Linux vmstat命令详解
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。它是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。vmstat工具提供了一种低开销的系统性能观察方式。因为vmstat本身就是低开销工具,在非常高负荷的服务器上,你需要查看并监控系统的健康情况,在控制窗口还是能够使用vmstat输出结果。命令详解
vmstat常用命令格式如下:
vmstat [-a] [-n] [-S unit] [delay [ count]] vmstat [-s] [-n] [-S unit] vmstat [-m] [-n] [delay [ count]] vmstat [-d] [-n] [delay [ count]] vmstat [-p disk partition] [-n] [delay [ count]] vmstat [-f] vmstat [-V]
命令选项说明如下:
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
下面就对我们常用的使用方式进行详细的总结。
使用实例
输入命令:vmstat 1
输出结果:
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 0 361396 196772 55820 359372 0 0 13 21 1 1 2 0 98 0 0 1 0 361392 196524 55820 359616 8 0 236 0 411 527 1 0 90 9 0 2 1 361392 196524 55828 359608 0 0 0 48 370 503 1 1 98 0 0 4 0 361392 196524 55828 359616 0 0 0 0 442 559 1 0 99 0 0
字段说明:
procs(进程)r:当前运行队列中线程的数目,代表线程处于可运行状态,但CPU还未能执行.,这个值可以作为判断CPU是否繁忙的一个指标;当这个值超过了CPU数目,就会出现CPU瓶颈了;这个我们可以结合top命令的负载值同步评估系统性能;b:等待IO的进程数量;如果该值一直都很大,说明IO比较繁忙,处理较慢;
memory(内存)swpd:虚拟内存已使用的大小;如果swpd的值不为0,但是si,so的值长期为0,这种情况不会影响系统性能;free:空闲的物理内存的大小;buff:用作缓冲的内存大小;cache:用作缓存的内存大小;如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小;- 关于buffer和cache的说明:buffer是与特定的块设备相关联的,并且包括文件系统的元数据的缓存以及跟踪正在进行的页面;cache仅仅包含停放的文件数据。buffer会记住目录中的数据、文件权限以及跟踪特定块设备正在写入到内存中或者从内存中读取相关信息等;cache仅包含文件本身的内容。
swap(交换空间,单位:KB);内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。有时我们看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的;si:每秒从交换区写到内存的大小;so:每秒写入交换区的内存大小;
io(单位:块/秒)bi:每秒读取的块数;bo:每秒写入的块数;随机磁盘读写的时候,这2个值越大,能看到CPU在IO等待的值也会越大;
system(系统);这2个值越大,会看到由内核消耗的CPU时间会越大;in:每秒中断数,包括时钟中断;cs:每秒上下文切换数;
cpu(以百分比表示)us:用户进程执行时间(user time);sy:系统进程执行时间(system time);id:空闲时间(包括IO等待时间);wa:等待IO时间;wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈。
Linux top命令详解
top显示系统当前的进程和其它状况,是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止。比较准确的说,top命令提供了实时的对系统处理器的状态监视。它将显示系统中CPU最“敏感”的任务列表。该命令可以按CPU使用、内存使用和执行时间对任务进行排序。命令详解
top常用命令格式如下:
top [参数]
命令参数说明如下:
-b 批处理
-c 显示完整的启动命令
-I 忽略失效过程
-s 保密模式
-S 累积模式
-H 线程模式
-i<时间> 设置间隔时间
-u<用户名> 指定用户名
-p<进程号> 指定进程
-n<次数> 循环显示的次数
下面就对我们常用的使用方式进行详细的总结。
使用实例
输入命令:top
输出结果:
top - 11:29:59 up 45 min, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 87 total, 3 running, 84 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.3 sy, 0.0 ni, 99.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1016476 total, 522952 free, 276456 used, 217068 buff/cache
KiB Swap: 839676 total, 839676 free, 0 used. 573936 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2695 jelly 20 0 157608 2164 1512 R 1.0 0.2 0:00.06 top
1603 mysql 20 0 1125372 195108 11132 S 0.3 19.2 0:01.98 mysqld
