我只是想看一下大家都是啥时候发博客而已!!
第一步:
把 https://www.cnblogs.com/ 的文章列表先拿下来,只有200页,时间范围是一个月多几天,不知道是不是全部的,就这样吧
代码很简单:https://github.com/dytttf/little_spider/blob/master/cnblogs/blog_index_spider.py
数据格式如下:
data = { "https://www.cnblogs.com/xxx.html": { "url": "https://www.cnblogs.com/xxx.html", "title": "xxx", "summary": "xxx", "author": "xxx", "author_url": "https://www.cnblogs.com/xxx/", "ctime": "2019-11-11 11:11" } }
第二步:
使用pandas把数据都加载进来
data_list = list(data.values())
df = pd.DataFrame(data_list)
第三步:
转换一下发布时间格式,然后去掉一下30天之外的数据
# 转换时间格式 df["ctime"] = pd.to_datetime(df["ctime"]) # 去掉30天之外的 df = df[df["ctime"] > df["ctime"].max() - datetime.timedelta(days=30)]
第四步:
获取一下小时分布,画个图看看
df["hour"] = df["ctime"].apply(lambda x: x.hour) hour_counter = df["hour"].value_counts().sort_index() hour_counter.plot.bar() plt.show()
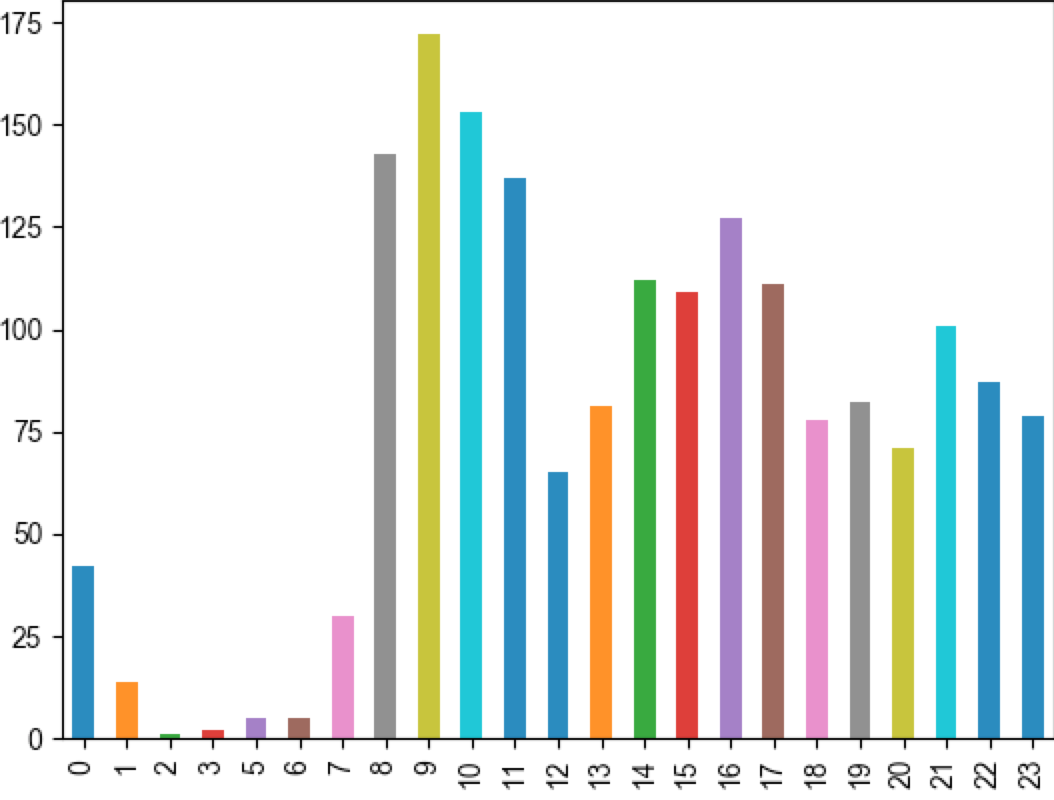
有点小惊讶,早上竟然这么多。我一直以为晚上会是高峰,看来大家白天很闲啊。不过也有可能是昨天晚上写好了,没来得及发吧
本想就此结束,不过图都开始画了,在多画几张吧
第五步:
不知道一个月内哪天发布的博客比较多,看一下
df["day"] = df["ctime"].apply(lambda x: x.day) day_counter = df["day"].value_counts().sort_index() day_counter.plot.bar() plt.show()
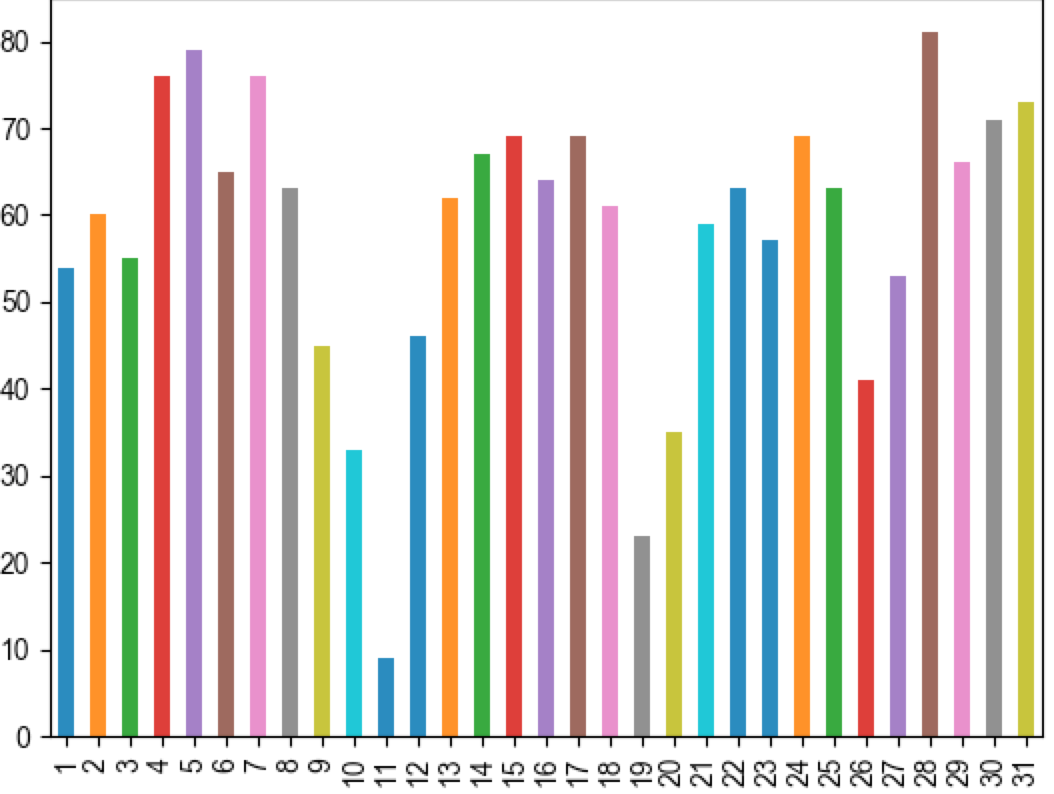
好吧,这个好像还是挺平均的,没啥可看的
第六步:
看一下有没有博客狂人
author_counter = df["author"].value_counts()[:100] author_counter.plot.bar() # 输出前五 print(author_counter[:5]) plt.show()
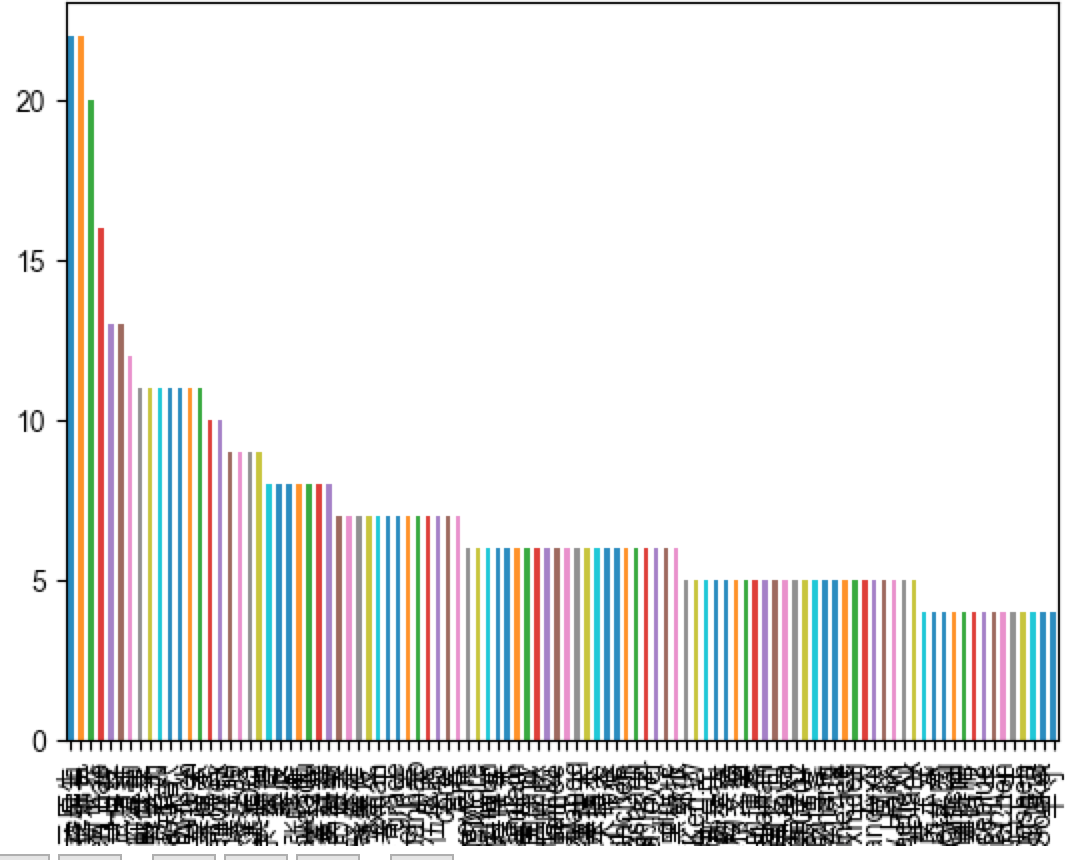
好像也没有特别多的,看一下前5都是谁吧
""" 阿里巴巴云原生 22 极客挖掘机 22 程序新视界 20 chen_hao 16 赐我白日梦 13 """
第七步:
看一下大家都在发啥类型的帖子,对标题分词做个词云
for cat in ["title", "summary"]: text = re.sub("[^w]", " ", " ".join(list(df[cat]))) # 清理空格和单字 word_counter = Counter([x for x in jieba.cut(text) if len(x.strip()) > 1]) top_30 = word_counter.most_common(30) # 词云 title_word_cloud = WordCloud( background_color="white", font_path="simsun.ttf" ).generate_from_frequencies(dict(top_30)) plt.imshow(title_word_cloud) plt.axis("off") plt.show()
标题词云:

ps:
1、身为Pythoneer,很不服Java
2、如何?大家很喜欢用问句作为标题?
3、一系列各种实现、源码、解析、框架、模式、原理。感觉学不过来了
摘要词云:

ps:
1、我们使用一个啥?可以实现啥?博主都很喜欢用我们来拉近距离:)
词云还是挺好玩的。。。
最后附上代码:
https://github.com/dytttf/little_spider/blob/master/cnblogs/analysis.py