常用技能(更新ing):http://www.cnblogs.com/dunitian/p/4822808.html#skill
技能总纲(更新ing):http://www.cnblogs.com/dunitian/p/5493793.html
在线演示:http://cppjieba-webdemo.herokuapp.com
完整demo:https://github.com/dunitian/TempCode/tree/master/2016-09-05
逆天修改版:https://github.com/dunitian/TempCode/blob/master/2016-09-05/jieba.NET.0.38.2.zip
先说下注意点,结巴分词他没有对分词进行一次去重,我们得自己干这件事;字典得自行配置或者设置成输出到bin目录
应用场景举例(搜索那块大家都知道,说点其他的)
——————————————————————————————————————————————————
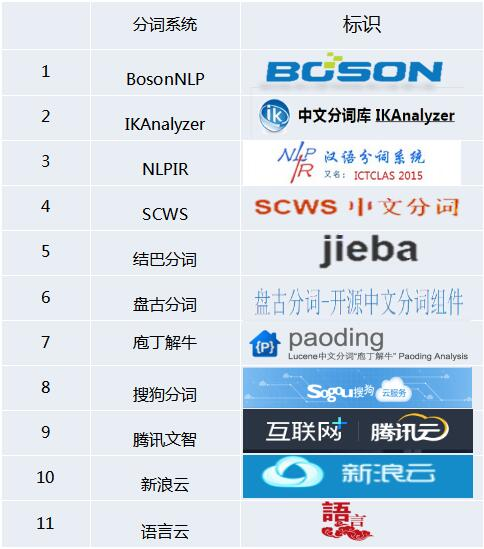
言归正传:看一组民间统计数据:(非Net版,指的是官方版)
net版的IKanalyzer和盘古分词好多年没更新了,所以这次选择了结巴分词(这个名字也很符合分词的意境~~结巴说话,是不是也是一种分词的方式呢?)
下面简单演示一下:
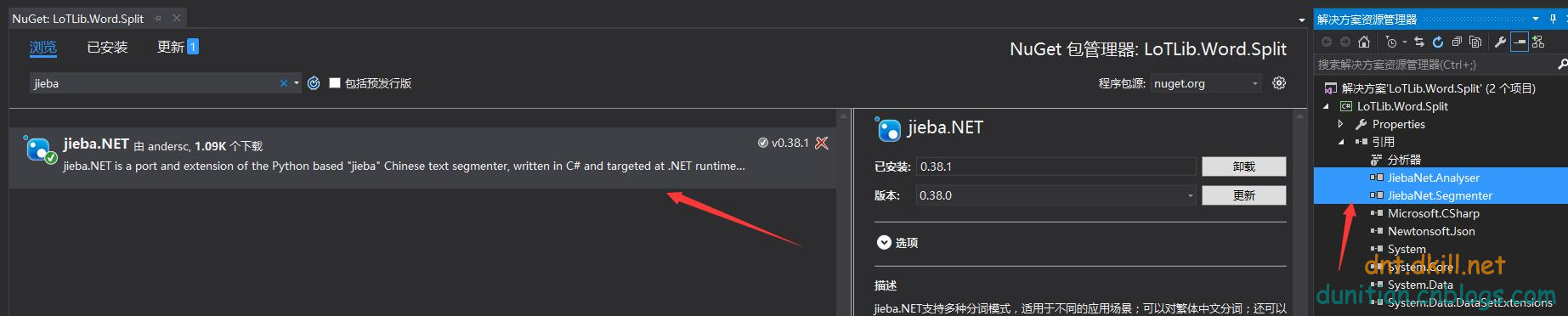
1.先引入包:
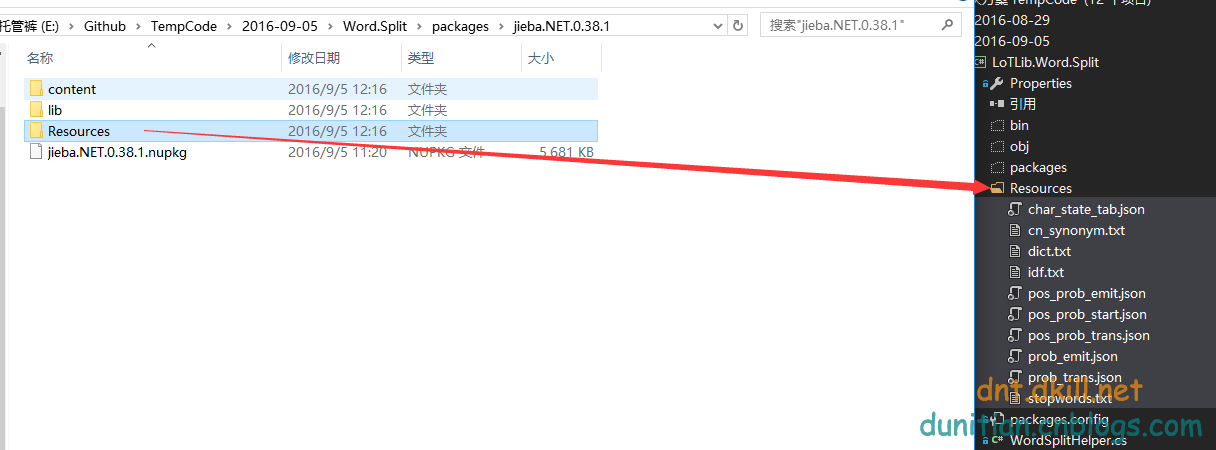
2.字典设置:
3.简单封装的帮助类:
using System.Linq; using JiebaNet.Segmenter; using System.Collections.Generic; namespace LoTLib.Word.Split { #region 分词类型 public enum JiebaTypeEnum { /// <summary> /// 精确模式---最基础和自然的模式,试图将句子最精确地切开,适合文本分析 /// </summary> Default, /// <summary> /// 