dubbo要解决的问题
rpc调用需要定制。额外的工作量
分布式服务中,服务动辄几十上百,相互之间的调用错综复杂,相互依赖严重
对集群性的服务,需要负载策略
对集群性的服务,能动态扩展节点
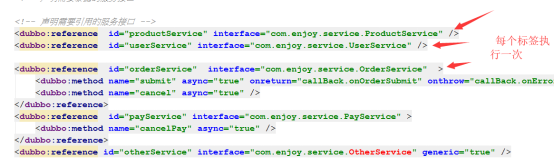
dubbo标签
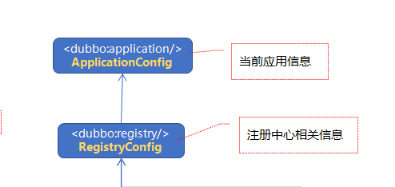
服务方和消费方都要配置
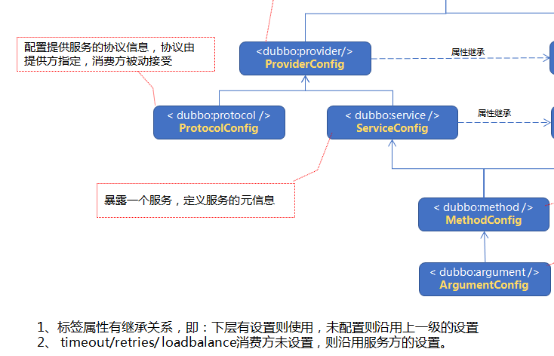
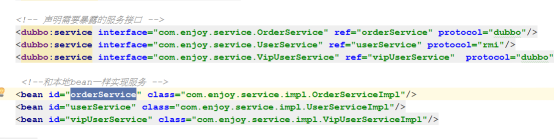
2、服务方的标签:
上层属性,能够自动被下层继承
provider标签做默认配置使用,主要启一个继承作用。比如timeout = 1s。
protocol指定协议,service配置目标实现类
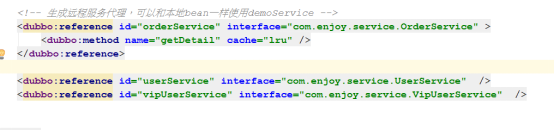
3、消费方的标签
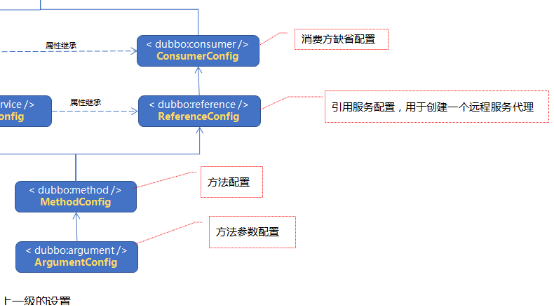
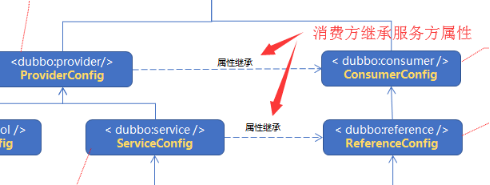
3、消费方继承服务方属性
只有服务提供方,知道service参数怎么配置最合适。timeout = 1s
dubbo配置文件
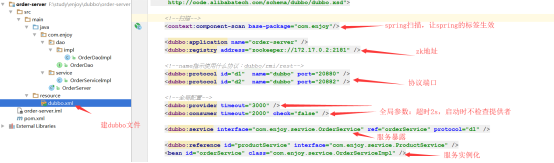
dubbo配置的步骤
1、把服务交给ioc容器管理

2、dubbo把容器内的三个service,开放成rpc服务
3、消费方通过dubbo,得到rpc服务的代理对象
4、消费方启动spring容器,初始化了dubbo

5、dubbo的集群容错配置 ---- 调用失败怎么?哪些策略?

