目前全球疫情仍然比较严重,为了能清晰地看到疫情爆发以来至现在全球疫情的变化趋势,我绘制了一张疫情变化地图,完整代码共 230 行,需要的朋友在公众号回复关键字 疫情地图 即可。 废话不多说,先上图
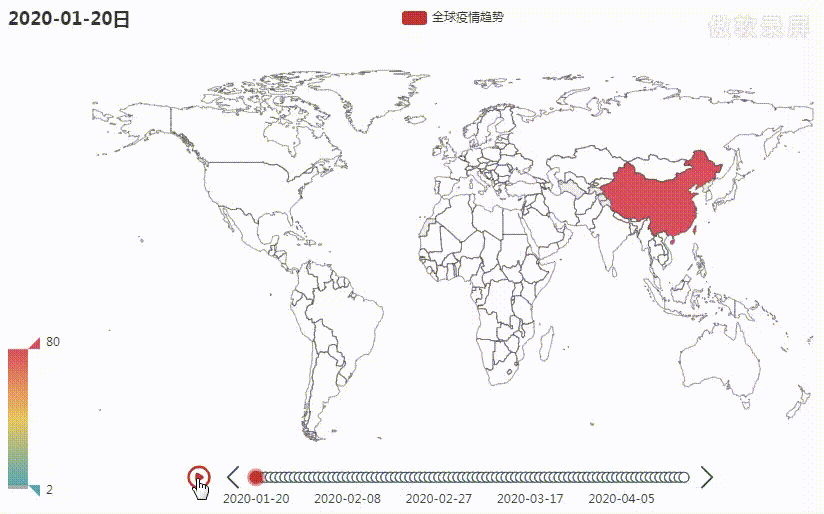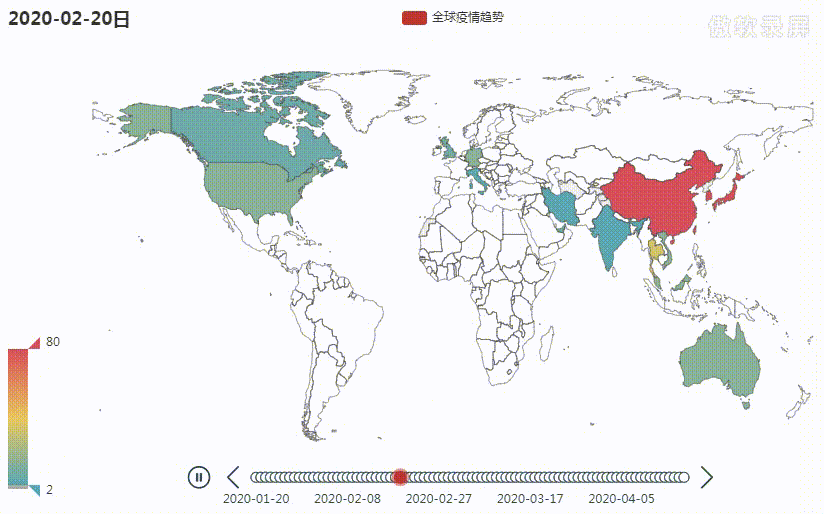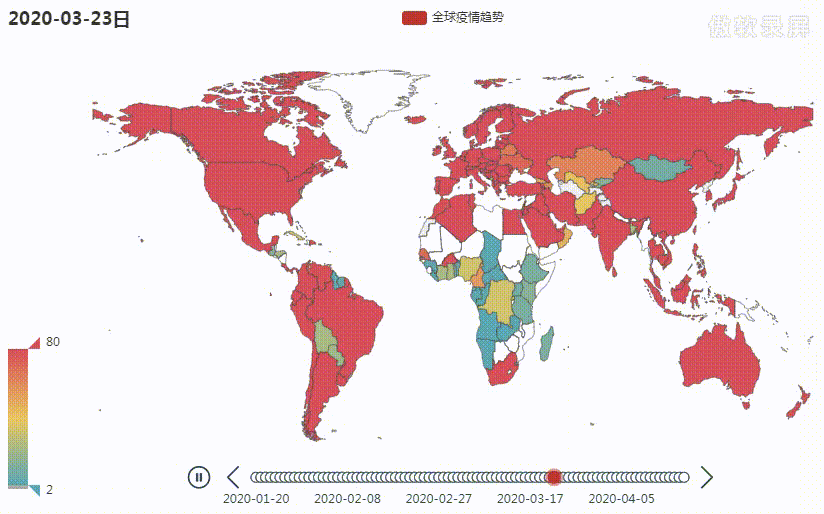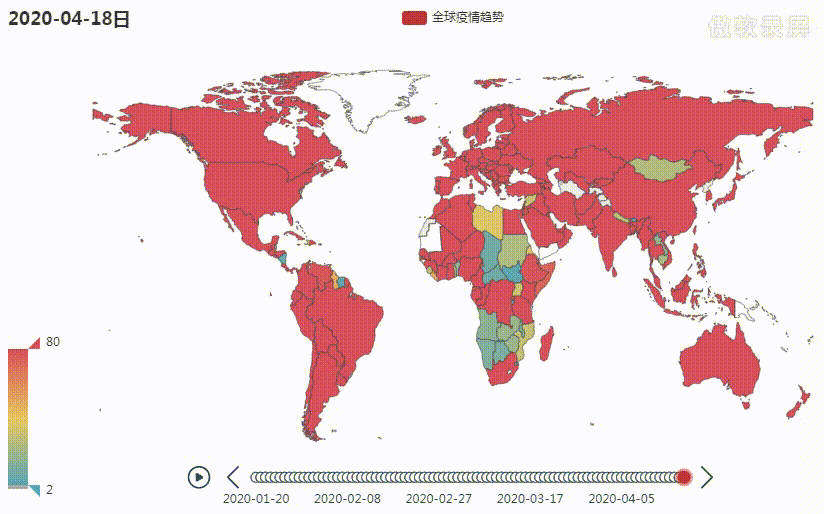
下面就来重点介绍下上面这张图的绘制过程,主要分为以下三个步骤:
-
数据收集
-
数据处理
-
画图
下面一个一个来说。
数据收集
这是万里长城的第一步,俗话说“巧妇难为无米之炊”,既然是变化图,当然需要每个国家、每天的现有确诊病例数。好在现在各大网站都有疫情相关的专题页,我们可以直接抓数据。以网易为例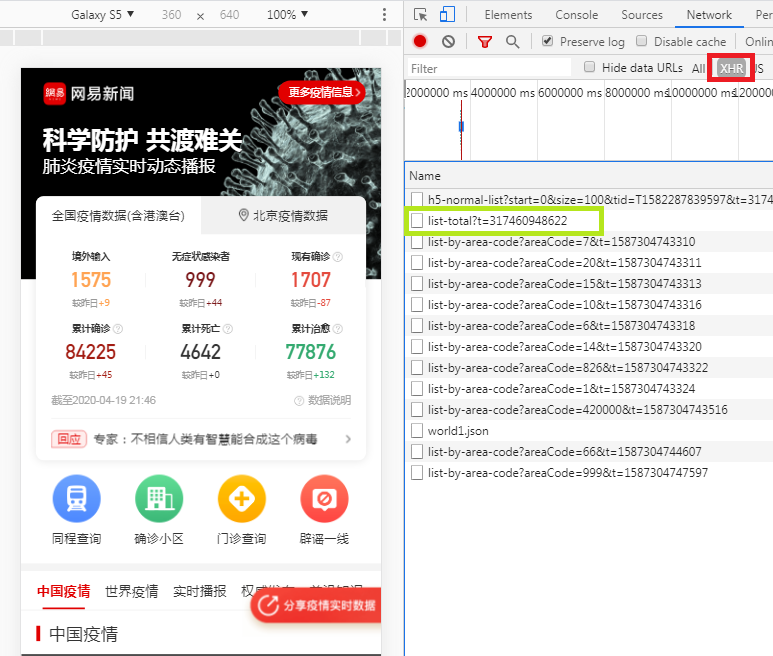
我们选择 XHR,重新刷新下网页可以看到有几个接口,其中 list-total 接口是获取当前所有有疫情的国家,以及对应的国家id。另外,我们看到还有一个 list-by-area-code 接口,它是获取每个国家历史上每天的疫情数据,请求这个接口需要带 areaCode 参数,这个参数就是我们刚刚说的国家id。所以对我们来说这两个接口是最重要的。下面我们就看看请求 list-total 接口的代码
def get_and_save_all_countries(): """ 获取所有的国家名以及对应的id,保存为文件 """ url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total?t=317452696323' list_total_req = requests.get(url, headers=headers) if list_total_req.status_code == 200: area_tree = list_total_req.json()['data']['areaTree'] area_dict = {} for area in area_tree: country_id = area['id'] name = area['name'] area_dict[country_id] = name area_json = json.dumps(area_dict, ensure_ascii=False) # ensure_ascii=False 防止json编码后中文编程u开头的字符 write_file('./config/countries_id2name.json', area_json)
这里将请求下来的数据临时存放在文件里。有了所有的疫情国家的id,我们就可以请求 list-by-area-code 接口来获取每个国家的疫情数据了。代码与上面的类似,不同的是将请求结果存在了 mongodb 而不是文件,目的是为了方便增删改查。当然为了大家方便使用,我将mongodb中的数据导入了文件 counties_daily.json 中,大家可以在源码根目录找到它。
数据处理
这一步的处理主要是为第三步画图做准备的。因为我们画图用的是pyecharts框架,它绘制世界地图需要输入的国家名是英文的,而我们收集的国家名是中文的,所以要将中文国家名对应到英文国家名。最终的效果如下

