1.压缩概述

2.压缩策略和原则

3.MapReduce支持的压缩编码
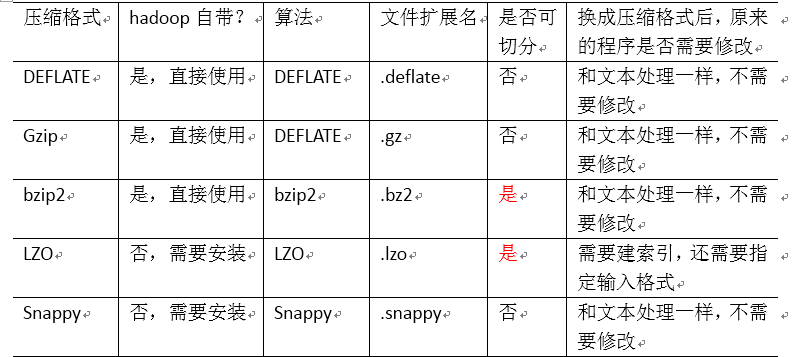
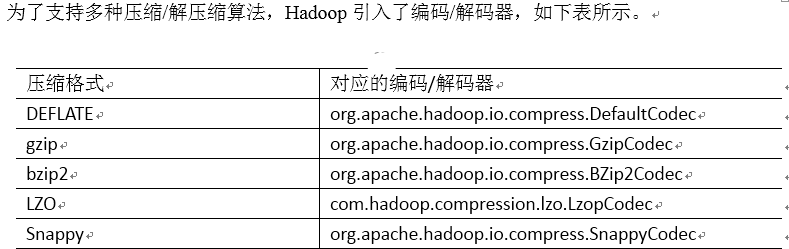

64位系统下的单核i7,Snappy的压缩速率可以达到至少250MB/S,解压缩速率可以达到至少500MB/S
4.压缩方式选择
1) Gzip

2) Bzip2

3) Lzo

4) Snappy

4. 压缩位置选择
压缩可以在MapReduce作用的任意阶段启用

5. 压缩参数配置
|
参数 |
默认值 |
阶段 |
建议 |
|
io.compression.codecs (在core-site.xml中配置) |
org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec
|
输入压缩 |
Hadoop使用文件扩展名判断是否支持某种编解码器 |
|
mapreduce.map.output.compress(在mapred-site.xml中配置) |
false |
mapper输出 |
这个参数设为true启用压缩 |
|
mapreduce.map.output.compress.codec(在mapred-site.xml中配置) |
org.apache.hadoop.io.compress.DefaultCodec |
mapper输出 |
企业多使用LZO或Snappy编解码器在此阶段压缩数据 |
|
mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) |
false |
reducer输出 |
这个参数设为true启用压缩 |
|
mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) |
org.apache.hadoop.io.compress. DefaultCodec |
reducer输出 |
使用标准工具或者编解码器,如gzip和bzip2 |
|
mapreduce.output.fileoutputformat.compress.type(在mapred-site.xml中配置) |
RECORD |
reducer输出 |
SequenceFile输出使用的压缩类型:NONE和BLOCK |