failover:重试其它provider的服务 --------- 幂等时才能使用(比如读操作)
failfast:直接返回失败 --------- 一般的写操作,不能重试
failsafe:忽略错误 --------- 无关紧要的服务使用,如打日志/发邮件
6、负载配置 -----

random:随机访问每个provider
roundrobin:轮询访问
leastactive:谁最轻松,访问谁
7、声明式缓存 ---- 将方法的参数与返回value缓存

lru:最少使用原则删除缓存(此参数长期未调,就不缓存了)
threadlocal:对调用者缓存(下次还是你调用,就返回缓存的数据)
rpc调用过程
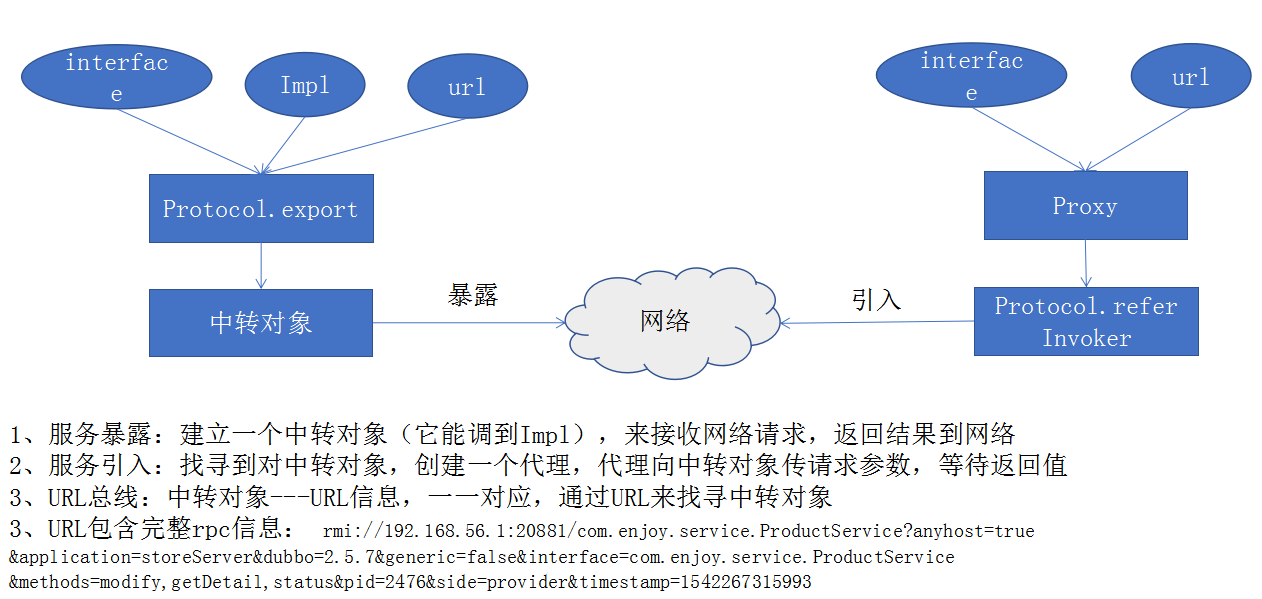
源码走读
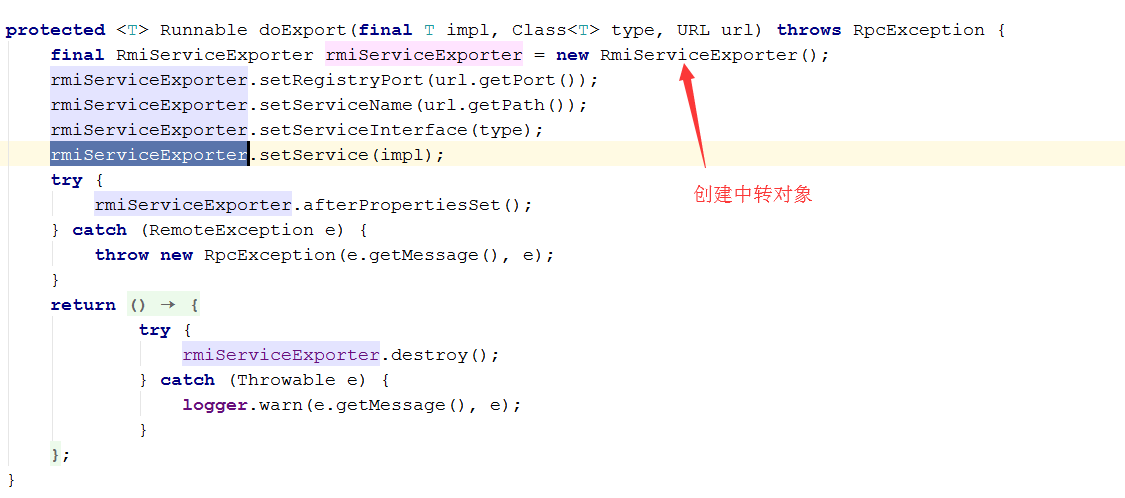
服务端在中转对象上,设定--- 接口/实现/url