网上能找到这样的对应关系,但想要用起来还需要解决两个问题。第一,两边中文名统一,比如:我们收集的国家名是中非共和国,而对应关系里是中非,那还是对应不上。第二,需要自己增加映射关系,网上找的一般都不全,我们需要根据收集的数据自行增加。经过上面两个步骤处理后,我们就可以将大部分国家名对应到pyechars能识别的英文名了。相关代码如下
def get_cy_properties(): # 获取配置文件信息 countries_id2name = read_file('./config/countries_id2name.json') cy_id2name_dict = json.loads(countries_id2name) cy_ch2en = {v: k for k, v in countries_dict.items()} # 调整国家的名字与配置文件一致 cy_id2name_dict['879'] = '波斯尼亚和黑塞哥维那' cy_id2name_dict['8102'] = '多哥' cy_id2name_dict['8143'] = '刚果民主共和国' cy_id2name_dict['95983'] = '刚果' cy_id2name_dict['8144'] = '中非' cy_id2name_dict['95000011'] = '多米尼加' cy_props = {} for key in cy_id2name_dict: cy_name = cy_id2name_dict[key] if cy_name in cy_ch2en: cy_props[cy_name] = {} cy_props[cy_name]['id'] = key cy_props[cy_name]['en_name'] = cy_ch2en[cy_name] return cy_props
画图
这一步涉及到两个核心过程——构造数据结构和画图。首先,我构造了3个数据结构,分别是date_list、cy_name_list 和 ncov_data。date_list存放的是日期列表,因为我们画动图,所以需要一段时间;cy_name_list 存放收集的所有国家列表(英文名);ncov_data是一个字典,key是日期,value是数组,存放各个国家当天的确诊病例数。生成这三个数据结构的代码如下
def parse_ncov_data(start_date, end_date, records): if not records: return date_list = get_date_range(start_date, end_date) cy_name_list = [] res = {} # 获取各国每天现有确认病例 for i, record in enumerate(records): cy_name = record['cy_en_name'] cy_name_list.append(cy_name) # 解析每天数据并计算现有确认病例 existing_case_dict = {} for ncov_daily in record['data']['list']: date_str = ncov_daily['date'] confirm = ncov_daily['total']['confirm'] # 累计确诊 heal = ncov_daily['total']['heal'] # 累计确诊 dead = ncov_daily['total']['dead'] # 累计死亡 existing_case = confirm - heal - dead existing_case_dict[date_str] = existing_case last_existing_case = 0 # 