汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql
第一次引入文件组的概念:http://www.cnblogs.com/dunitian/p/5276431.html
上次说了其他的解决方案(http://www.cnblogs.com/dunitian/p/6041745.html),就是没有说水平分库,这次好好说下。
上次共享的第一份大数据,这次正好来演示一下水平分库
1.模拟部分数据
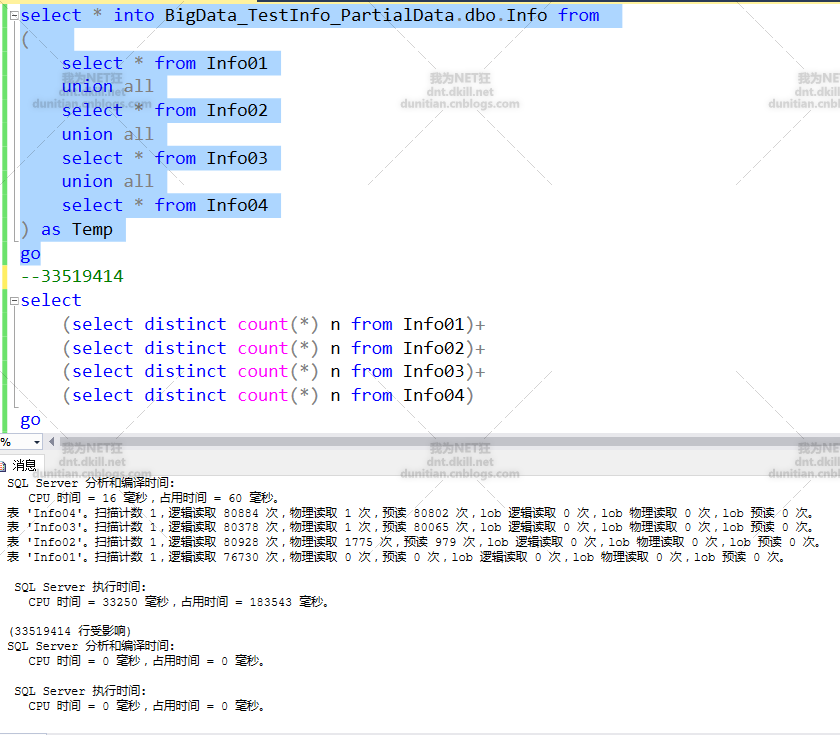
2.创建索引后,发现可以根据日期来分组
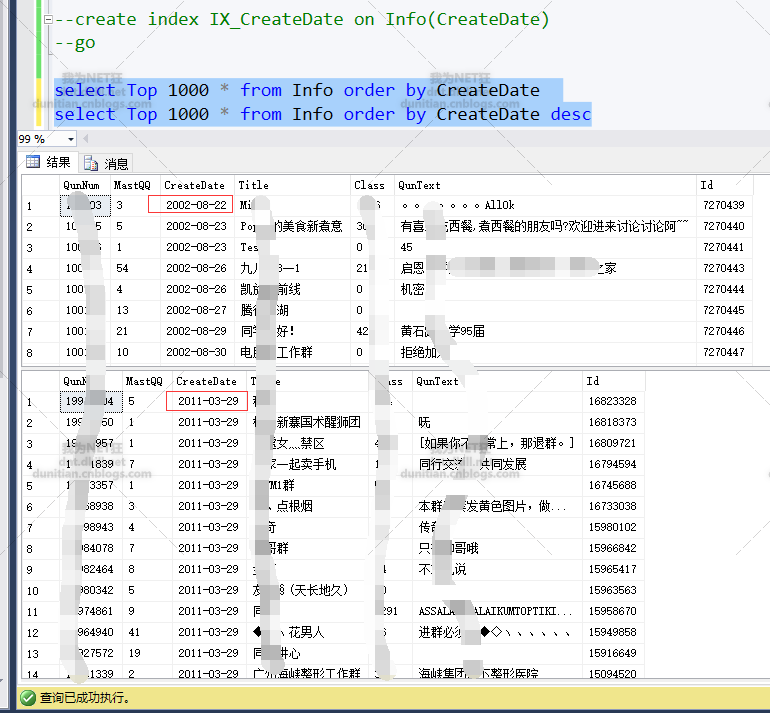
按数据量大致分一下
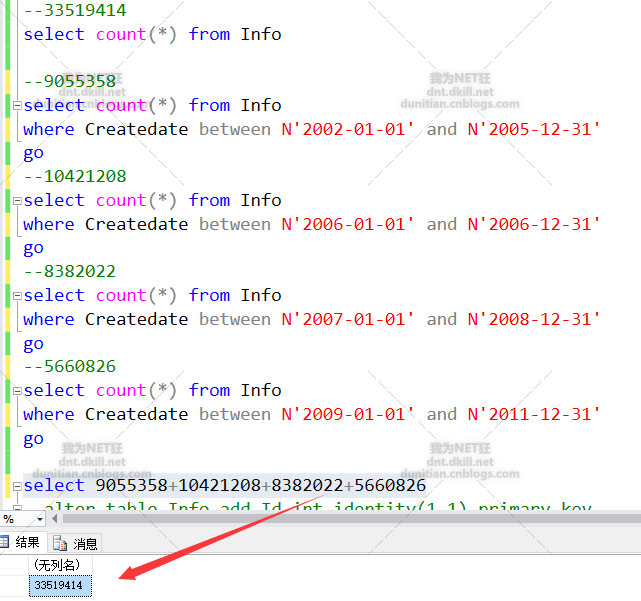
步入正轨
