在分布式系统中,生成全局唯一ID,有很多种方案,但是在这多种方案中,每种方案都有有缺点,下面我们之针对通过常用数据库来生成分布式ID的方案,其它方法会在其它文中讨论:
1,RDBMS生成ID:
这里我们讨论mysql生成ID。因为MySQL本身可以auto_increment和auto_increment_offset来保证ID自增,很自然地,我们会想到借助这个特性来实现这个功能。
全局ID生成方案里采用了MySQL自增长ID的机制(auto_increment + replace into + MyISAM)。一个生成64位ID方案具体实现是这样的:
先创建单独的数据库(eg:ticket),然后创建一个表:
CREATE TABLE Tickets64 ( id bigint(20) unsigned NOT NULL auto_increment, stub char(1) NOT NULL default '', PRIMARY KEY (id), UNIQUE KEY stub (stub) ) ENGINE=MyISAM
表创建之后我们要设置一个初始值,比如100000,执行SELECT * from Tickets64,查询结果就是这样的:
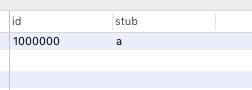
每当我们的应用需要ID的时候就会做如下操作,调用如下存储过程:
begin; REPLACE INTO Tickets64 (stub) VALUES ('a'); SELECT LAST_INSERT_ID(); commit;
架构如图:
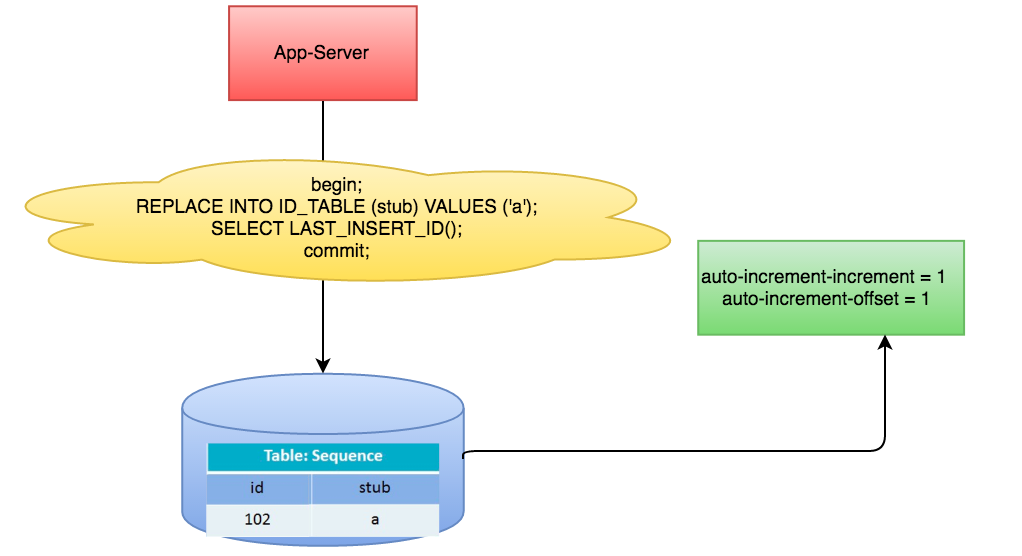
这样我们就能拿到不断增长且不重复的ID了。
这种方案的优缺点如下:
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
对于MySQL性能问题,可用如下方案解决:在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11...)、TicketServer2的初始值为2(2,4,6,8,10...)。这是Flickr团队在2010年撰文介绍的一种主键生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap )。如下所示,为了实现上述方案分别设置两台机器对应的参数,TicketServer1从1开始发号,TicketServer2从2开始发号,两台机器每次发号之后都递增2。
TicketServer1: auto-increment-increment = 2 auto-increment-offset = 1 TicketServer2: auto-increment-increment = 2 auto-increment-offset = 2
假设我们要部署N台机器,步长需设置为N,每台的初始值依次为0,1,2...N-1那么整个架构就变成了如下图所示:
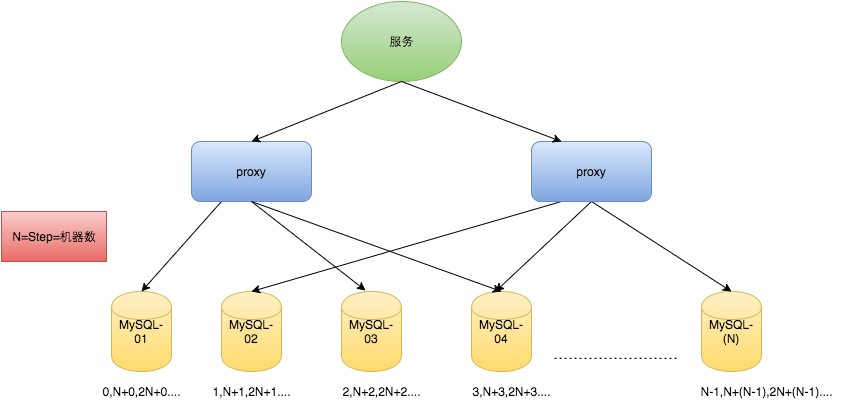
