Linux 写时复制技术
Linux fork
- fork是类Unix操作系统上创建进程的主要方法。fork用于创建子进程,也就是需要复制父进程得到,也可以说子进程是父进程的副本。在linux中,所有的进程都是通过init进程fork或者vofork生成的。
Linux exec
- exec函数的作用就是装载一个新程序(可执行映像)覆盖当前进程内存空间中的映像,从而执行不同的任务。exec函数在执行时会直接替换掉当前进程的地址空间。
Linux 进程虚拟地址空间
- 在介绍写时复制技术之前,先介绍一下进程的虚拟地址空间。
- 虚拟地址通过页表映射到物理内存,页表由操作系统维护并被处理器引用。内核空间在页表中拥有较高特权级,因为用户态程序试图访问这些页时会导致一个页错误。在Linux中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存。内核代码和数据总是可寻址的,随时准备处理中断和系统调用。用户地址空间的映射随进程切换的发生而不断变化。
- 用户进程部分分段存储如下表(按地址递减顺序)
| 名称 | 存储内容 | 由谁维护 |
|---|---|---|
| 栈 | 局部变量、函数参数、返回地址等 | 操作系统分配和管理 |
| 堆 | 动态分配的内存空间 | 程序员进行自己维护,申请和释放 |
| BSS段 | 未初始化或者初值为0的全局变量和静态局部变量 | 操作系统加载并进行分配空间 |
| 数据段 | 已初始化且初值非0的全局变量或和静态局部变量 | 操作系统加载并进行分配空间 |
| 代码段 | 可执行代码、字符串字面值、只读变量 | 操作系统加载并进行分配空间 |
栈
- 栈又称为堆栈,由编译器自动分配与释放。
- 栈能够为函数内部声明的非静态局部变量提供存储空间。
- 栈能够记录函数调用过程相关的维护性信息,称为栈帧或者活动记录。它包括函数返回地址,不适合装入寄存器的函数参数及一些寄存器值的保存。除递归调用外,堆栈并非必需。
- 栈能够暂存长算术表达式部分计算结果或alloca()函数分配的栈内内存。
- 持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈(在堆区)。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。此时若栈的大小低于堆栈最大值RLIMIT_STACK(通常是8M),则栈会动态增长,程序继续运行。映射的栈区扩展到所需大小后,不再收缩。