---------------------------------------------------------------------
GUI方法:
3.0创建文件组

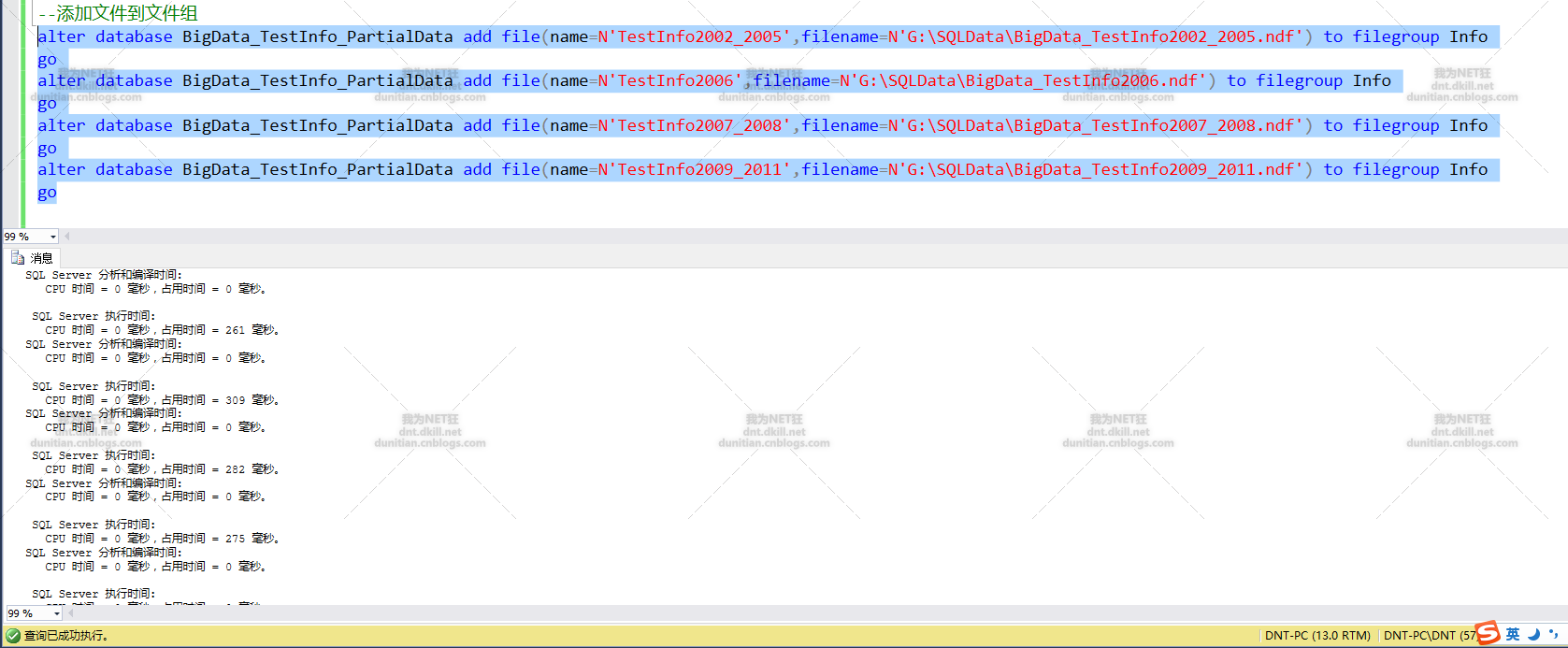
添加文件到文件组
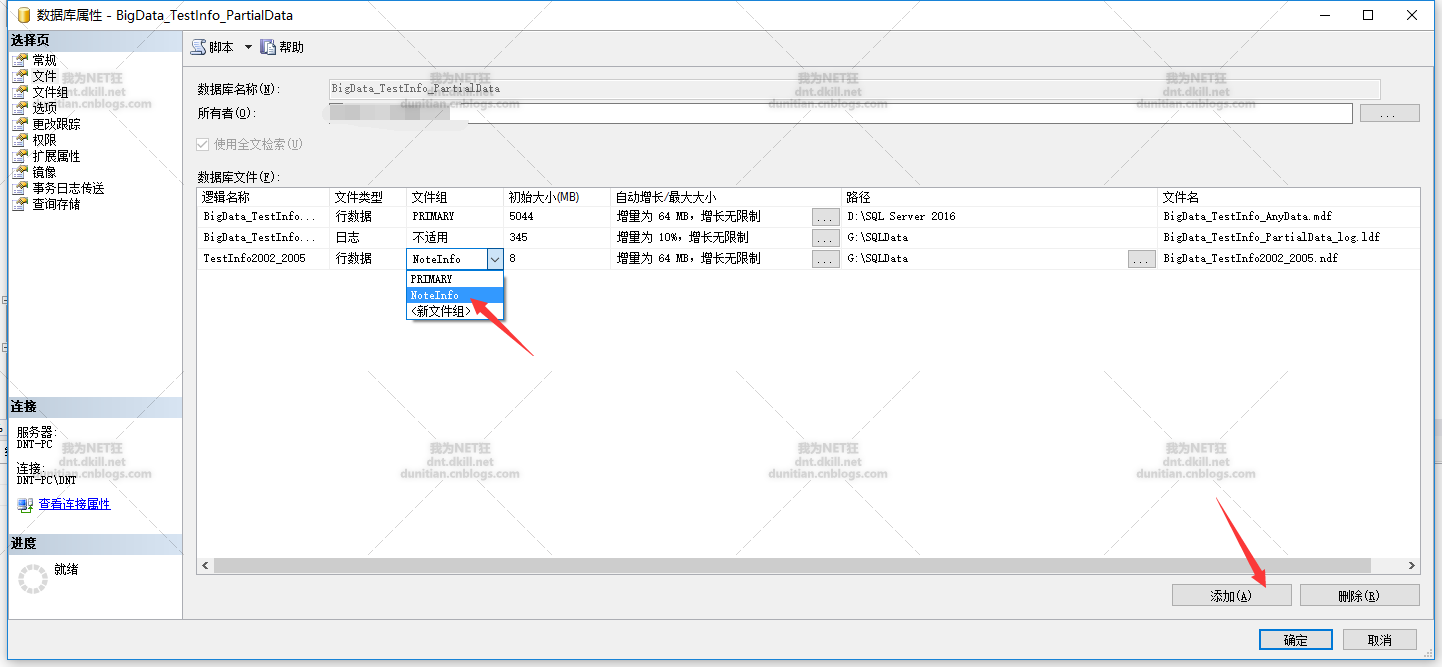
命令操作:
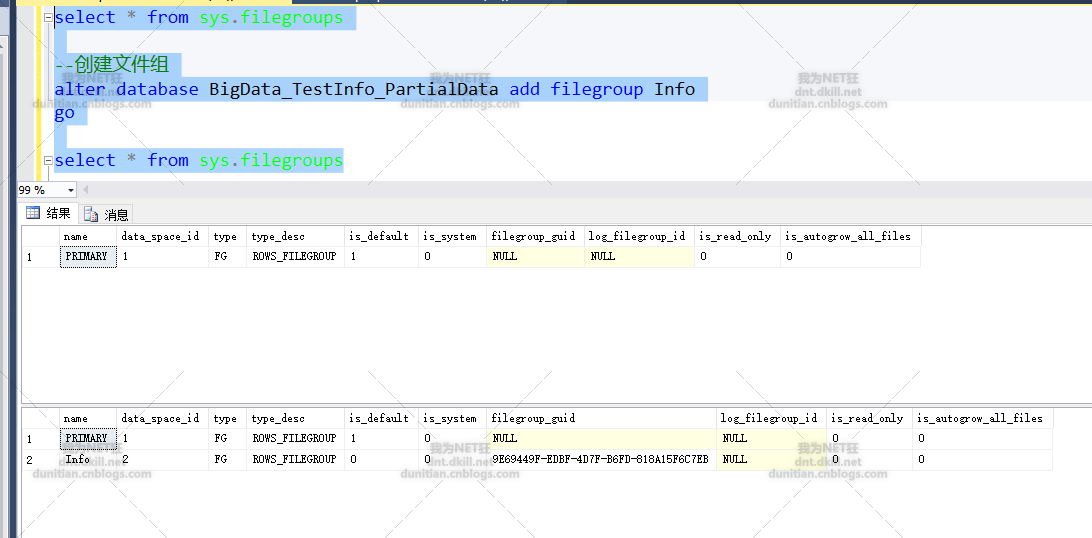
alter database BigData_TestInfo_PartialData add filegroup Info
alter database BigData_TestInfo_PartialData add file(name=N'TestInfo2006',filename=N'G:SQLDataBigData_TestInfo2006.ndf') to filegroup Info