消费端创建代理对象,设定 接口/url
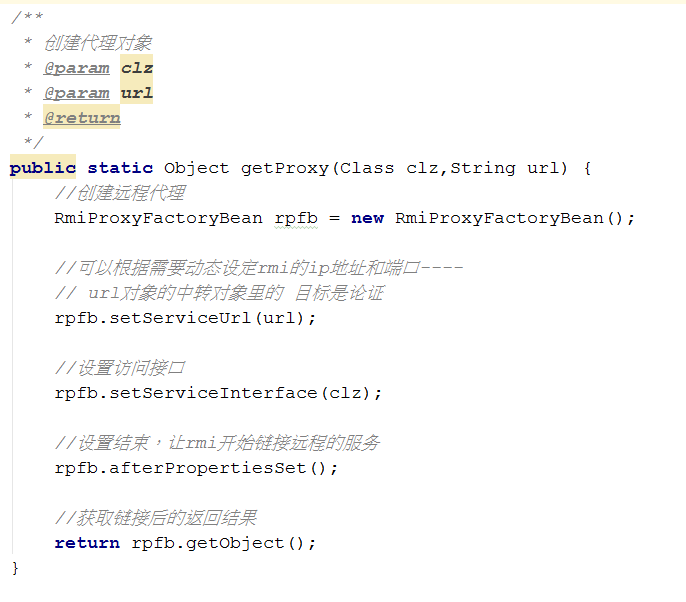
调用过程
中转对象,跟着代理对象动作,猴子学样;
dubbo代理对象与中转对象(目标) 建立的关系,通过URL来传递的。
URL是整个dubbo里的总信息描述符。
dubbo一般选择使用哪个协议?
最常用,就是dubbo协议/hession协议
选择协议,一般就考量协议的性能,就数这两个协议效率高
zookeeper在dubbo里,处于什么位置
zk在dubbo里起的作用 --- 数据库 + 消息推送
同样的,使用redis一样能做数据的记录和消息投送,这对dubbo来说,没有区别。
dubbo初始化过程
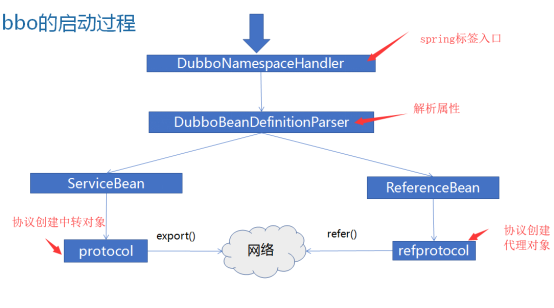
1、标签入口 ---- DubboNamespaceHandler

2、下面每个配置标签 ---- 对应一个ReferenceBean实例
2.1、把dubbo:referencce (dubbo:service同理)标签配置的属性,全读出来 ---- set进入ReferenceBean对象,对象实例由IOC容器管理
2.2、ReferenceBean(ServiceBean同理)实现了,initializingBean接口,因此初始化完成时,会调用其afterPropertiesSet方法

2.3、afterPropertiesSet方法内,进行dubbo服务配置(创建消费端的代理对象/服务端的中转对象/向zk注册信息/订阅信息等)

