-背景:
鉴于我们使用mongo作为数据库,期间少不了需要添加索引和对业务表进行设计。因此以下我对mongo索引及表设计原则做了一些分享。希望对大家有用,如有错误还望指正~
MongDB的索引类型简介:
-单键索引、复合索引、多键索引、地理空间索引、全文本索引和哈希索引
1,单建索引
db.table.createIndex({"user_id":1})
1:升序 -1:降序
使用说明:只要查询中包含user_id即可使用索引 无论是在find条件中 还是在sort中 1,-1都会使用
2,复合索引
db.table.createIndex({"user_id":1,"name":-1})
使用说明:使用上述索引查询中sort中只有当条件是{"user_id":1,"name":-1} 和{"user_id":-1,"name":1},{"user_id":1 or -1}的时候才会使用索引
find中只要包含user_id才会使用,不能够创建基于哈希索引类型的复合索引 ,任意复合索引字段不能超过31个
3,多键索引
针对value是[]类型的mongo会自动建立多键索引,
db.table.createIndex( { "stock": 1 }
{
_id: 1,
item: "abc",
stock: [1,4,5,6]
}
当文档如下json所示的结构时可以建立内嵌文档索引:
db.table.createIndex( { "stock.size": 1, "stock.quantity": 1 } )
{
_id: 1,
item: "abc",
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
}
使用说明:对于一个复合多键索引,每个索引最多可以包含一个数组。
4,地理空间索引
2dsphere 允许使用GeoJSON格式(http://www.geojson.org)指定点、线和多边形。
创建一个地理空间索引:
db.world.createIndex({"loc": "2dsphere"})
可以使用多种不同的地理空间查询:交集(intersection)、包含(within)以及接近(nearness)。查询时,需要将希望查找的内容指定为形如 {"$geometry":geoJsonDesc}
的 GeoJSON 对象。
另外还有一个2d类型类似更趋于平面化数据的处理这里不做过多介绍
5,全文索引
全文索引用于在文档中搜索文本,我们也可以使用正则表达式来查询字符串,但是当文本块比较大的时候,正则表达式搜索会非常慢,而且无法处理语言理解的问题(如 entry
和 entries 应该算是匹配的)。使用全文索引可以非常快地进行文本搜索,就如同内置了多种语言分词机制的支持一样。创建索引的开销都比较大,全文索引的开销更大。创建
索引时,需后台或离线创建。
db.table.createIndex({"content": "text"})
使用全文索引查询内容:
db.table.find({"$text": {"$search": "coffee"}})
6,哈希索引
哈希索引可以支持相等查询,但是哈希索引不支持范围查询。无法创建一个带有哈希索引键的复合索引或者对哈希索引施加唯一性的限制。但是可以在同一个键上同时创建一个
哈希索引和一个递增/递减(例如,非哈希)的索引,这样MongoDB对于范围查询就会自动使用非哈希的索引。
db.table.createIndex({"user_id": "hashed"})
MongDB的索引属性介绍:
1,TTL索引
TTL索引是一种特殊索引,通过这种索引MongoDB会过一段时间后自动移除集合中的文档。这对于某些类型的信息来说是一个很理想的特性,例如机器生成的事件数据、日志、
会话信息等,这些数据都只需要在数据库中保存有限时间。
TTL索引有如下限制:
-
-
它不支持复合索引 。
-
被索引键必须是日期类型的数据。
-
如果这个键存储的是一个数组,且在索引中有多个日期类型的数据(和一篇文档关联),那么当其中最低 (比如,最早)过期阀值得到匹配时,这篇文档就会过期失效了。
-
TTL索引不能保证过期数据会被立刻删除。在文档过期和MongoDB从数据库中删除文档之间,可能会有延迟。删除过期数据的后台任务 每隔60秒 运行一次。所以,在文档过期
之后 和 后台任务运行或者结束 之前 ,文档会依然存在于集合中。删除操作的持续实际取决于您的 mongod 实例的负载。因此,在两次后台任务运行的间隔间,过期数据可能会
继续留在数据库中超过60秒。在其他方面,TTL索引是普通索引,并且如果可以的话,MongoDB会使用这些索引来匹配任意查询。
db.token.createIndex({"lastUpdated": 1}, {"expireAfterSecs": 60*60*24})
token 超过24小时就会被删除掉。
2,唯一索引
唯一索引可以拒绝保存那些被索引键的值已经重复的文档。
db.table.createIndex({"user_id": 1}, {unique: true})
唯一性同样适用use_id.a内嵌字段上
3,稀疏索引
稀疏索引会跳过所有不包含被索引键的文档。这个索引之所以称为 “稀疏” 是因为它并不包括集合中的所有文档。与之相反,非稀疏的索引会索引每一篇文档,如果一篇文档不含被