将每天确诊病例数合并到res中 for date_str in date_list: if date_str not in res: # 初始化 res[date_str] = [] existing_case = existing_case_dict.get(date_str) if existing_case is None: existing_case = last_existing_case res[date_str].append(existing_case) last_existing_case = existing_case return date_list, cy_name_list, res
参数 records 是一个数组,数组每个元素代表一个国家,内容便是我们在第一步请求 list-by-area-code 接口的数据。最后,用 pyecharts 来画图,直接上代码
def render_map(date_list, cy_name_list, ncov_data): tl = Timeline() # 创建时间线轮播多图,可以让图形按照输入的时间动起来 # is_auto_play:自动播放 # play_interval:播放时间间隔,单位:毫秒 # is_loop_play:是否循环播放 tl.add_schema(is_auto_play=True, play_interval=50, is_loop_play=False) for date_str in date_list: # 遍历时间列表 map0 = ( Map() # 创建地图图表 # 将国家名 cy_name_list 以及各国当天确诊病例 ncov_data[date_str] 加入地图中 .add("全球疫情趋势", [list(z) for z in zip(cy_name_list, ncov_data[date_str])], "world", is_map_symbol_show=False) .set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不显示国家名 .set_global_opts( title_opts=opts.TitleOpts(title="%s日" % date_str), # 图表标题 visualmap_opts=opts.VisualMapOpts(max_=80), # 当确诊病例大于80 ,地图颜色是红色 ) ) tl.add(map0, "%s" % date_str) # 将当天的地图状态加入时间线中 tl.render() # 生成最终轮播多图,会在当前目录创建 render.html 文件
代码里加了注释,这里就不再赘述了。
运行 render_map 函数会在当前目录生成 render.html 文件,打开后便自动播放疫情变化趋势,如文章开头 gif。另外,有些朋友可能会问,能不能直接输出 gif。这一点我也尝试过,百度、谷歌、GitHub上的教程基本上都试了一遍,比较遗憾没有找到靠谱的方法。所以劝大家还是放弃这条路,曲线救国,录制一个视频转成 gif 即可,方便快捷。毕竟人生苦短,Python 为我们节省下的时间不能再被这些无谓的坑再填回去。这样整个过程就介绍完了,虽然思路不复杂,但局部细节上还是需要花一些时间处理的。完整代码共 230 行,需要的朋友在公众号回复关键字 疫情地图 即可。
最近国内某些地方出现了反弹的迹象,希望大家无论是在工作还是生活上都能继续保持警惕。希望这次疫情早点过去,等待全球地图变白的那一天。
欢迎公众号「渡码」,输出别地儿看不到的干货。
