solr简介:
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr与Lucene的区别:
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
下载:
2-1、从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3
2-2、将solr-4.10.3.zip解压:
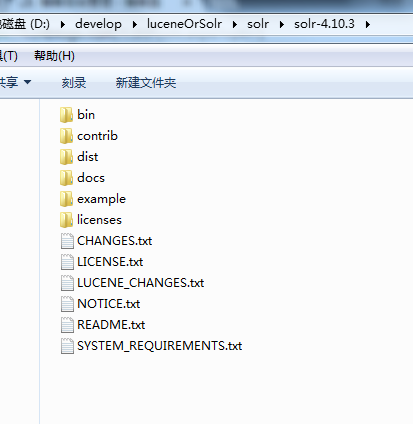
目录介绍:
bin:solr的运行脚本
contrib:solr的一些软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
l example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
l example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
l example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
3. 运行环境:
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上。我们使用tomcat作为Servlet容器。
3-1. Solr Home与SolrCore
创建一个Solr home目录,SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
examplesolr是一个solr home目录结构,如下:
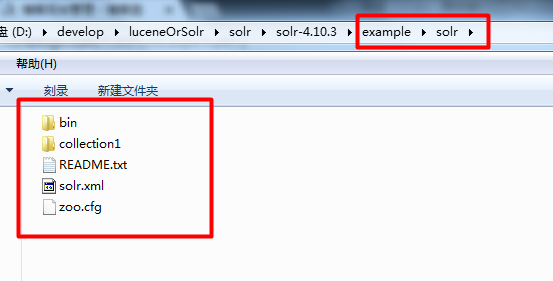
上图中“collection1”是一个SolrCore(Solr实例)目录 ,目录内容如下所示:
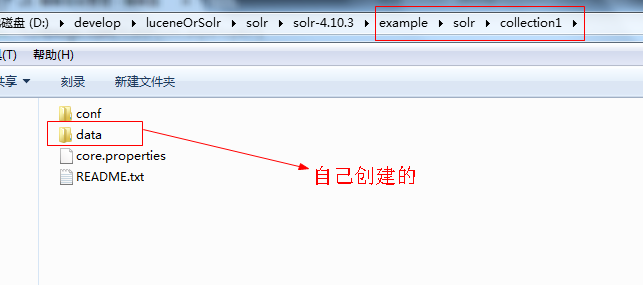
说明:
collection1:叫做一个Solr运行实例SolrCore,SolrCore名称不固定,一个solr运行实例对外单独提供索引和搜索接口。
solrHome中可以创建多个solr运行实例SolrCore。
一个solr的运行实例对应一个索引目录。
conf是SolrCore的配置文件目录 。
