mysql 的sql语句优化
1、LIMIT 语句
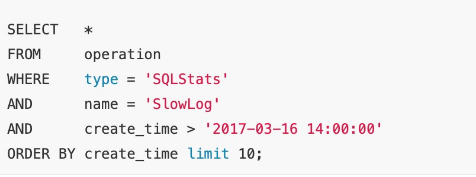
分页查询是最常用的场景之一,但也通常也是最容易出问题的地方。比如对于下面简单的语句,一般 DBA 想到的办法是在 type, name, create_time 字段上加组合索引。这样条件排序都能有效的利用到索引,性能迅速提升。

好吧,可能90%以上的 DBA 解决该问题就到此为止。但当 LIMIT 子句变成 “LIMIT 1000000,10” 时,程序员仍然会抱怨:我只取10条记录为什么还是慢?要知道数据库也并不知道第1000000条记录从什么地方开始,即使有索引也需要从头计算一次。出现这种性能问题,多数情形下是程序员偷懒了。在前端数据浏览翻页,或者大数据分批导出等场景下,是可以将上一页的最大值当成参数作为查询条件的。SQL 重新设计如下:在新设计下查询时间基本固定,不会随着数据量的增长而发生变化。
2、关联更新、删除
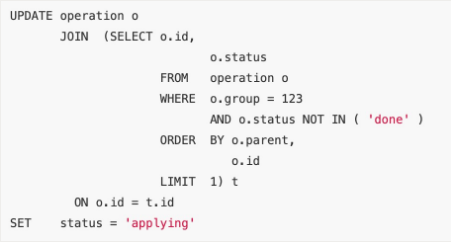
虽然 MySQL5.6 引入了物化特性,但需要特别注意它目前仅仅针对查询语句的优化。对于更新或删除需要手工重写成 JOIN。比如下面 UPDATE 语句,MySQL 实际执行的是循环/嵌套子查询(DEPENDENT SUBQUERY),其执行时间可想而知。

优化:重写为 JOIN:
二、 多表关联删除
从MySQL数据表t1中把那些id值在数据表t2里有匹配的记录全删除掉
DELETE u FROM `user` AS u INNER JOIN user_role AS ur WHERE u.id = ur.user_id
从MySQL数据表t1里在数据表t2里没有匹配的记录查找出来并删除掉
DELETE u FROM `user` AS u LEFT JOIN user_role AS ur ON u.id = ur.user_id WHERE ur.user_id IS NULL
从两个表中找出相同记录的数据并把两个表中的数据都删除掉
DELETE u, ur from `user` AS u INNER JOIN user_role AS ur ON u.id = ur.user_id WHERE u.id=1
3、EXISTS语句
MySQL 对待 EXISTS 子句时,仍然采用嵌套子查询的执行方式。如下面的 SQL 语句:

去掉 exists 更改为 join,能够避免嵌套子查询,将执行时间从1.93秒降低为1毫秒。

4、提前缩小范围

数为90万,时间消耗为12秒。
由于最后 WHERE 条件以及排序均针对最左主表,因此可以先对 my_order 排序提前缩小数据量再做左连接。SQL 重写后如下,执行时间缩小为1毫秒左右。

delete后加 limit是个好习惯么?
在业务场景要求高的数据库中,对于单条删除和更新操作,在 delete 和 update 后面加 limit 1 绝对是个好习惯。比如,在删除执行中,第一条就命中了删除行,如果 SQL 中有 limit 1;这时就 return 了,否则还会执行完全表扫描才 return。效率不言而喻。
那么,在日常执行 delete 时,我们是否需要养成加 limit 的习惯呢?是不是一个好习惯呢?
在日常的 SQL 编写中,你写 delete 语句时是否用到过以下 SQL?
delete from t where sex = 1 limit 100;
你或许没有用过,在一般场景下,我们对 delete 后是否需要加 limit 的问题很陌生,也不知有多大区别,今天带你来了解一下,记得 mark!
写在前面,如果是清空表数据建议直接用 truncate,效率上 truncate 远高于 delete,应为 truncate 不走事务,不会锁表,也不会生产大量日志写入日志文件;truncate table table_name 后立刻释放磁盘空间,并重置 auto_increment 的值。delete 删除不释放磁盘空间,但后续 insert 会覆盖在之前删除的数据上。详细了解请跳转另一篇博文《delete、truncate、drop 的区别有哪些,该如何选择》
下面只讨论 delete 场景,首先,delete 后面是支持 limit 关键字的,但仅支持单个参数,也就是 [limit row_count],用于告知服务器在控制命令被返回到客户端前被删除的行的最大值。
delete limit 语法如下,值得注意的是,order by 必须要和 limit 联用,否则就会被优化掉。
delete [low\_priority] [quick] [ignore] from tbl\_name
[where ...]
[order by ...]
[limit row\_count]
加 limit 的的优点:
以下面的这条 SQL 为例:
delete from t where sex = 1;
-
1. 降低写错 SQL 的代价,就算删错了,比如 limit 500, 那也就丢了 500 条数据,并不致命,通过 binlog 也可以很快恢复数据。
-
2. 避免了长事务,delete 执行时 MySQL 会将所有涉及的行加写锁和 Gap 锁(间隙锁),所有 DML 语句执行相关行会被锁住,如果删除数量大,会直接影响相关业务无法使用。
-
3. delete 数据量大时,不加 limit 容易把 cpu 打满,导致越删越慢。
针对上述第二点,前提是 sex 上加了索引,大家都知道,加锁都是基于索引的,如果 sex 字段没索引,就会扫描到主键索引上,那么就算 sex = 1 的只有一条记录,也会锁表。
对于 delete limit 的使用,MySQL 大佬丁奇有一道题:
如果你要删除一个表里面的前 10000 行数据,有以下三种方法可以做到:
第一种,直接执行 delete from T limit 10000;
第二种,在一个连接中循环执行 20 次 delete from T limit 500;
第三种,在 20 个连接中同时执行 delete from T limit 500。
你先考虑一下,再看看几位老铁的回答:
--------------------------------------------
Tony Du:
-
方案一,事务相对较长,则占用锁的时间较长,会导致其他客户端等待资源时间较长。
-
方案二,串行化执行,将相对长的事务分成多次相对短的事务,则每次事务占用锁的时间相对较短,其他客户端在等待相应资源的时间也较短。这样的操作,同时也意味着将资源分片使用(每次执行使用不同片段的资源),可以提高并发性。
-
方案三,人为自己制造锁竞争,加剧并发量。
-
方案二相对比较好,具体还要结合实际业务场景。
--------------------------------------------
不考虑数据表的访问并发量,单纯从这个三个方案来对比的话。
-
第一个方案,一次占用的锁时间较长,可能会导致其他客户端一直在等待资源。
-
第二个方案,分成多次占用锁,串行执行,不占有锁的间隙其他客户端可以工作,类似于现在多任务操作系统的时间分片调度,大家分片使用资源,不直接影响使用。
-
第三个方案,自己制造了锁竞争,加剧并发。
至于选哪一种方案要结合实际场景,综合考虑各个因素吧,比如表的大小,并发量,业务对此表的依赖程度等。
-------------------------------------------
-
1. 直接 delete 10000 可能使得执行事务时间过长
-
2. 效率慢点每次循环都是新的短事务,并且不会锁同一条记录,重复执行 DELETE 知道影响行为 0 即可
-
3. 效率虽高,但容易锁住同一条记录,发生死锁的可能性比较高
-------------------------------------------
怎么删除表的前 10000 行。比较多的朋友都选择了第二种方式,即:在一个连接中循环执行 20 次 delete from T limit 500。确实是这样的,第二种方式是相对较好的。
第一种方式(即:直接执行 delete from T limit 10000)里面,单个语句占用时间长,锁的时间也比较长;而且大事务还会导致主从延迟。
第三种方式(即:在 20 个连接中同时执行 delete from T limit 500),会人为造成锁冲突。
这个例子对我们实践的指导意义就是,在删除数据的时候尽量加 limit。这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围。所以,在 delete 后加 limit 是个值得养成的好习惯。