mysql 优化之索引的使用
1:MySQL 索引简介:
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
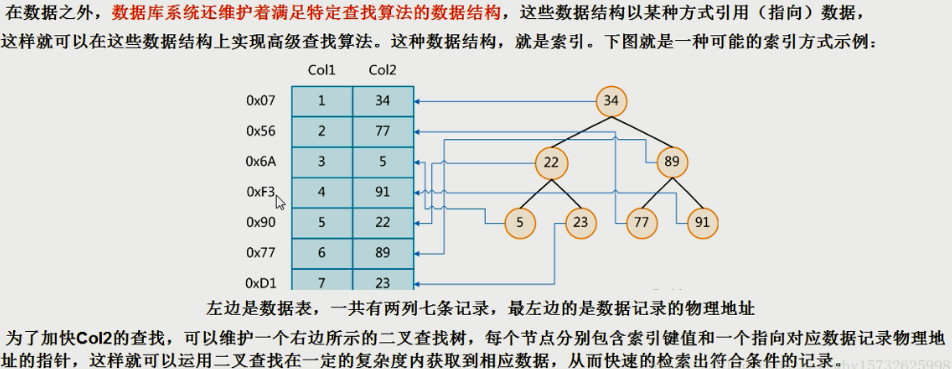
2:什么场景不适合创建索引
第一: 对于那些在查询中很少使用或者参考的列不应该创建索引。这是因 为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二: 对于那 些只有很少数据值的列也不应该增加索引。因为本来结果集合就是相当于全表查询了,所以没有必要。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比 例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三: 对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四: 当修改性能远远大于检索性能时,不应该创建索 引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因 此,当修改性能远远大于检索性能时,不应该创建索引。
第五: 不会出现在where条件中的字段不该建立索引。
3: 什么样的字段适合创建索引
1、表的主键、外键必须有索引;外键是唯一的,而且经常会用来查询
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;经常连接查询,需要有索引
4、经常出现在Where子句中的字段,加快判断速度,特别是大表的字段,应该建立索引,建立索引,一般用在select ……where f1 and f2 ,我们在f1或者f2上建立索引是没用的。只有两个使用联合索引才能有用
5、经常用到排序的列上,因为索引已经排序。
6、经常用在范围内搜索的列上创建索引,因为索引已经排序了,其指定的范围是连续的
4、索引优缺点
4.1、优点
索引由数据库中一列或多列组合而成,其作用是提高对表中数据的查询速度
索引的优点是可以提高检索数据的速度
4.2、缺点
索引可以提高查询速度,会减慢写入、修改速度
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要
5: 索引分类
MYSQL索引有四种
PRIMARY(唯一且不能为空;一张表只能有一个主键索引)、
INDEX(普通索引)、
UNIQUE(唯一性索引)、
FULLTEXT(全文索引:用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以)
索引方法:
mysql的两种索引方法(Innodb和MyISAM默认的索引是Btree索引):
1.HASH(用于对等比较,如"="和" <=>") //<=> 安全的比对 ,用与对null值比较,语义类似is null()
2.BTREE(用于非对等比较,比如范围查询)>,>=,<,<=、BETWEEN、Like
1,普通索引:
仅加速查询 最基本的索引,没有任何限制,是我们大多数情况下使用到的索引。
创建索引(方式一):
CREATE INDEX index_name on user_info(name) ;
方式二:
ALTER table tableName ADD INDEX indexName(columnName)
方式三(创建表的时候直接指定):
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);

