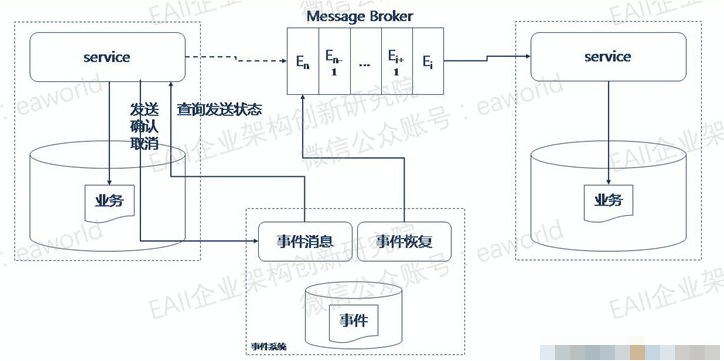
1.业务服务在事务提交前,通过实时事件服务向事件系统请求发送事件,事件系统只记录事件并不真正发送。
2.业务服务在提交后,通过实时事件服务向事件系统确认发送,事件得到确认后事件系统才真正发布事件到消息代理。
3.业务服务在业务回滚时,通过实时事件向事件系统取消事件。
4.如果业务服务在发送确认或取消之前停止服务了怎么办呢?事件系统的事件恢复服务会定期找到未确认发送的事件向业务服务查询状态,根据业务服务返回的状态决定事件是要发布还是取消。
该方式将业务系统和事件系统独立解耦,都可以独立伸缩。但是这种方式需要一次额外的发送操作,并且需要发布者提供额外的查询接口。介绍完了可靠事件投递再来说一说幂等性的实现,有些事件本身是幂等的,有些事件却不是。
四、幂等性
4.1、本身具有幂等性的事件需要考虑执行顺序
如果事件本身描述的是某个时间点的固定值(如账户余额为100),而不是描述一条转换指令(如余额增加10),那么这个事件是幂等的。
我们要意识到事件可能出现的次数和顺序是不可预测的,需要保证幂等事件的顺序执行,否则结果往往不是我们想要的。
如果我们先后收到两条事件,(1)账户余额更新为100,(2)账户余额更新为120。
1.微服务收到事件(1)

2. 微服务收到事件(2)

3. 微服务再次收到事件1

显然结果是错误的,所以我们需要保证事件(2)一旦执行事件(1)就不能再处理,否则账户余额仍不是我们想要的结果。
为保证事件的顺序一个简单的做法是在事件中添加时间戳,微服务记录每类型的事件最后处理的时间戳,如果收到的事件的时间戳早于我们记录的,丢弃该事件。
如果事件不是在同一个服务器上发出的,那么服务器之间的时间同步是个难题,更稳妥的做法是使用一个全局递增序列号替换时间戳。
对于本身不具有幂等性的操作,主要思想是为每条事件存储执行结果,当收到一条事件时我们需要根据事件的id查询该事件是否已经执行过,如果执行过直接返回上一次的执行结果,否则调度执行事件。
4.2、重复处理开销大事件,使用事件存储过滤重复事件
事件过滤保证幂等性
在这个思想下我们需要考虑重复执行一条事件和查询存储结果的开销。
4.3、重复处理开销小的事件重复处理

如果重复处理一条事件的开销相比额外一次查询的开销要高很多,使用一个过滤服务来过滤重复的事件,过滤服务使用事件存储存储已经处理过的事件和结果。
当收到一条事件时,过滤服务首先查询事件存储,确定该条事件是否已经被处理过,如果事件已经被处理过,直接返回存储的结果;否则调度业务服务执行处理,并将处理完的结果存储到事件存储中。
一般情况下上面的方法能够运行得很好,如果我们的微服务是RPC类的服务我们需要更加小心,可能出现的问题在于,(1)过滤服务在业务处理完成后才将事件结果存储到事件存储中,但是在业务处理完成前有可能就已经收到重复事件,由于是RPC服务也不能依赖数据库的唯一性约束;(2)业务服务的处理结果可能出现位置状态,一般出现在正常提交请求但是没有收到响应的时候。
对于问题(1)可以按步骤记录事件处理过程,比如事件的记录事件的处理过程为“接收”、“发送请求”、“收到应答”、“处理完成”。好处是过滤服务能及时的发现重复事件,进一步还能根据事件状态作不同的处理。
对于问题(2)可以通过一次额外的查询请求来确定事件的实际处理状态,要注意额外的查询会带来更长时间的延时,更进一步可能某些RPC服务根本不提供查询接口。此时只能选择接收暂时的不一致,时候采用对账和人工接入的方式来保证一致性。
需要注意的是上面的幂等处理方法要求事件必须有唯一的ID(这个ID一般是业务相关的),比如用ID来保证数据库的唯一性约束;使用事件ID来确认事件是否已经被处理;使用事件ID来查询RPC服务的事件处理结果。
转自:http://www.primeton.com/read.php?id=2195&his=1