不想看废话的可以直接拉到最底看总结
废话开始:
master:
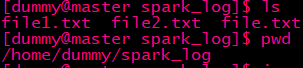
master主机存在文件,却报

执行spark-shell语句: ./spark-shell --master spark://master:7077 --executor-memory 1G --total-executor-cores 2
报错:WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, slave02): java.io.FileNotFoundException: File file:/home/dummy/spark_log/file1.txt does not exist
明明指定了master主机,为什么会报错slave02找不到文件呢
把文件改为file.txt file2.txt还是同样的错误,所以你就会觉得他是从slave02读取文件的吧?
那就在slave02创建个aa.txt:
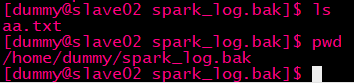
返回master执行

然后报错

导入路径找到不?这是很多新手就懵逼了
其实原因在于最初的执行spark-shell语句: ./spark-shell --master spark://master:7077 --executor-memory 1G --total-executor-cores 2
每个主机的executor默认是一个core ! 这里设置为2个,就会从其他主机拉取一个core
用jps查看3台主机的进程:
master:

slave01:

slave02:

CoarseGrainedExecutorBackend是什么?
我们知道Executor负责计算任务,即执行task,而Executor对象的创建及维护是由CoarseGrainedExecutorBackend负责的
总结:
在spark-shell里执行textFile方法时,如果total-executor-cores设置为N,哪N台机有CoarseGrainedExecutorBackend进程的,读取的文件需要在这N台机都存在
如果设置为1,就读取指定的master spark的文件
如果只执行 ./spark-shell 就读取启动命令的主机的文件,即在哪台机启动就读取哪台机
以上仅为个人小白的观点,如有错误,欢迎纠正!