- 当程序使用的栈超过堆栈最大值时,会发生栈溢出,程序收到一个段错误。如果调高栈容量可能会增加内存开销和启动时间。
内存映射段
- 内存映射是一种高效的文件IO方式,内核能够直接将硬盘文件内容映射到内存,减少了拷贝次数,可以用来装载动态共享库。用户也可以创建匿名内存映射,该映射没有文件,可用于存放程序数据。在Linux系统中,如果通过malloc请求一大块内存,C运行库将会创建一个匿名内存映射,而不使用堆内存。”大块” 意味着比阈值 MMAP_THRESHOLD还大,缺省为128KB,可通过mallopt()调整。
堆
- 堆用于放进程运行时动态分配的内存段,可动态的扩张和缩减。堆中的内容是匿名的,不能按名字直接访问,只能通过指针间接访问。
- 分配的堆是经过字节对齐空间的,分配的内存往往比申请的内存要大。堆管理器通过链表管理每个申请的内存,由于堆申请和堆释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配和释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
- 堆的末端由break指针标识,当堆管理器需要更多内存时,可通过系统调用brk()和sbrk()来移动break指针以扩张堆,一般由系统自动调用。
BSS段
- BSS段主要是存放未初始化的全局变量和静态局部变量、初始值为0的全局变量和静态局部变量(依赖于编译器实现)、未定义且初值不为0的符号(该初值即common block的大小)。
- 在C语言中,未显式初始化的静态变量被初始化为0,由于程序加载时,BSS会被操作系统清0,所以未赋初值或者初值为0的全局变量都在BSS中,BSS段仅为未初始化的静态变量预留位,在目标文件中并不占据空间。因为程序索马里是需要为变量分配内存空间,所以目标文件必须记录所有未初始化的静态分配变量总和大小。
- 需要注意的是,虽然这几类变量都放置在BSS段,但是初始值为0的全局变量是强符号,而未初始化的全局变量是弱符号。若其他地方已定义同名的强符号(初值可能非0),则弱符号与链接时不会引起重定义错误,但运行时的初值可能并非期望值,因为会被强符号覆盖。因此,定义全局变量时,若只有本文件使用,则尽量使用static关键字修饰;否则需要为全局变量定义赋初值(哪怕0值),保证该变量为强符号,以便链接时发现变量名冲突,而不是被未知值覆盖。
数据段
- 数据段通常用于放程序中已初始化且初值不为0的全局变量和静态变量。数据段属于静态内存分配,也叫静态存储区,可读可写。