1 root 20 0 128104 6708 3956 S 0.0 0.7 0:01.92 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:00.13 ksoftirqd/0
6 root 20 0 0 0 0 S 0.0 0.0 0:00.03 kworker/u2:0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
输出内容详解:
- 第一行;这行信息与
uptime输出的信息一样;11:35:56:系统当前时间;up 51 min:系统已运行时间;1 user:当前连接系统的终端数;load average: 0.00, 0.01, 0.05:系统负载;后面的三个数分别是1分钟、5分钟、15分钟的负载情况;如果平均负载值大于0.7*CPU内核数,就需要引起关注;
- 第二行;表示进程数信息;
87 total:总进程数;3 running:正在运行的进程数;84 sleeping:正在睡眠的进程数;0 stopped:停止的进程数;0 zombie:僵尸进程数;
- 第三行;表示CPU状态信息;这里显示数据是所有CPU的平均值,如果想看每一个CPU的处理情况,按1即可;折叠,再次按1;
0.7 us:用户空间占用CPU百分比;0.3 sy:内核空间占用CPU百分比;0.0 ni:用户进程空间内改变过优先级的进程占用CPU百分比;99.0 id:CPU空闲率;0.0 wa:等待IO的CPU时间百分比;0.0 hi:硬中断(Hardware IRQ)占用CPU的百分比;0.0 si:软中断(Software Interrupts)占用CPU的百分比;0.0 st:这个虚拟机被hypervisor偷去的CPU时间(译注:如果当前处于一个hypervisor下的vm,实际上hypervisor也是要消耗一部分CPU处理时间的);
- 第四行;物理内存使用信息;
1016476 total:物理内存总量;522952 free:使用的物理内存总量;276456 used:空闲内存总量;217068 buff/cache:用作内核缓冲/缓存的内存量;
- 第五行;交换空间使用信息;我们要时刻监控交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了;
839676 total:交换区总量;839676 free:交换区空闲量;0 used:交换区使用量;573936 avail Mem:可用于进程下一次分配的物理内存数量;
- 第六行;空行;
- 第七行;各个进程的状态信息;
PID:进程id;USER:进程所有者;PR:进程优先级;NI:nice值;越小优先级越高,最小-20,最大20(用户设置最大19);VIRT:进程使用的虚拟内存总量,单位kb;VIRT=SWAP+RES;RES:进程使用的、未被换出的物理内存大小,单位kb;RES=CODE+DATA;SHR:共享内存大小,单位kb;S:进程状态;D=不可中断的睡眠状态、R=运行、S=睡眠、T=跟踪/停止、Z=僵尸进程;%CPU:上次更新到现在的CPU时间占用百分比;%MEM:进程使用的物理内存百分比;TIME+:进程使用的CPU时间总计;COMMAND命令名/命令行。
常用命令:
top // 每隔5秒显示所有进程的资源占用情况 top -d 2 // 每隔2秒显示所有进程的资源占用情况 top -c // 每隔5秒显示进程的资源占用情况,并显示进程的命令行参数(默认只有进程名) top -p 12345 -p 6789// 每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况 top -d 2 -c -p 123456 // 每隔2秒显示pid是12345的进程的资源使用情况,并显示该进程启动的命令行参数
使用技巧
- 多核CPU监控
在top基本视图中,第三行表示CPU状态信息;这里显示数据是所有CPU的平均值,如果想看每一个CPU的处理情况,按1即可;折叠,再次按1; -
高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果),当按下后,当前正在运行的进程就会被高亮显示,如下图所示:
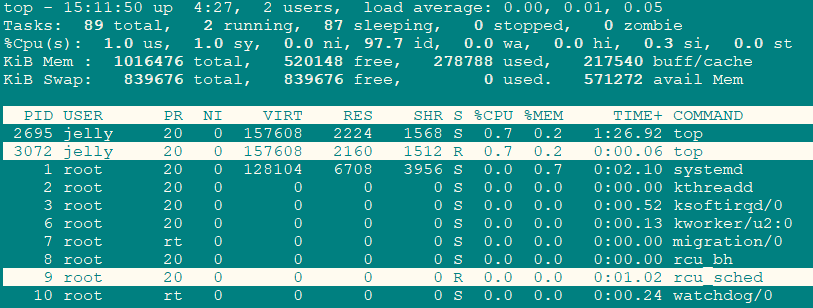
-
可以通过键盘输入“y”键关闭或打开运行态进程的加亮效果。
-
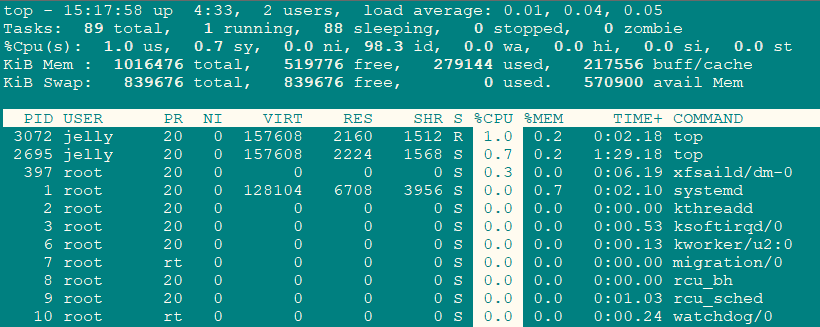
进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的。但是,我们可以改变这种排序:M:根据驻留内存大小进行排序P:根据CPU使用百分比大小进行排序T:根据时间/累计时间进行排序
通过键盘输入“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
Linux free命令详解
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。free命令详解
free命令习惯上有以下几种形式:
free -k # 以KB为单位显示内存使用情况 free -m # 以MB为单位显示内存使用情况 free -g # 以GB为单位显示内存使用情况 free -h # 以人类友好的方式显示内存使用情况
当我们输入free -m时,系统就会输出以下内容:
[root@Test_MC]# free -m
total used free shared buffers cached
Mem: 32168 30119 2048 0 4438 11097
-/+ buffers/cache: 14583 17584
Swap: 31996 1899 30097
现在对free命令输出的每行进行详细的解释:
total:内存总数,物理内存总数used:已经使用的内存数free:空闲的内存数shared:多个进程共享的内存总额buffers:缓冲内存数cached:缓存内存数- buffers/cached:应用使用内存数+ buffers/cached:应用可用内存数Swap:交换分区,虚拟内存
