整理一些MySQL与SqlServer不同的地方
一、MySQL 8.0之后的修改用户密码问题
https://www.cnblogs.com/aop-liu/p/11161277.html
二、Navicat for MySQL:快捷键整理
ctrl+q 打开查询窗口 ctrl+/ 注释sql语句 ctrl+shift +/ 解除注释 ctrl+r 运行查询窗口的sql语句 ctrl+shift+r 只运行选中的sql语句 F6 打开一个mysql命令行窗口 ctrl+d (1):查看表结构详情,包括索引 触发器,存储过程,外键,唯一键;(2):复制一行 ctrl+l 删除一行 ctrl+n 打开一个新的查询窗口 ctrl+w 关闭一个查询窗口 ctrl+tab 多窗口切换
三、分组 之 WITH ROLLUP
GROUP BY 语句与SqlServer相同;WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
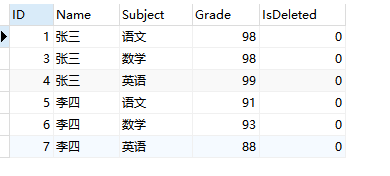
①有grade(成绩)表 数据如下:
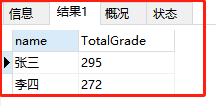
②基本的GROUP BY
SELECT name,sum(grade) TotalGrade FROM grade GROUP BY `Name`
③将成绩按名字进行分组,再统计全部人的总分(虽然没啥意义):
SELECT name,sum(grade) TotalGrade FROM grade GROUP BY `Name` WITH ROLLUP
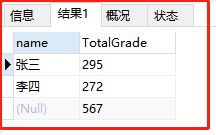
其中记录 NULL 表示所有人的分数和。
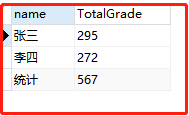
④我们可以使用 coalesce 来设置一个可以取代 NUll 的名称,coalesce 语法:
select coalesce(a,b,c);
参数说明:如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null(没意义)。
SELECT COALESCE(name,'统计') name,sum(grade) TotalGrade FROM grade GROUP BY `Name` WITH ROLLUP
四、正则表达式
使用 REGEXP 操作符来进行正则表达式匹配。下表中的正则模式可应用于 REGEXP 操作符中:
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ' ' 或 ' ' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ' ' 或 ' ' 之前的位置。 |
| . | 匹配除 " " 之外的任何单个字符。要匹配包括 ' ' 在内的任何字符,请使用象 '[. ]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
为方便测试,在grade(成绩)表中添加了一列'Remark',随便存放些字符串,以便测试
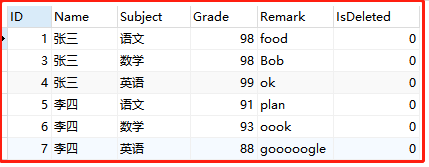
实例:
①查找Remark字段中以'o'为开头的所有数据:
-- 以‘o’ 开始 SELECT*FROM grade WHERE Remark REGEXP '^o'

②查找Remark字段中以'k'为结尾的所有数据:
-- 以‘k’结尾 SELECT*FROM grade WHERE Remark REGEXP 'k$'
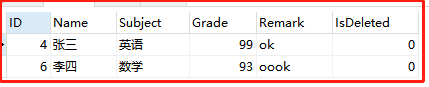
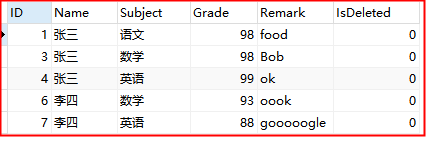
③查找Remark字段中 至少有1个'o'的所有数据:
-- 至少有1个‘o’ SELECT*FROM grade WHERE Remark REGEXP 'o+' --等价于 SELECT*FROM grade WHERE Remark REGEXP 'o{1,}'
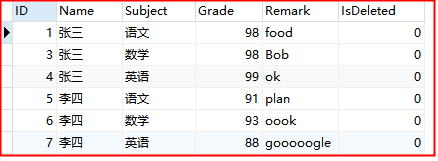
④查找Remark字段中 至少有0个'o'的所有数据:
-- 至少有0个‘o’ SELECT*FROM grade WHERE Remark REGEXP 'o*' -- 等价于 SELECT*FROM grade WHERE Remark REGEXP 'o{0,}'
⑤ 查找Remark字段中 以元音字母(即a,e,i,o,u)开头或以‘le’结尾的所有数据:
SELECT*FROM grade WHERE Remark REGEXP '^[aeiou]|le$'

⑥ 查找Remark字段中包含'la'的所有数据:
-- 包含‘la’ SELECT*FROM grade WHERE Remark REGEXP 'la'
