缓存:第一种是内存缓存 比如Map(简单的数据结构),以及EH Cache(Java第三方库),第二种是缓存组件比如Memached,Redis;Redis(remote dictionary server)是一个基于KEY-VALUE的高性能的存储系统,通过提供多种键值数据类型来适应不同场景下的缓存与存储需求。
string类型:字符串类型是redis中最基本的数据类型,它能存储任何形式的字符串,包括二进制数据。你可以用它存储用户的 邮箱、json化的对象甚至是图片。一个字符类型键允许存储的最大容量是512M 。在Redis内部,String类型通过 int、SDS(simple dynamic string)作为结构存储,int用来存放整型数据,sds存放字节/字符串和浮点型数据。在C的标准字符串结构下进行了封装,用来提升基本操作的性能,同时也充分利用已有的C的标准库,简化实现逻辑。

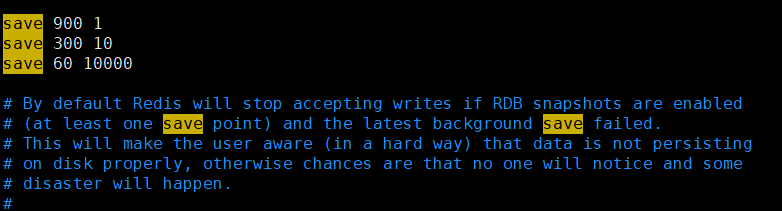
RDB方式:Redis借助了fork命令的copy on write机制。在生成快照时,将当前进程fork出一个子进程,然后在子进程中循环所有的数据,将数据写成RDB文件。Redis的RDB文件不会坏掉,因为写操作是在一个新进程中进行的,Redis先将数据写到一个临时文件中,通过原子性rename系统调用将临时文件重命名为RDB文件 ,即使出现故障,最后一个保存的RDB文件也是可用的,同时,Redis的RDB文件也是Redis主从同步内部实现中的一环。通过Redis的save指令来配置RDB快照生成的时机,比如你可以配置当10分钟以内有100次写入就生成快照,也可以配置当1小时内有1000次写入就生成快照,也可以多个规则一起实施,下面是默认配置:
Redis还提供了人工干预RDB快照的方式
用户执行SAVE或BGSAVE命令
save命令:当执行save命令时,Redis同步做快照操作,在快照执行过程中会阻塞所有来自客户端的请求。当redis内存中的数据较多时,通过该命令将导致Redis较长时间的不响应。所以不建议在生产环境上 使用这个命令,而是推荐使用bgsave命令。
bgsave命令:可以在后台异步地进行快照操作,快照的同时服务器还可以继续响应来自客户端的请求。执行BGSAVE后,Redis会立即返回ok表示开始执行快照操作。(默认快照方式)。
LASTSAVE命令:可以获取最近一次成功执行快照的时间。
RDB方式缺点:RDB有它的不足,就是一旦数据库出现问题,那么我们的RDB文件中保存的数据并不是全新的,从上次RDB文件生成到 Redis停机这段时间的数据全部丢掉了。在某些业务下,这是可以忍受的,我们也推荐这些业务使用RDB的方式进行持久化,因为开启RDB的代价并不高。 但是对于另外一些对数据安全性要求极高的应用,无法容忍数据丢失的应用,RDB就无能为力了,所以Redis引入了另一个重要的持久化机制:AOF日志。
AOF方式:AOF日志的全称是Append Only File,从名字上我们就能看出来,它是一个追加写入的日志文件。与一般数据库不同的是,AOF文件是可识别的纯文本,它的内容就是一个个的Redis标准命令。AOF可以将Redis执行的每一条写命令追加到硬盘文件中,这一过程会降低Redis的性能,但大部分情况下这个影响是能够接受的,另外使用较快的硬盘可以提高AOF的性能。
下面是redis.conf里面的默认配置:
开启AOF方式为:appendonly yes 即可。
AOF重写:
Redis中对AOF调用write写入后,何时再调用fsync将其写到磁盘上,通过appendfsync选项来控制,下面appendfsync的三个设置项,安全强度逐渐变强。
appendfsync no:当设置appendfsync为no的时候,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,所以这一切就完全依赖于操作系统的调试了。对大多数Linux操作系统,是每30秒进行一次fsync,将缓冲区中的数据写到磁盘上。
appendfsync everysec:当设置appendfsync为everysec的时候,Redis会默认每隔一秒进行一次fsync调用,将缓冲区中的数据写到磁盘。但是当这一 次的fsync调用时长超过1秒时。Redis会采取延迟fsync的策略,再等一秒钟。也就是在两秒后再进行fsync,这一次的fsync就不管会执行多长时间都会进行。这时候由于在fsync时文件描述符会被阻塞,所以当前的写操作就会阻塞。所以,结论就是:在绝大多数情况下,Redis会每隔一秒进行一次fsync。在最坏的情况下,两秒钟会进行一次fsync操作。这一操作在大多数数据库系统中被称为group commit,就是组合多次写操作的数据,一次性将日志写到磁盘。
appednfsync always:当设置appendfsync为always时,每一次写操作都会调用一次fsync,这时数据是最安全的,当然,由于每次都会执行fsync,所以其性能也会受到影响。
Redis 的pipeline的操作,其具体过程是客户端一次性发送N个命令,然后等待这N个命令的返回结果被一起返回。通过采用pipilining 就意味着放弃了对每一个命令的返回值确认。由于在这种情况下,N个命令是在同一个执行过程中执行的。所以当设置appendfsync为everysec 时,可能会有一些偏差,因为这N个命令可能执行时间超过1秒甚至2秒。但是可以保证的是,最长时间不会超过这N个命令的执行时间和。
利用RDB和AOF启动上区别:启动时间有一些差别。RDB的启动时间会更短,原因有两个,一是RDB文件中每一条数据只有一条记录,不会像 AOF日志那样可能有一条数据的多次操作记录。所以每条数据只需要写一次就行了。另一个原因是RDB文件的存储格式和Redis数据在内存中的编码格式是一致的,不需要再进行数据编码工作。在CPU消耗上要远小于AOF日志的加载。
3.Redis过期时间设置和内存回收策略
过期时间设置:expire命令设置一个键的过期时间,到期以后Redis会自动删除它。这个在我们实际使用过程中用 得非常多。具体用法EXPIRE key seconds,EXPIRE 返回值为1表示设置成功,0表示设置失败或者键不存在,

定期删除(active way): 1.随机测试 20 个带有timeout信息的key;2.删除其中已经过期的key;3.如果超过25%的key被删除,则重复执行步骤。
惰性删除(passive way): 在主键被访问时如果发现它已经失效,那么就删除它。
采用定期删除+惰性删除就万事大吉吗?不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。在redis.conf中有一行配置 # maxmemory-policy volatile-lru