- 数据段保存在目标文件中,其内容由程序初始化,比如 int a = 10;目标文件数据段中必须保存10这个数据,然后在程序加载时复制到相应的内存。
- 与BSS段相比:
- BSS段不占用物理文件,但占用内存空间;数据段占用内存物理文件,也占用内容空间。比如int a[1000] = {1, 1, ..} 和 int b[1000],a存储在数据段,需要存储1,1...这些数据,而b存储在BSS段,不需要存储0,而是记录一下有多少字节就可以了。
- 当程序读数据段的数据时,系统会发出缺页中断,从而分配相应的物理内存,而数据读BSS段的数据时,内核会转到一个全零页面,不会发生缺页中断,也不会为其分配物理内存。
代码段
- 代码段又叫正文段,其实就是存储程序的可执行代码。通常代码段是可共享的并且是只读的,因为内存中只需要一份即可。
- 代码段指令中包括操作码和操作对象(或对象地址引用)。若操作对象是立即数(具体数值),将直接包含在代码中;若是局部数据,将在栈区分配空间,然后引用该数据地址;若位于BSS段和数据段,同样引用该数据地址。
分段的优点
- 程序执行过程会按照流程顺序,代码只需要访问一次(跳转可能会出现多次),而数据通常会访问多次,单独将它们分开,会方便访问和节约空间。
- 当程序被装载后,数据和指令分别映射到两个虚存区域。数据区对于进程而言可读写,而指令区对于进程只读。两区的权限可分别设置为可读写和只读。以防止程序指令被有意或无意地改写。
- 现代CPU具有极为强大的缓存(Cache)体系,程序必须尽量提高缓存命中率。指令区和数据区的分离有利于提高程序的局部性。现代CPU一般数据缓存和指令缓存分离,故程序的指令和数据分开存放有利于提高CPU缓存命中率。
- 当系统中运行多个该程序的副本时,其指令相同,故内存中只须保存一份该程序的指令部分。
- 临时数据及需要再次使用的代码在运行时放入栈区中,生命周期短。全局数据和静态数据可能在整个程序执行过程中都需要访问,因此单独存储管理。堆区由用户自由分配,以便管理。
页表
- 逻辑地址:是程序编译后,生成的目标模块进行编址时都是从0号开始编址,称之为目标模块的相对地址,即逻辑地址。
- 虚拟地址:计算机处理器的地址有32位和64位的两种,对应的虚拟地址的空间大小分别是(2^{32})和(2^{64})字节,也就是寻址空间的大小。
- 页面:分页存储管理器将进程的逻辑地址空间划分为若干页面,并且对其编号,号数从0开始,每个页面的大小应为2的幂。
- 物理块:将内存的物理地址空间划分为若干块,称为物理块,也叫页框号,物理块与页面一一对应。
- 页表:存储在内存中,通过页表建立页面与物理块的索引。
- 页表项:页表项就是页表中每一行,每一项都代表一个页表与物理块的映射关系。需要注意的是,页表项中并没有存储页号,只有20位的页框号,剩的12位是附加的控制位。在计算页表项地址时,要求页表连续并且足够长(2的20次方页,页表项长度4B,对应的是4MB)以映射全部物理地址空间,然后页号和页框号的对应关系就可以用如下公式体现出来:页表项(只含页框号)地址=页表起始地址+页号×页表项长度,而无需多花20位再来存储页号。
写时复制原理
非写时复制fork一个子进程
- 首先需要复制父进程的栈、堆、BSS段、数据段和代码段,如下图:
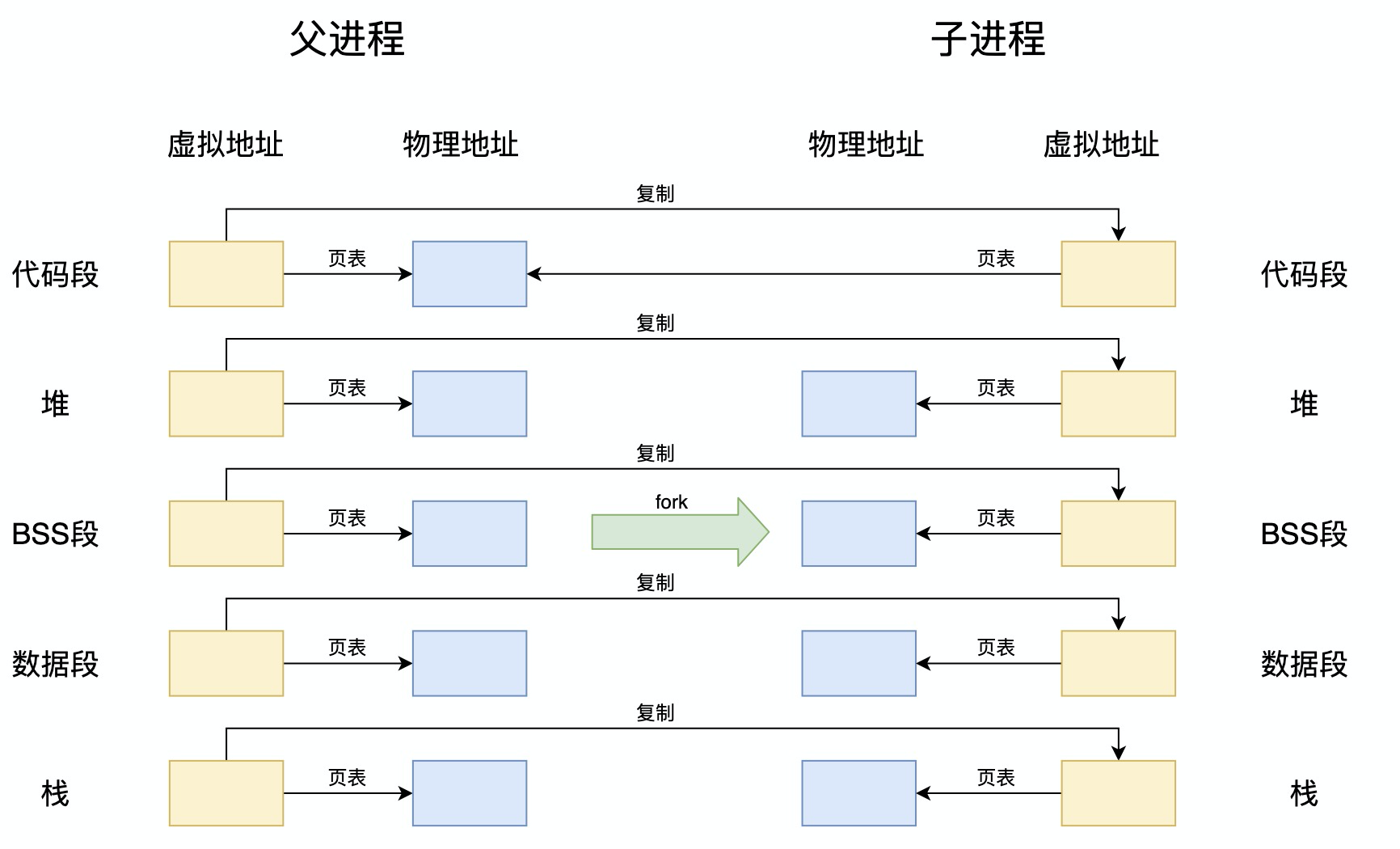
- 可以看出,子进程需要先复制父进程的虚拟地址、物理地址等信息(除了共享的代码段),这相当于复制了一个完全相同的父进程。但是如果子进程接下来再执行exec函数时,那么就会替换子进程的地址空间,那么刚才的拷贝将完全没有意义,只是浪费了时间而已,所以就有了写时复制技术。
写时复制fork子进程
- 只需要复制父进程的虚拟地址空间如下图
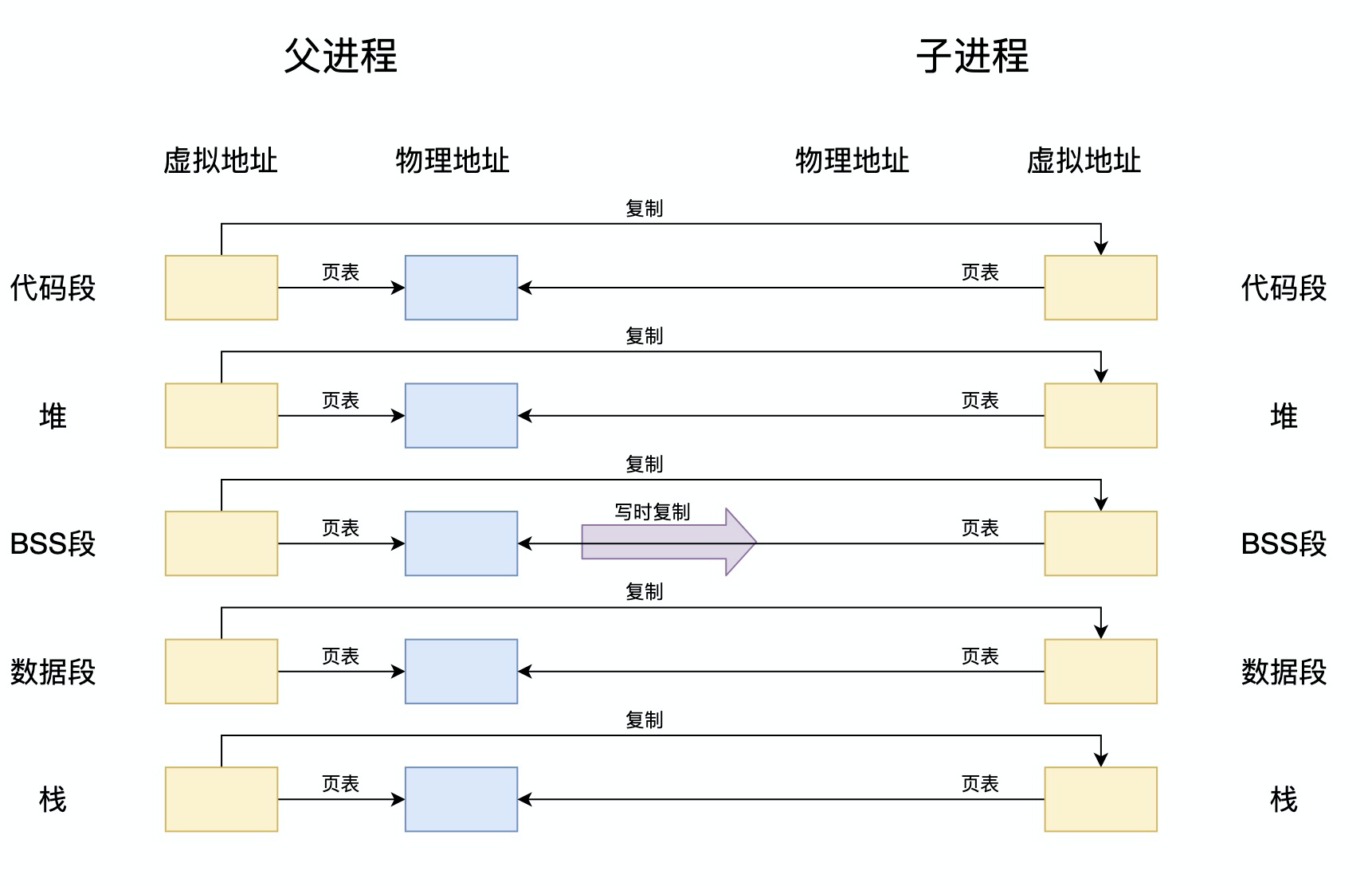
- 可以看出来,使用写进复制时,子进程只需要拷贝父进程的虚拟地址、页表等数据就可以获得到父进程的所有数据了。如果数据都只是读取,那么可以一直使用这个模式,并不会有任何影响。如果需要对有修改操作,只需要重新申请一块内容,将新数据写入,并修改页表映射关系即可。
- redis的生成RDB时,主进程fork子进程就是使用这种方式。首先子进程先拷贝父进程的虚拟空间和页表等信息,然后共用父进程的物理地址,如果父进程(也就是redis的主进程)有更新操作,read-only内存页发生中断,将触发的异常的内存页复制一份,就需要重新申请内存,然后更新数据,再修改页表映射,这样能够降低CPU的负载,并且提高接口的响应速度,不会阻塞主进程。同时需要注意的时,主进程在拷贝一个内存页里,会拷贝一个完整的内存页,不会因为写只了10B,而只拷贝10B大小,还是一个完整的内存页,默认应该是4K。但是如果linux开启了大内存页模式的话,就有可能会产生2M的大内存页,这里也是完全拷贝,就有可能阻塞进程,需要特别注意。如果不想开启,可以关闭。
vfork一个子进程
- 这种方式更加暴力,子进程直接将指针指向父进程的虚拟地址,连拷贝虚拟地址都省下了。