data目录存放索引文件需要创建;
3-2. 整合步骤:
第一步:安装tomcat。D: empapache-tomcat-7.0.53
第二步: 把solr的war包复制到tomcat 的webapp目录下:
把solr-4.10.3distsolr-4.10.3.war复制到D: empapache-tomcat-7.0.53webapps下;改名为solr.war。
第三步:solr.war解压。使用压缩工具解压或者启动tomcat自动解压。解压之后删除solr.war
第四步:把solr-4.10.3examplelibext目录下的所有的jar包添加到solr工程中(solr/web-INF/lib下)。
第五步:配置solrHome和solrCore。
1)创建一个solrhome(存放solr所有配置文件的一个文件夹)。solr-4.10.3examplesolr目录就是一个标准的solrhome。
2)把solr-4.10.3examplesolr文件夹复制到 D:路径下(自己想放哪都可以),改名为solrhome,改名不是必须的,是为了便于理解。
3)在solrhome下有一个文件夹叫做collection1这就是一个solrcore。就是一个solr的实例。一个solrcore相当于mysql中一个数据库。Solrcore之间是相互隔离。
- 在solrcore中有一个文件夹叫做conf,包含了索引solr实例的配置信息。
- ii. 在conf文件夹下有一个solrconfig.xml。配置实例的相关信息。如果使用默认配置可以不用做任何修改。
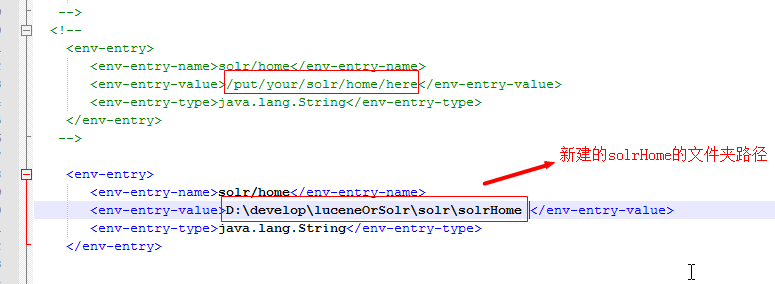
第六步:告诉solr服务器配置文件也就是solrHome的位置。
1:打开web-INF下面的web.xml文件:
第七步:启动tomcat
第八步:访问http://localhost:8080/solr/
3-3:管理界面:
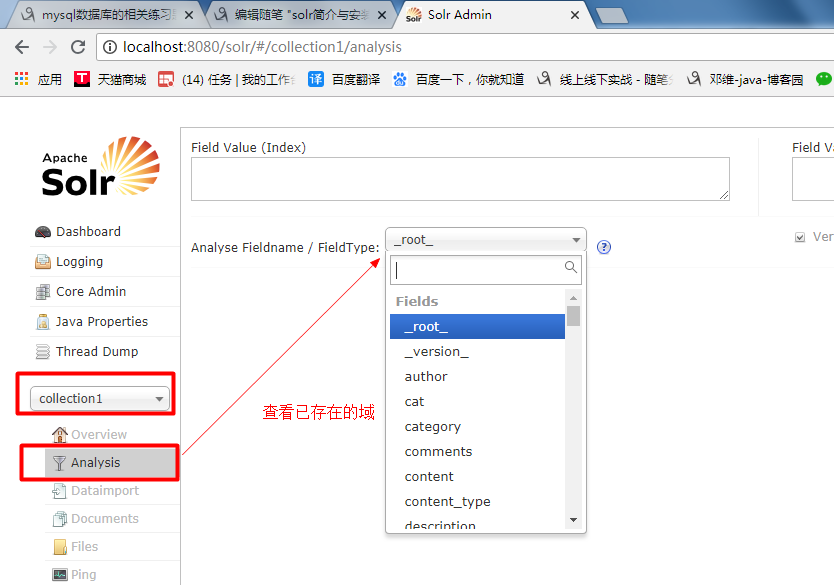
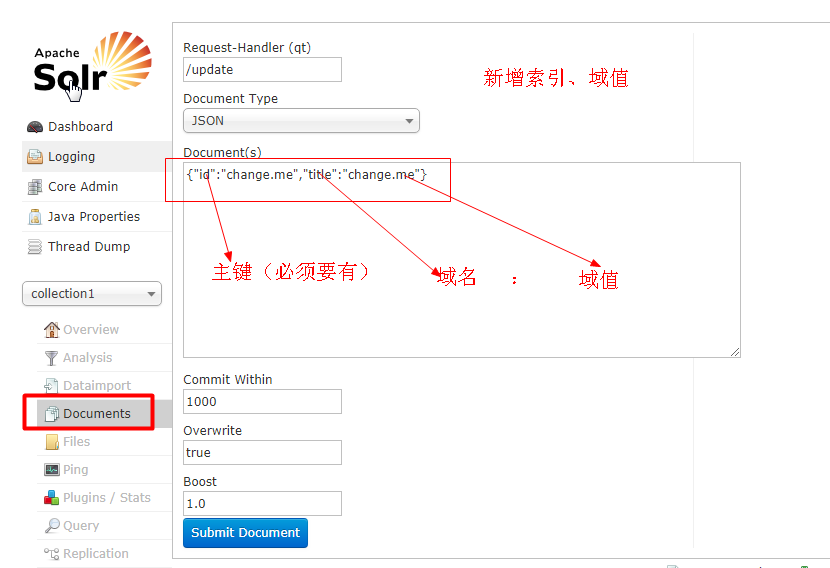
通过此菜单可以创建索引、更新索引、删除索引等操作:
通过/select执行搜索索引,必须指定“q”查询条件方可搜索
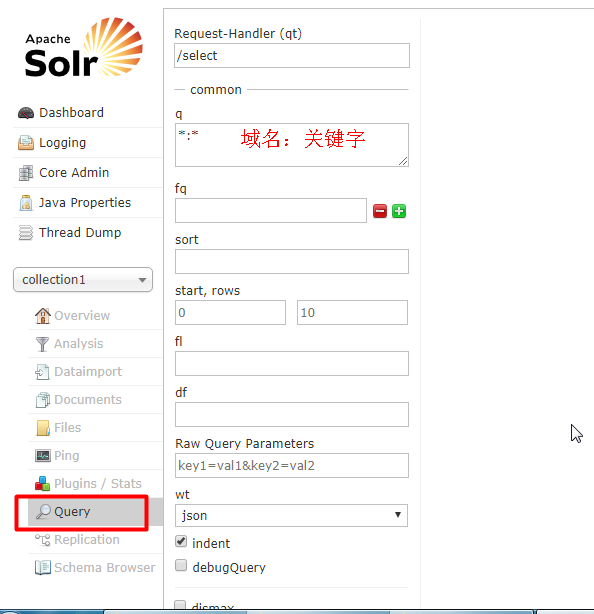