注意:BigData_TestInfo2006.ndf是数据库自己创建的,不需要自己手动创建(有些同志手动创建了,然后报错。。。。呃,有点哭笑不得了)
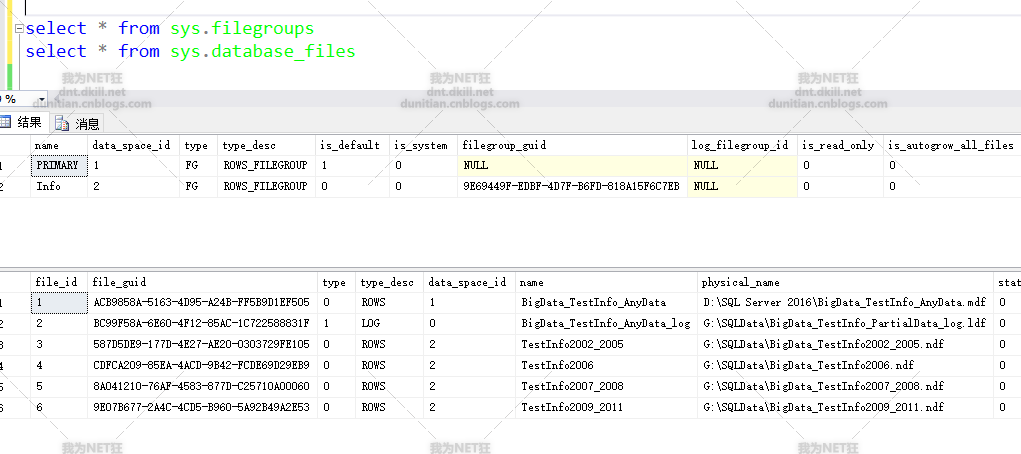
查询看看:select * from sys.filegroups
水平分区走起:一般就几步,1.创建分区函数 2.创建分区方案 3.创建分区表
GUI方法
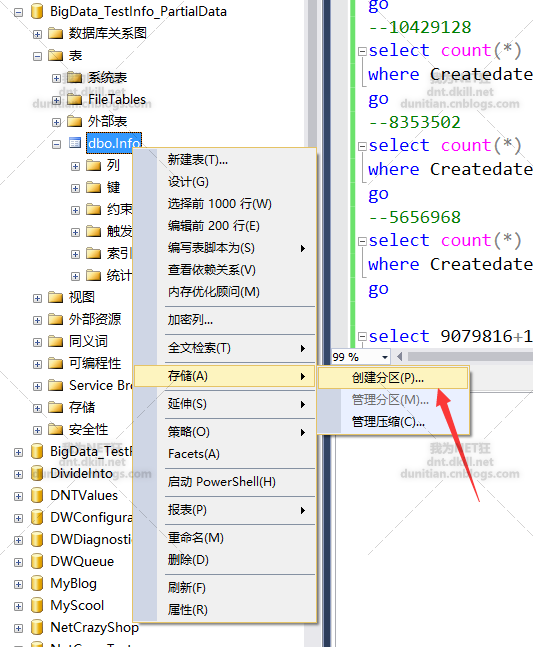
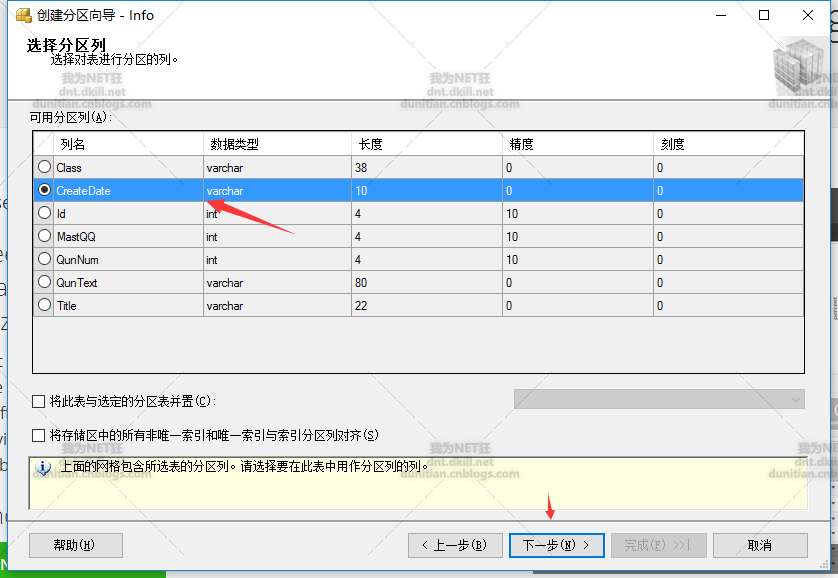
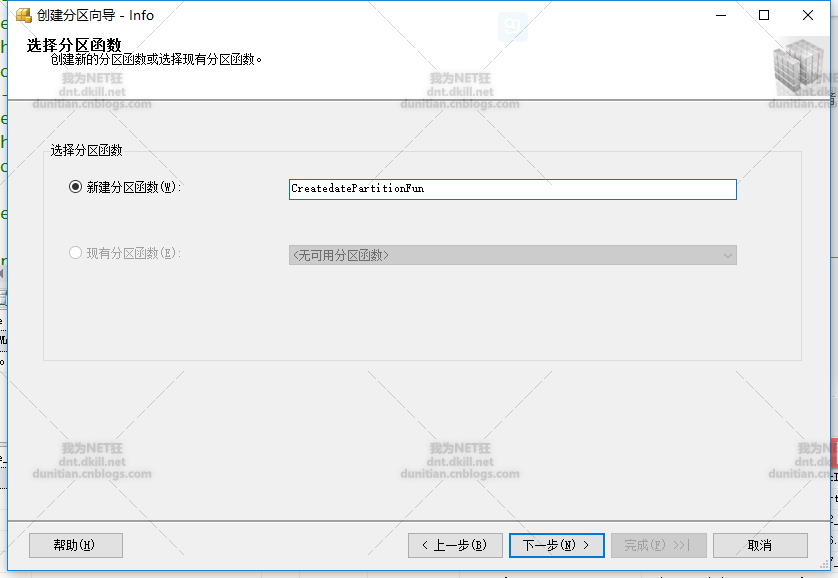
分区函数
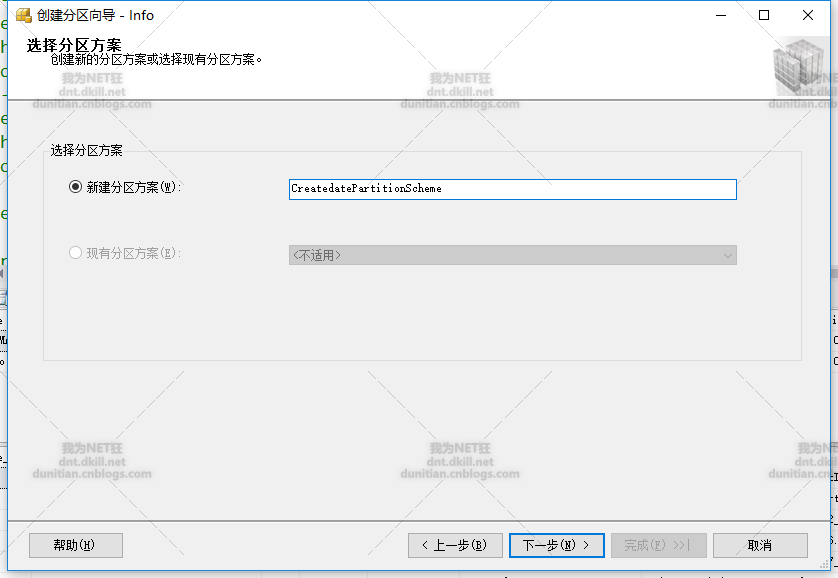
分区方案
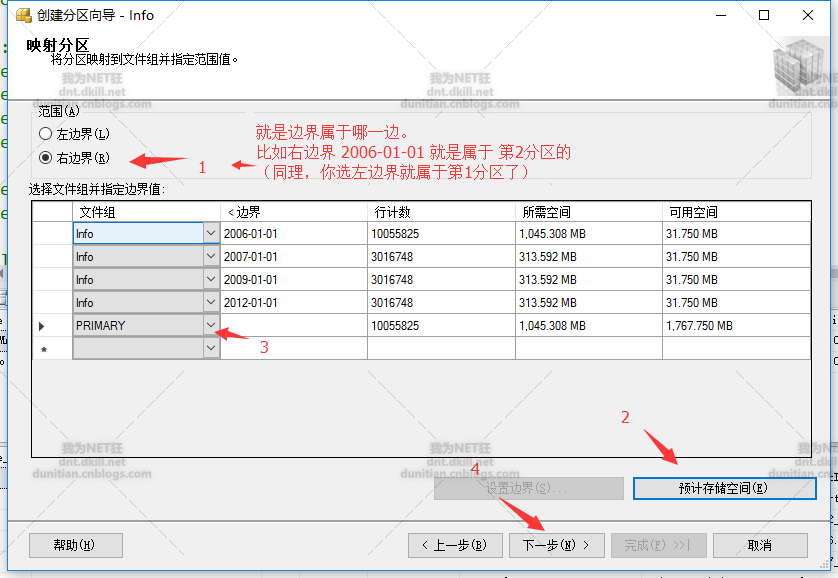
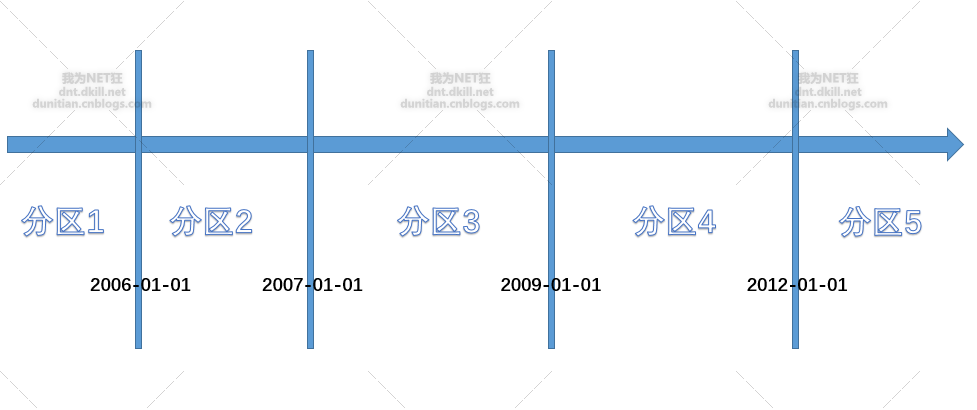