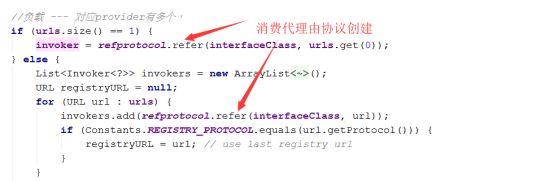
这里会对标签中设置的每个协议,进行一行处理
2.4、协议创建中转对象和消费代理

2.5、dubbo的初始化结构图:主线是ServiceBean和ReferenceBean的初始化
3、spi机制概念
-------------本质是解决同一个接口,有多种实现时,使用者如何能够方便选择实现的问题
3.1、同一个接口,多个实现(类似设计模式--策略模式)
3.2、看jdk的spi如何配置使用的
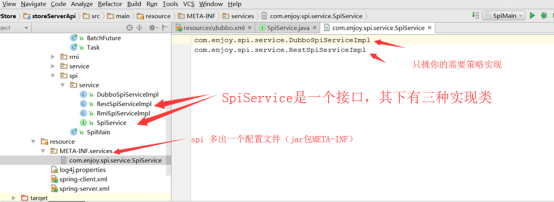
jdk中,选择SpiService的实现,方法是在jar中放置一个META-INF/services目录,目录中存放一个文本文件(文件名----是SpiService接口的全路径名),文本中列入你选择的实现类(一行放一个------是实现类的全路径名)
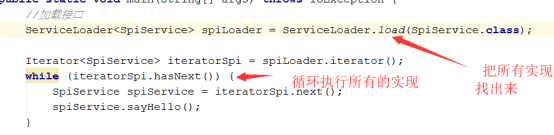
有了上述配置,在java程序中,使用ServiceLoader.load(SpiService.class),即可将配置中选择的实现类,实例化并放入一个集合中,供我们使用,如下图:
3.3、dubbo的spi ------ 比jdk的选择方案,要牛叉一点

与jdk相比,dubbo将选择权下放到了配置文件中(你配置谁,它使为你实例化谁)
dubbo的目标,以上图cluster为例,failsafe/failover/failfast都是cluster的一种实现,现在我 们可以在标签配置时,方便地进行选择
5、dubbo的Spi实现原理---解读其核心ExtensionLoader
5.1、看源码疑云:

疑问:dubbo中reference 使用的protoc·ol --- 是静态类变量
而ReferenceConfig(ReferenceBean的父级)是每个标签一个实例对象(每个对象配置的protocol是不同的)

此时protocol的对应一定出问题
结论:上面步骤中,得到的protocol是个代理类,不是真实的协议实现
5.2、ExtensionLoader的加载步骤

5.2.1、getExtensionLoader(Protocol.class)为protocol接口生成一个加载器
5.2.2、getAdaptiveExtension(),使用加载器生成一个代理对象---- protocol接口对象
5.2.3、代理对象执行时,根据参数(扩展名extName)选择实际对象 ------