4: Schema.xml :
4-1:schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
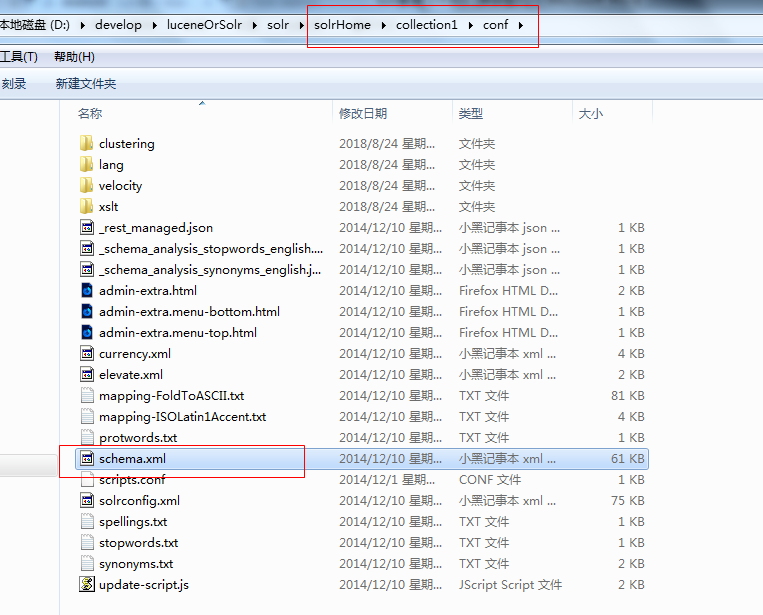
Field定义:
solr索引字段在solrhomecollection1confschema.xml配置文件中,类似下面这些,包含在<fields>与</fields>之间的。
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组
uniqueKey:
Solr中默认定义唯一主键key为id域,如下:
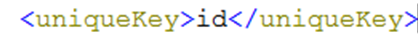
Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束。
copyField复制域:
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:
比如,输入关键字搜索title标题内容content,


dynamicField(动态字段)
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。

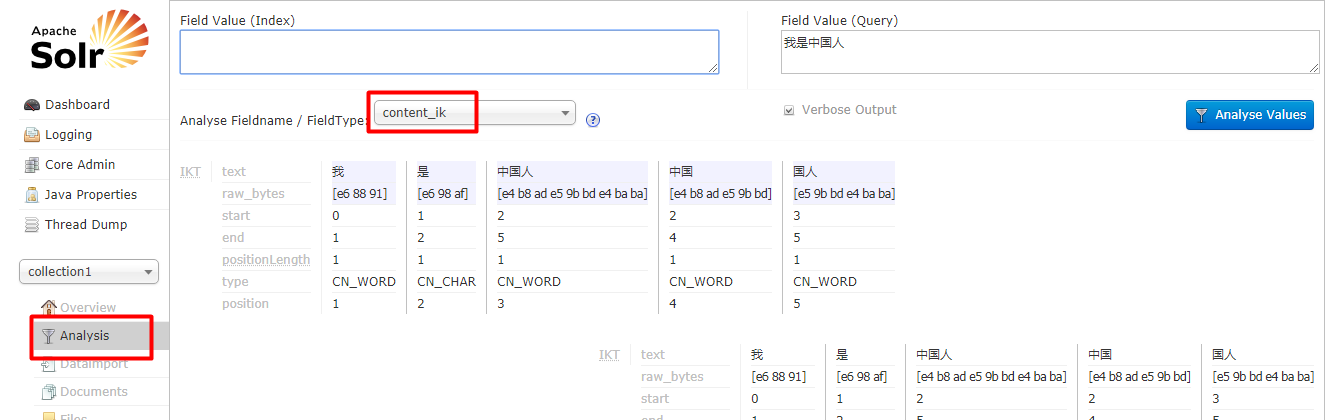
5-1:安装中文分词器:
使用IKAnalyzer中文分析器。
第一步:把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下。
第二步:复制IKAnalyzer的配置文件和自定义词典和停用词词典到solr的web-INF/classpath下:
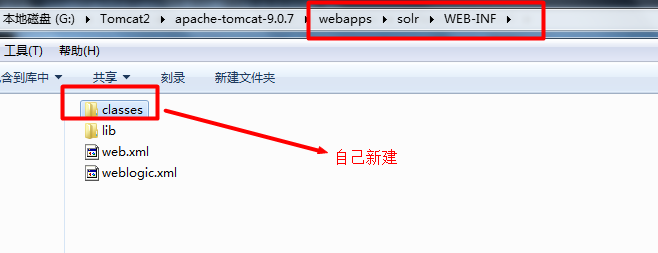
第三步:在schema.xml中添加一个自定义的fieldType,使用中文分析器。
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
第四步:定义field,指定field的type属性为text_ik
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
第五步:重启tomcat
测试: