Hbase是什么
HBase是一个分布式的、面向列的开源数据库,是一个NoSQL数据库,它是基于列的而不是基于行的模式,
是一个高可用、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群
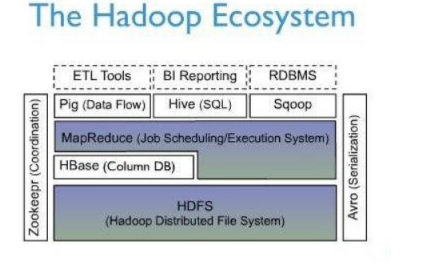
上图描述了Hadoop EcoSystem中的各层系统,其中HBase位于结构化存储层,
Hadoop HDFS为HBase提供了高可靠性的底层存储支持,
Hadoop MapReduce为HBase提供了高性能的计算能力,
Zookeeper为HBase提供了稳定服务和failover机制。
Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。
Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
而Hbase是基于hadoop的一个分布式NoSQL数据库。
因为hadoop查询数据很慢。
传统的比如MySQL,增加字段不方便,比如当表运行一定时间的时候,突然想对某个数据增加一个字段,那么alter table的时候,会给整个表增加字段,这样及其不方便。
存储数据也是以行的概念来存储,但是不具备列的概念,也就是没有字段的概念。这样和MySQL有很大的不同。
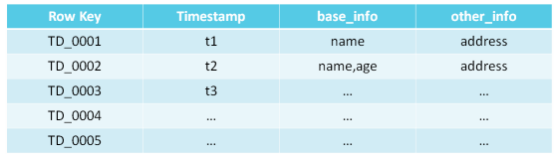
定义列族:必须定义。每一行都有一个rowKey,这个可以将其看成为一个主键,它不需要定义,这个会rowkey会创建的时候需要手动生成。行键(rowkey)是唯一性的。这也是每一行唯一的一个固定字段。
每一行的列族可以存储多个键值对,上下行的键值对可以不相等。
键值对修改的时候,value可以保存多个版本的信息,默认保留1份,例如:
Name:A------最初的value=A
:B------后期修改为value=B
这些修改的版本name:A和name:B都会保存起来。
一行内部数据按照key进行字典排序,行与行之间根据rowkey进行排序。在Habse里面没有数据类型,所有的数据都会被变成字
Hbase与RDBMS区别
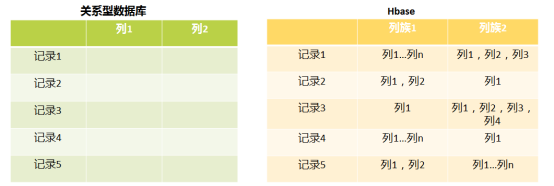
Hbase的数据模型