全模式---可以成词的词语都扫描出来, 速度更快,但是不能解决歧义 /// </summary> CutAll, /// <summary> /// 搜索引擎模式---在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词 /// </summary> CutForSearch, /// <summary> /// 精确模式-不带HMM /// </summary> Other } #endregion /// <summary> /// 结巴分词 /// </summary> public static partial class WordSplitHelper { /// <summary> /// 获取分词之后的字符串集合 /// </summary> /// <param name="objStr"></param> /// <param name="type"></param> /// <returns></returns> public static IEnumerable<string> GetSplitWords(string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default) { var jieba = new JiebaSegmenter(); switch (type) { case JiebaTypeEnum.Default: return jieba.Cut(objStr); //精确模式-带HMM case JiebaTypeEnum.CutAll: return jieba.Cut(objStr, cutAll: true); //全模式 case JiebaTypeEnum.CutForSearch: return jieba.CutForSearch(objStr); //搜索引擎模式 default: return jieba.Cut(objStr, false, false); //精确模式-不带HMM } } /// <summary> /// 获取分词之后的字符串 /// </summary> /// <param name="objStr"></param> /// <param name="type"></param> /// <returns></returns> public static string GetSplitWordStr(this string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default) { var words = GetSplitWords(objStr, type); //没结果则返回空字符串 if (words == null || words.Count() < 1) { return string.Empty; } words = words.Distinct();//有时候词有重复的,得自己处理一下 return string.Join(",", words);//根据个人需求返回 } } }调用很简单:
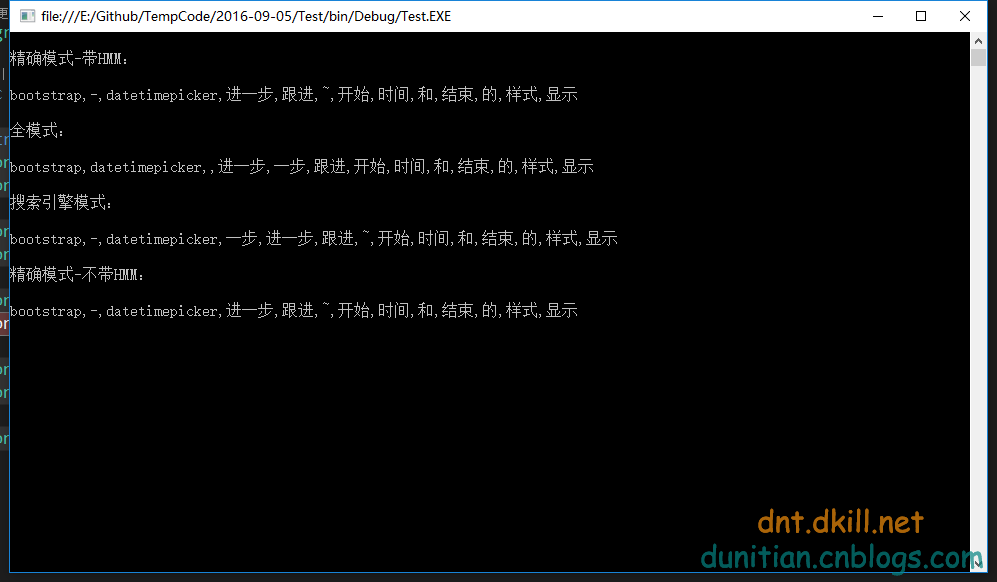
string str = "bootstrap-datetimepicker 进一步跟进~~~开始时间和结束时间的样式显示"; Console.WriteLine(" 精确模式-带HMM: "); Console.WriteLine(str.GetSplitWordStr()); Console.WriteLine(" 全模式: "); Console.WriteLine(str.GetSplitWordStr(JiebaTypeEnum.CutAll)); Console.WriteLine(" 搜索引擎模式: "); Console.WriteLine(str.GetSplitWordStr(JiebaTypeEnum.CutForSearch)); Console.WriteLine(" 精确模式-不带HMM: "); Console.WriteLine(str.GetSplitWordStr(JiebaTypeEnum.Other)); Console.ReadKey();效果:
--------------------------
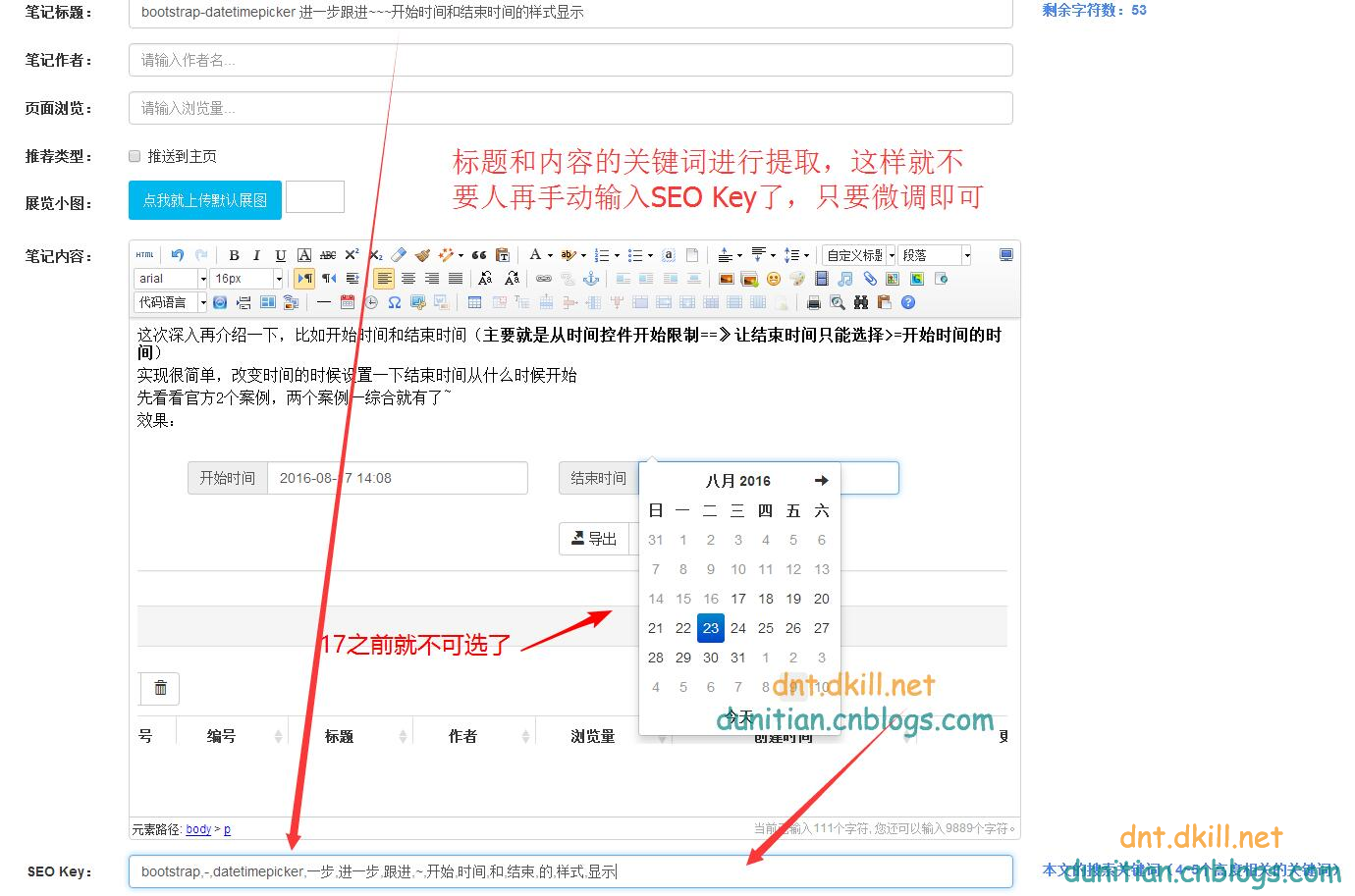