索引键则为它存储一个null值。
db.table.createIndex({"xmpp_id": 1}, {"sparse": true})
如果一个索引会导致查询或者排序的结果集是不完整的,那么MongoDB将不会使用这个索引,除非用户使用 hint() 方法来显示指定索引。例如,查询 { x: { $exists: false } }和sort
中使用x字段将不会使用 x 键上的稀疏索引,或者sort中适用改字段,除非显示的hint。
4,部分索引
部分索引只为那些在一个集合中,满足指定的筛选条件的文档创建索引。由于部分索引是一个集合文档的一个子集,因此部分索引具有较低的存储需求,并降低了索引创建和维护
的性能成本。部分索引通过指定过滤条件来创建,可以为MongoDB支持的所有索引类型使用部分索引。
db.persons.createIndex({country:1},{partialFilterExpression: {age: {$gt:25}}})
-索引创建
前台方式:
当为一个集合创建索引时,这个操作将阻塞其他的所有操作。即该集合上的无法正常读写,直到索引创建完毕
后台方式:
适用于那些需要长时间创建索引的情形 这样子在创建索引期间,MongoDB依旧可以正常的为提供读写操作服务
db.people.createIndex( { zipcode: 1}, {background: true} )
后台创建索引比前台慢,如果索引大于实际可用内存,则需要更长的时间来完成索引创建
所有涉及到该集合的相关操作在后台期间其执行效能会下降,应在合理的维护空挡期完成索引的创建
db.currentOp():查看当前创建进度 db.killOp():杀掉创建进程
-索引数据结构B-tree B+tree
索引的本质:索引是数据结构
树型结构查询的有时
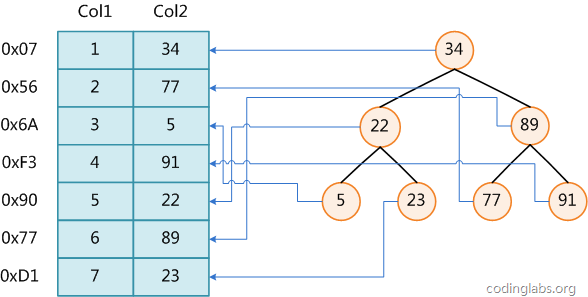
B-tree结构:
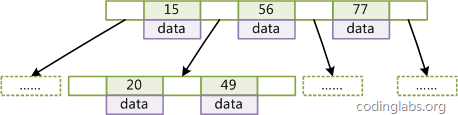
带有顺序访问指针的B+Tree
B-Tree:更少次数的磁盘I/O(一般使用磁盘I/O次数评价索引结构的优劣)
根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B+Tree:查询效率高更适合外存索引(感觉这就是mongo会把索引放到内存里的原因)
原因和内节点出度d有关。从上面分析可以看到,d越大索引的性能越好,而出度的上限取决于节点内key和data的大小:
dmax = floor(pagesize / (keysize + datasize + pointsize)) (pagesize – dmax >= pointsize)
或 dmax = floor(pagesize / (keysize + datasize + pointsize)) – 1 (pagesize – dmax < pointsize)
floor表示向下取整。由于B+Tree内节点去掉了data域,因此可以拥有更大的出度,拥有更好的性能。
此处参考文章:http://blog.jobbole.com/24006/
-表结构设计
1,完全分离(范式化设计)
利于更新,不利于查询(需要级联作者表查询作者信息)
{
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
ObjectId("144b5d83041c7dca84416"),
ObjectId("144b5d83041c7dca84418"),
ObjectId("144b5d83041c7dca84420"),
]
}
{
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
{
"name" : "丁磊"
"age" : 40,
"nationality" : "china",
},
{
"name" : "马云"
"age" : 49,
"nationality" : "china",
},
{
"name" : "张召忠"
"age" : 59,
"nationality" : "china",
},
]
}
3,部分内嵌(折中方案)
特定场景,人名更新频次很低且业务查询只需要作者姓名
{
"_id" : ObjectId("5124b5d86041c7dca81917"),
"title" : "如何使用MongoDB",
"author" : [
{
"_id" : ObjectId("144b5d83041c7dca84416"),
"name" : "丁磊"
},
{
"_id" : ObjectId("144b5d83041c7dca84418"),
"name" : "马云"
},
{
"_id" : ObjectId("144b5d83041c7dca84420"),
"name" : "张召忠"
},
]
}
-如何做好那些重要但不紧急的事情
让未来可视化,将结果拉近,呈现得具体清晰,倒逼种因。
在正面谋求自律,从反面寻找他律。
前期咬紧牙关,后期交给惯性
叫醒你的,不是闹钟,也未必是梦想,是生物钟,是原理的运用,是客观规律。
文章链接:https://www.jianshu.com/p/264a3bc87cd0