这种架构貌似能够满足性能的需求,但有以下几个缺点:
- 系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶数。然后摘掉第一台,把ID值保留为奇数,比如7,然后修改第一台的步长为2。让它符合我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
- ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍。
- 数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能。
2,类snowflake方案
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
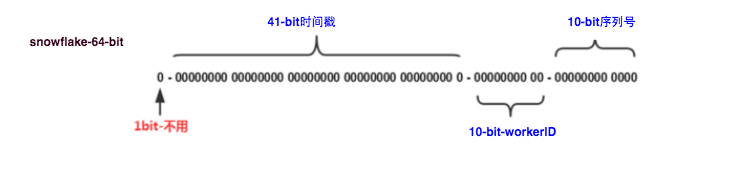
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
以Mongdb objectID为例:
MongoDB官方文档 ObjectID可以算作是和snowflake类似方法:
为了考虑分布式,“_id”要求不同的机器都能用全局唯一的同种方法方便的生成它。因此不能使用自增主键(需要多台服务器进行同步,既费时又费力),
因此选用了生成ObjectId对象的方法。
ObjectId使用12字节的存储空间,其生成方式如下:
|0|1|2|3|4|5|6 |7|8|9|10|11|
|时间戳 |机器ID|PID|计数器 |
前四个字节时间戳是从标准纪元开始的时间戳,单位为秒,有如下特性:
1 时间戳与后边5个字节一块,保证秒级别的唯一性;
2 保证插入顺序大致按时间排序;
3 隐含了文档创建时间;
4 时间戳的实际值并不重要,不需要对服务器之间的时间进行同步(因为加上机器ID和进程ID已保证此值唯一,唯一性是ObjectId的最终诉求)。
机器ID是服务器主机标识,通常是机器主机名的散列值。
同一台机器上可以运行多个mongod实例,因此也需要加入进程标识符PID。
前9个字节保证了同一秒钟不同机器不同进程产生的ObjectId的唯一性。后三个字节是一个自动增加的计数器(一个mongod进程需要一个全局的计数器),保证同一秒的ObjectId是唯一的。同一秒钟最多允许每个进程拥有(256^3 = 16777216)个不同的ObjectId。
总结一下:时间戳保证秒级唯一,机器ID保证设计时考虑分布式,避免时钟同步,PID保证同一台服务器运行多个mongod实例时的唯一性,最后的计数器保证同一秒内的唯一性(选用几个字节既要考虑存储的经济性,也要考虑并发性能的上限)。
"_id"既可以在服务器端生成也可以在客户端生成,在客户端生成可以降低服务器端的压力。
3,使用Redis来生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
参考:https://tech.meituan.com/MT_Leaf.html