上一张图有些人可能不懂,用PPT画张概念图:
创建脚本
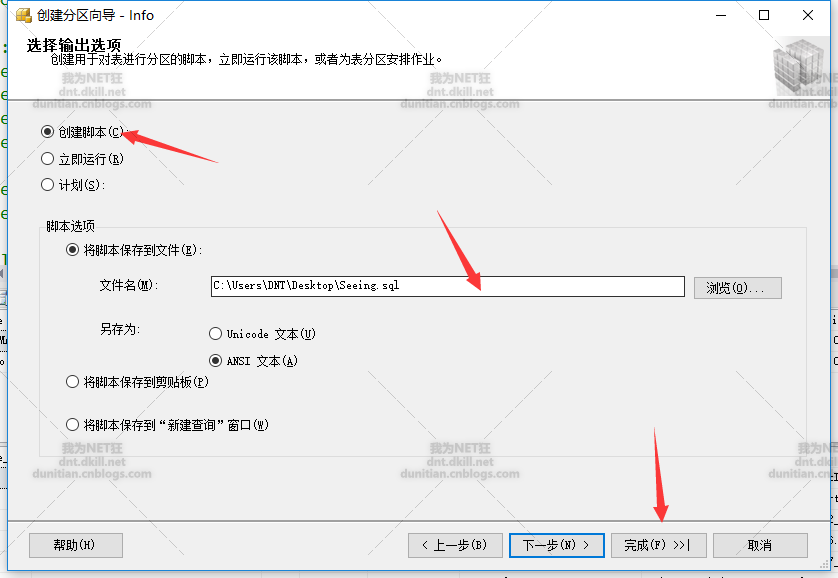
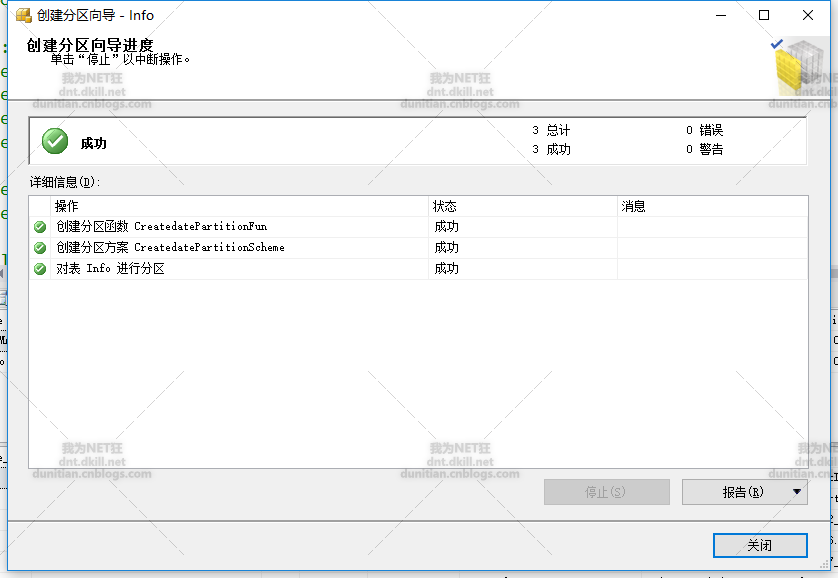
系统生成脚本:
use [BigData_TestInfo_PartialData] go begin transaction create partition function [CreatedatePartitionFun](varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01') create partition scheme [CreatedatePartitionScheme] as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary]) alter table [dbo].