5.2.4、最后的效果:每个接口扩展点----- 对应一个ExtensionLoader加载器,如:
protocol -------------- ExtensionLoader实例< protocol>
filter -------------- ExtensionLoader实例< filter >
loadbalance -------------- ExtensionLoader实例< loadbalance >
5.2.5、代理类的逻辑
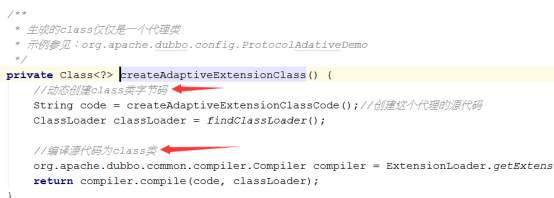
代理类的创建,是通过动态代码,生成一个类源码,然后经过编译得到代理类的class,如上图
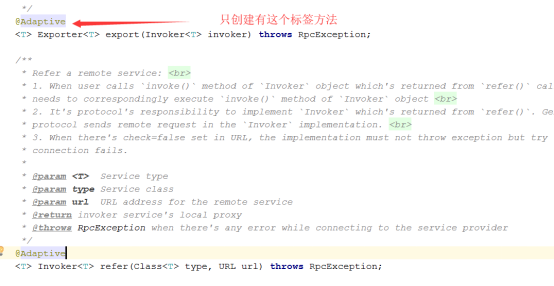
代理类生成源码的逻辑,只生接口中,标注了@Adaptive的方法,如下:
5.2.6、dubbo的spi整体执行逻辑
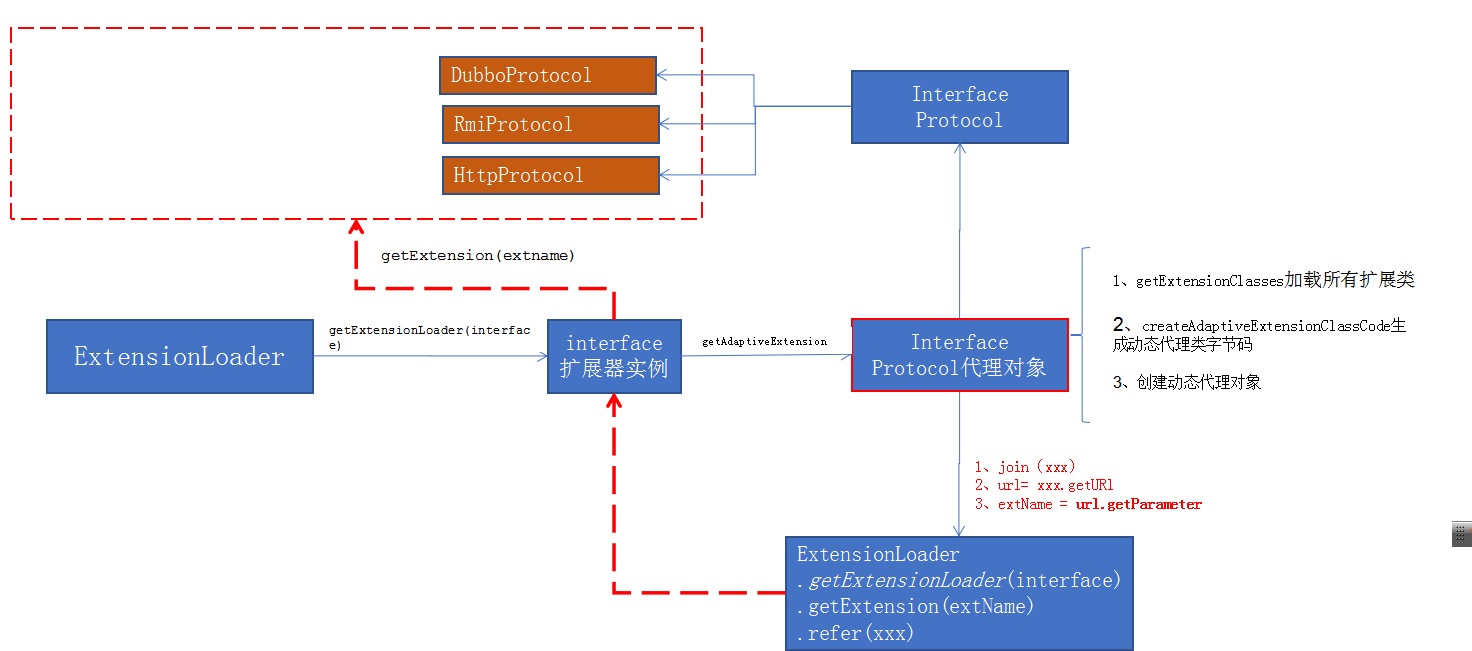
a、dubbo启动加载实现类时,以 key-实例 方式map缓存各个实现类
b、实际调用时,通过key --取实现需要那个实现
c、调用的发生,由生成的代理对象的来发起,最终是从URL总线中,找出extName值,
extName做为别说,在缓存map中取出正确的实现实现类