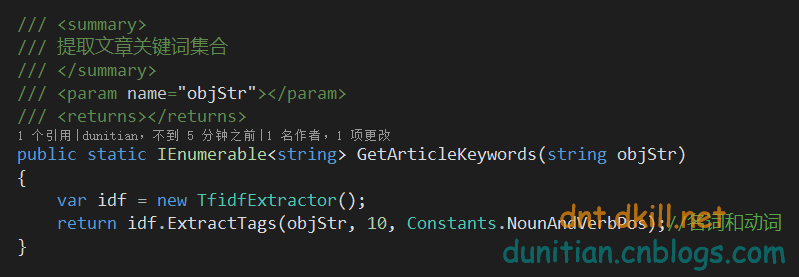
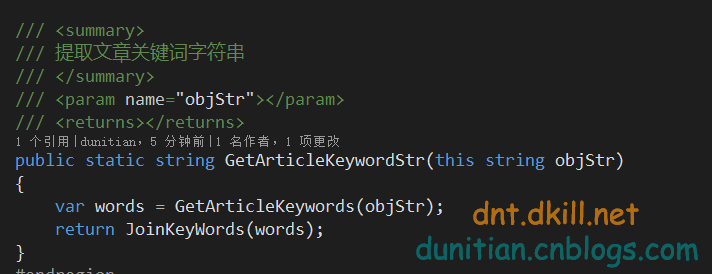
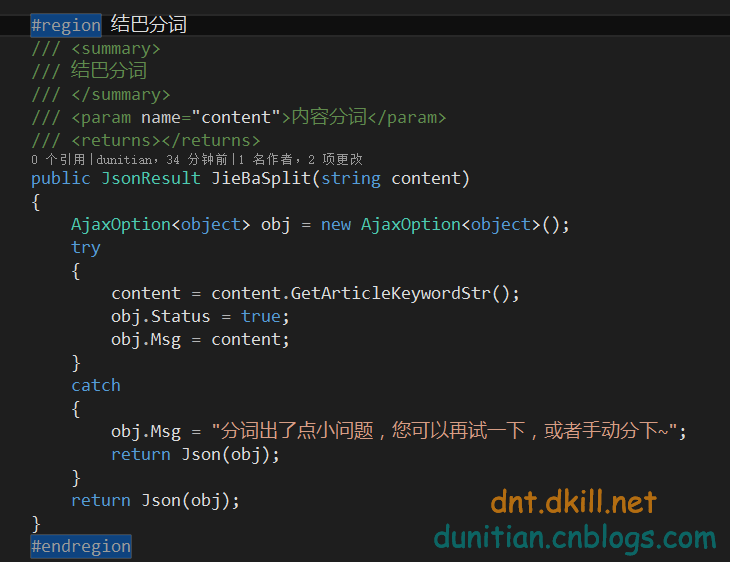
有人可能会说,那内容关键词提取呢?==》别急,看下面:
这种方式所对应的字典是它=》idf.txt
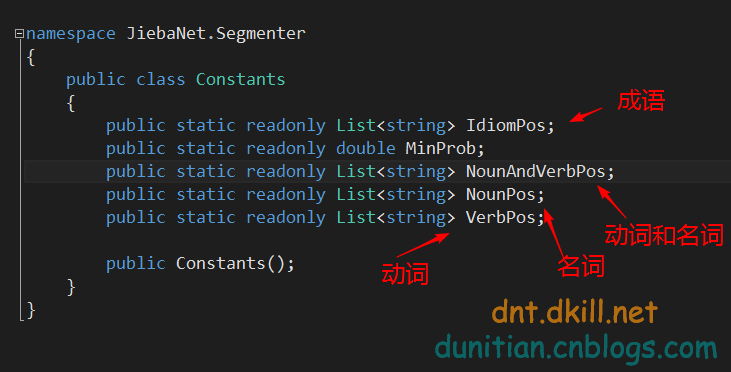
简单说下Constants==》
效果:
完整帮助类(最新看github):https://github.com/dunitian/TempCode/tree/master/2016-09-05
using System.Linq; using JiebaNet.Segmenter; using System.Collections.Generic; using JiebaNet.Analyser; namespace LoTLib.Word.Split { #region 分词类型 public enum JiebaTypeEnum { /// <summary> /// 精确模式---最基础和自然的模式,试图将句子最精确地切开,适合文本分析 /// </summary> Default, /// <summary> /// 全模式---可以成词的词语都扫描出来, 速度更快,但是不能解决歧义 /// </summary> CutAll, /// <summary> /// 搜索引擎模式---在精确模式的基础上对长词再次切分,提高召回率,适合用于搜索引擎分词 /// </summary> CutForSearch, /// <summary> /// 精确模式-不带HMM /// </summary> Other } #endregion /// <summary> /// 结巴分词 /// </summary> public static partial class WordSplitHelper { #region 公用系列 /// <summary> /// 获取分词之后的字符串集合 /// </summary> /// <param