2,唯一索引:
与普通索引类型,不同的是:加速查询 + 列值唯一(可以有null)
CREATE UNIQUE INDEX mail on user_info(name) ;
3,全文索引:
全文索引(FULLTEXT)仅可以适用于MyISAM引擎的数据表;作用于CHAR、VARCHAR、TEXT数据类型的列。
4,组合索引:
将几个列作为一条索引进行检索,使用最左匹配原则。
多列索引是先按照第一列进行排序,然后在第一列排好序的基础上再对第二列排序,如果没有第一列的话,直接访问第二列,那第二列肯定是无序的,直接访问后面的列就用不到索引了。
搜索需要从根节点出发,上层节点对应靠左的值,搜索需要从根节点出发,否则不从根节点出发,后面的节点对应下层的值,依旧是乱序的,需要遍历,所以索引就失效了,所以有最左原则。
5:删除索引
drop index_name on table_name;
或者:
alter TABLE table_name drop index name_index ;
6: 查看索引
show index from table_name;
案例分析与索引失效:
1:组合索引的使用:
例如组合索引(a,b,c),组合索引的生效原则是
从前往后依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用;
比如
where a=3 and b=45 and c=5 .... 这种三个索引顺序使用中间没有断点,全部发挥作用;
where a=3 and c=5... 这种情况下b就是断点,a发挥了效果,c没有效果
where b=3 and c=4... 这种情况下a就是断点,在a后面的索引都没有发挥作用,这种写法联合索引没有发挥任何效果;
where b=45 and a=3 and c=5 .... 这个跟第一个一样,全部发挥作用,abc只要用上了就行,跟写的顺序无关
案例分析:
1: 大于(>)导致后面的索引失效
创建表:
CREATE TABLE `article` (
`id` int(10) NOT NULL,
`author_id` int(10) DEFAULT NULL,
`category_id` int(10) DEFAULT NULL,
`views` int(10) DEFAULT NULL,
`comments` int(10) DEFAULT NULL,
`title` varchar(255) DEFAULT NULL,
`content` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
需求1:查询category_id为1且comments大于1的情况下,views最多的article_id
SELECT id, author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1

首先,我们根据where后面要查询的字段建立复合索引,即category_id、comments、views。
CREATE INDEX idx_article_ccv ON article (category_id, comments, views);

✈ 分析:根据测试结果,key的值为index_article_ccv,说明该索引已经被使用,而且type变成了range,这是可以忍受的,但是Extra中的Using filesort仍然在,这是无法接受的。但是,我们已经建立了索引,为啥没用呢?这是因为按照BTree索引的工作原理,先排序category_id,如果遇到相同的category_id则再排序comments,如果遇到相同的comments则再排序views。当comments字段在联合索引里处于中间位置时,因comments>1条件是一个范围值(所谓range),MySQL无法利用索引再对后面的views部分进行检索,即range类型查询字段后面的索引无效。
我们发现,当comments字段的查询条件改为常量1的时候,没有了Using filesort。这说明使用 > 这种范围查询会使后面的索引失效。
解决方案:
删除刚刚建立的索引,建立category_id、views索引 idx_article_cv
CREATE INDEX idx_article_cv ON article (category_id, views);

✈ 分析:可以看到,type变为了ref,Extra中的Using filesort也消失了,结果非常理想。
2: left join条件用于确定如何从右表搜索行,左边一定都有,所以右表是我们的关键点,与左表关联的右表的字段一定需要建立索引。需要注意的是,如果条件不允许,只能在左表存在索引,那么我们可以使用右连接,交换两表位置,达到相同的效果。(例子:关联查询以 SELECT * FROM a LEFT JOIN b ON a.id = b.a_id 为例, 因为 a 表 会查询符合条件的所有内容, 因此关联查询时,索引应该建立在 b表上的 a_id 字段上;三表、多表查询都应该遵循此原则,即左连接,索引应该建立在与之关联 的右表上。)。
关联查询时应该以 “小表驱动大表”(即左边的表数据量尽可能的少于右表)。
3:like查询是以'%'开头导致索引失效(解决like 左右两边都带%,索引不失效的情况,建立联合索引,并且查询时使用覆盖索引(所查字段与索引字段一样的情况下))。
4、对查询的列上有运算或者函数的
5、如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
6、如果mysql估计使用全表扫描要比使用索引快,则不使用索引
7:<>、!=、not in 、not exist、在索引列上使用 IS NULL 或 IS NOT NULL操作索引是不索引空值的,所以这样的操作不能使用索引(存储引擎不能使用索引中范围条件右边→_→的列。)。
8、如果查询中没有用到联合索引的第一个字段,则不会走索引。
9:使用 OR 导致索引失效。
10:使用 IN ,如果IN中包含子查询会导致索引失效,如果是具体的值,则会走索引。