[Info] drop constraint [PK__Info__3214EC07B2FE10C8] alter table [dbo].[Info] add primary key nonclustered ( [Id] asc )with (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] set ansi_padding on create clustered index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] ( [CreateDate] )with (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [CreatedatePartitionScheme]([CreateDate]) drop index [ClusteredIndex_on_CreatedatePartitionScheme_636193166313125124] on [dbo].[Info] commit transaction go
命令方式创建(根据上面生成的命令逆推)
创建分区函数和架构(方案)
create partition function CreatedatePartitionFun(varchar(10)) as range right for values(N'2006-01-01', N'2007-01-01', N'2009-01-01', N'2012-01-01')

create partition scheme CreatedatePartitionScheme as partition [CreatedatePartitionFun] TO ([Info], [Info], [Info], [Info], [primary])
创建分区表
尚未创建表的情况

已经创建了表(基本上都是这种情况)
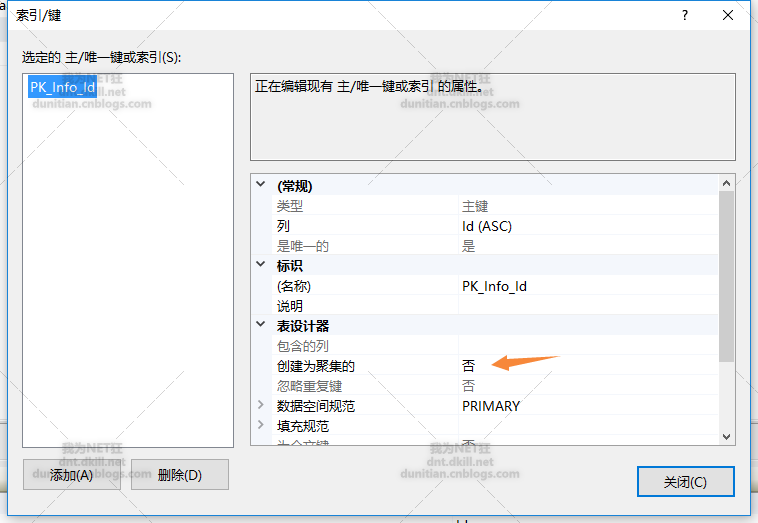
主要就两步,把主键变为非聚集索引+创建分区聚集索引
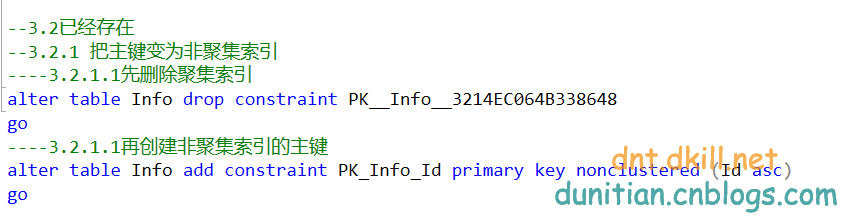
alter table Info drop constraint PK__Info__3214EC064B338648
alter table Info add constraint PK_Info_Id primary key nonclustered (Id asc)

create clustered index IX_Info_CreateDate on Info(CreateDate) on CreatedatePartitionScheme(CreateDate)
测试:基本上是均匀分散在各个文件中,生产环境的时候可以把这些文件放各个磁盘

参考文章:
http://www.cnblogs.com/gaizai/p/3582024.html
http://www.cnblogs.com/lyhabc/p/3480917.html
http://www.cnblogs.com/libingql/p/4087598.html
http://www.cnblogs.com/CareySon/p/3252670.html
http://database.51cto.com/art/201009/225448.htm
http://www.cnblogs.com/knowledgesea/p/3696912.html
http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html
http://www.cnblogs.com/lykbk/p/erererert343243434388773437878.html