name="objStr"></param> /// <param name="type"></param> /// <returns></returns> public static IEnumerable<string> GetSplitWords(string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default) { var jieba = new JiebaSegmenter(); switch (type) { case JiebaTypeEnum.Default: return jieba.Cut(objStr); //精确模式-带HMM case JiebaTypeEnum.CutAll: return jieba.Cut(objStr, cutAll: true); //全模式 case JiebaTypeEnum.CutForSearch: return jieba.CutForSearch(objStr); //搜索引擎模式 default: return jieba.Cut(objStr, false, false); //精确模式-不带HMM } } /// <summary> /// 提取文章关键词集合 /// </summary> /// <param name="objStr"></param> /// <returns></returns> public static IEnumerable<string> GetArticleKeywords(string objStr) { var idf = new TfidfExtractor(); return idf.ExtractTags(objStr, 10, Constants.NounAndVerbPos);//名词和动词 } /// <summary> /// 返回拼接后的字符串 /// </summary> /// <param name="words"></param> /// <returns></returns> public static string JoinKeyWords(IEnumerable<string> words) { //没结果则返回空字符串 if (words == null || words.Count() < 1) { return string.Empty; } words = words.Distinct();//有时候词有重复的,得自己处理一下 return string.Join(",", words);//根据个人需求返回 } #endregion #region 扩展相关 /// <summary> /// 获取分词之后的字符串 /// </summary> /// <param name="objStr"></param> /// <param name="type"></param> /// <returns></returns> public static string GetSplitWordStr(this string objStr, JiebaTypeEnum type = JiebaTypeEnum.Default) { var words = GetSplitWords(objStr, type); return JoinKeyWords(words); } /// <summary> /// 提取文章关键词字符串 /// </summary> /// <param name="objStr"></param> /// <returns></returns> public static string GetArticleKeywordStr(this string objStr) { var words = GetArticleKeywords(objStr); return JoinKeyWords(words); } #endregion } }



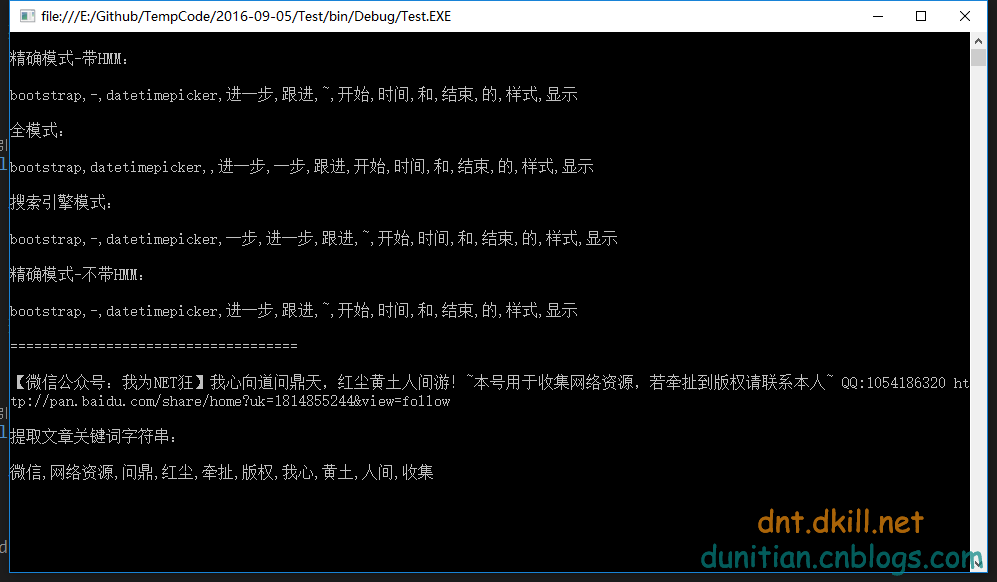

还有耐心或者只看末尾的有福了~
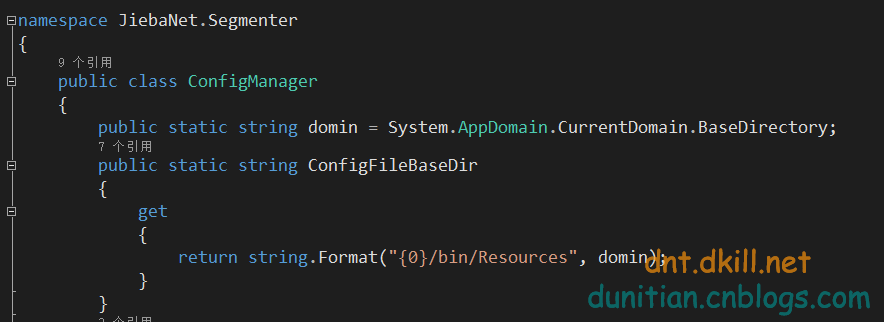
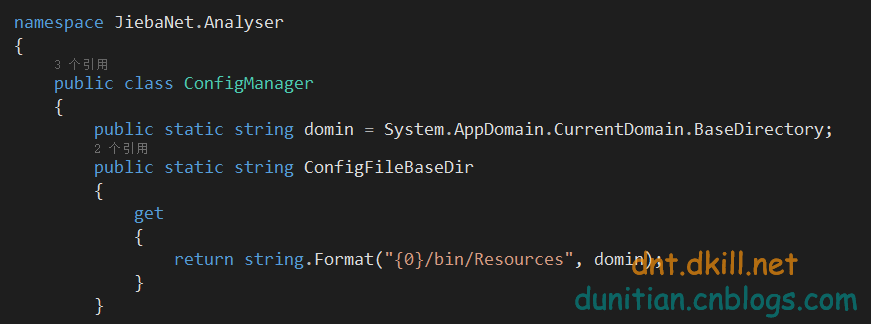
web端的字典配置那是个烦啊,逆天把源码微调了下
使用方法和上面一样
web版演示:
结巴中文分词相关:
https://github.com/fxsjy/jieba