我们通过free命令查看机器空闲内存时,会发现free的值很小。这主要是因为,在Linux系统中有这么一种思想,内存不用白不用,因此它尽可能的cache和buffer一些数据,以方便下次使用。但实际上这些内存也是可以立刻拿来使用的。
在使用free命令时,我们都是需要重点关注- buffers/cached和+ buffers/cached。
- buffers/cached,即used - buffers/cached,表示应用程序实际使用的内存+ buffers/cached,即free + buffers/cached,表示理论上都可以被使用的内存
可见-buffers/cache反映的是被程序实实在在吃掉的内存,而+buffers/cache反映的是可以挪用的内存总数。
Linux iostat命令详解
iostat是I/O statistics(输入/输出统计)的缩写,iostat工具将对系统的磁盘操作活动进行监视。它的特点是汇报磁盘活动统计情况,同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。命令详解
iostat常用命令格式如下:
iostat [参数] [时间] [次数]
命令参数说明如下:
-c 显示CPU使用情况
-d 显示磁盘使用情况
-k 以K为单位显示
-m 以M为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS使用情况
-p 可以报告出每块磁盘的每个分区的使用情况
-t 显示终端和CPU的信息
-x 显示详细信息
下面就对我们常用的使用方式进行详细的总结。
使用实例
- 命令:
iostat -x
说明:显示详细信息
输出:
[user1@Test_Server ~]$ iostat -x
Linux 3.10.0-693.2.2.el7.x86_64 (jellythink) 01/05/2019 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.83 0.00 0.31 0.09 0.00 97.77
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.03 0.78 0.24 1.38 12.64 20.67 41.01 0.02 10.98 55.50 3.17 0.71 0.12
-
输出内容详解:
%user:CPU处在用户模式下的时间百分比%nice:CPU处在带NICE值的用户模式下的时间百分比%system:CPU处在系统模式下的时间百分比%iowait:CPU等待输入输出完成时间的百分比%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比%idle:CPU空闲时间百分比当然了,
iostat命令的重点不是用来看CPU的,重点是用来监测磁盘性能的。Device:设备名称rrqm/s:每秒合并到设备的读取请求数wrqm/s:每秒合并到设备的写请求数r/s:每秒向磁盘发起的读操作数w/s:每秒向磁盘发起的写操作数rkB/s:每秒读K字节数wkB/s:每秒写K字节数avgrq-sz:平均每次设备I/O操作的数据大小avgqu-sz:平均I/O队列长度await:平均每次设备I/O操作的等待时间 (毫秒),一般地,系统I/O响应时间应该低于5ms,如果大于 10ms就比较大了r_await:每个读操作平均所需的时间;不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间w_await:每个写操作平均所需的时间;不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间svctm:平均每次设备I/O操作的服务时间 (毫秒)(这个数据不可信!)%util:一秒中有百分之多少的时间用于I/O操作,即被IO消耗的CPU百分比,一般地,如果该参数是100%表示设备已经接近满负荷运行了 -
命令:
iostat -d 2 3
输出:
[user1@Test_Server ~]$ iostat -d 2 3 Linux 3.10.0-693.2.2.el7.x86_64 (jellythink) 01/05/2019 _x86_64_ (1 CPU) Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn vda 1.62 12.64 20.67 337375593 551756524 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn vda 1.00 0.00 8.00 0 16 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn vda 0.00 0.00 0.00 0 0
-
输出内容详解:
tps:每秒I/O数(即IOPS。磁盘连续读和连续写之和)kB_read/s:每秒从磁盘读取数据大小,单位KB/skB_wrtn/s:每秒写入磁盘的数据的大小,单位KB/skB_read:从磁盘读出的数据总数,单位KBkB_wrtn:写入磁盘的的数据总数,单位KB性能监控指标
%iowait:如果该值较高,表示磁盘存在I/O瓶颈await:一般地,系统I/O响应时间应该低于5ms,如果大于10ms就比较大了avgqu-sz:如果I/O请求压力持续超出磁盘处理能力,该值将增加。如果单块磁盘的队列长度持续超过2,一般认为该磁盘存在I/O性能问题。需要注意的是,如果该磁盘为磁盘阵列虚拟的逻辑驱动器,需要再将该值除以组成这个逻辑驱动器的实际物理磁盘数目,以获得平均单块硬盘的I/O等待队列长度%util:一般地,如果该参数是100%表示设备已经接近满负荷运行了
最后,除了关注指标外,我们更需要结合部署的业务进行分析。对于磁盘随机读写频繁的业务,比如图片存取、数据库、邮件服务器等,此类业务吗,
tps才是关键点。对于顺序读写频繁的业务,需要传输大块数据的,如视频点播、文件同步,关注的是磁盘的吞吐量。