1.使用L1,L2正则化防止过拟合的原理
L1正则化是使得那些原先在0附近的权重参数W往零移动,从而减弱那些可能是某些批次数据所特有的特征对网络模型的影响,它偏向于产生少量的特征。L2正则化起到使得权重参数W变小加巨的效果,从而降低网络模型的复杂度,W的减小会使得激活函数的取值范围减小,一定程度上会使得网络每层都更加接近于线性化,从而使网络整体变得更加简单,以此来防止过拟合。
以下是NG课程中的图片:
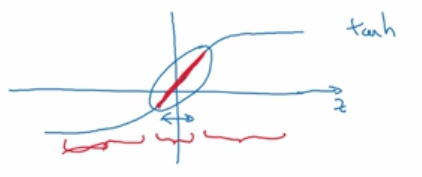
使得取值变得只有红线部分的那一段,接近于线性化。
2.dropout相关
不同dropout的具体总结(https://cloud.tencent.com/developer/article/1441530)
https://zhuanlan.zhihu.com/p/64841554
https://mp.weixin.qq.com/s/c7XkzjLH1n5EtqdQik618g
1)dropout相关介绍
对于标准dropout,它可以让模型训练时,随机让网络的某些节点不工作(神经元的激活值置零),相应权重不更新。对于常提到的标准dropout在前馈神经网络中的应用如下

我们dropout比率选择0.6意思是每个神经元有0.6的概率被保留下来,有0.4的概率会删除,那么我们的期望是每层有0.4的神经元被删除,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的激活值被置为0。(drop_out的值是控制神经元以多大比率被保留)。
标准dropout的实现参照(https://www.cnblogs.com/zingp/p/11631913.html)
dropout在RNN中的应用(https://www.jianshu.com/p/be34e53d54e6)
在RNN上使用dropout一般是对RNN其相关的Cell使用tf.nn.rnn_cell.DropoutWrapper进行包装,结合其相应的参数分析RNN中dropout的使用
__init__(
cell,
input_keep_prob=1.0,
output_keep_prob=1.0,
state_keep_prob=1.0,
variational_recurrent=False,
input_size=None,
dtype=None,
seed=None,
dropout_state_filter_visitor=None
)
由参数可知有三个概率值用于控制dropout,首先是input_keep_prob以及output_keep_prob,对应的为垂直dropout,垂直dropout如下

虚线表示应用dropout的地方,RNN中这种形式的dropout应用在输入、输出以及不同层RNN之间的连接处,不应用在RNN的隐藏层中,应用在输入处是每个时刻的输入以一定的概率保留下来作为输入(不置为0),应用在输出处是输出以一定的概率保留下来作为输出(不置为0)
state_keep_prob需要和variational_recurrent结合使用,实现的为变分dropout(对应于论文《A Theoretically Grounded Application of Dropout in Recurrent Neural Networks》)
使用变分dropout一方面需要设定state_keep_prob的值另一方面需要把variational_recurrent的值设定为True
变分dropout的应用对LSTM公式的改变如下:


参考论文(https://arxiv.org/pdf/1904.13310.pdf)
3)它能有效防止过拟合的原因:
NG的课程中:每次次随机的使得一部分的网络节点失活,能够使得神经网络变的更加简单,从而有效的防止了过拟合。同时对于每一个节点而言,由于每个节点都可能会失活,自然就不会为相应的特征赋予过大的权重,即为会使得W变小,从而起到和L2正则化相同的作用。
dropout(相当于增加特征的组合情况)减少神经元之间复杂的共适应关系:因为dropout的存在,导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
取平均的作用,dropout掉不同的隐藏神经元就类似在训练不同的网络,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
因此也可以说dropout是bagging思想的一个特例,它所增加的是特征的多样性,每次选用不同的特征组合来训练网络模型。
3.激活函数相关
1)为什么要用激活函数?
因为使用激活函数使得神经网络具有拟合非线性函数的能力,使得其具有强大的表达能力!(非线性变换是深度学习有效的原因之一。原因在于非线性相当于对空间进行变换,变换完成后相当于对问题空间进行简化,原来线性不可解的问题现在变得可以解了。)
2)激活函数应该具备的特征:
1. 非线性:即导数不是常数。这个条件前面很多答主都提到了,是多层神经网络的基础,保证多层网络不退化成单层线性网络。这也是激活函数的意义所在。
2. 几乎处处可微:可微性保证了在优化中梯度的可计算性。传统的激活函数如sigmoid等满足处处可微。对于分段线性函数比如ReLU,只满足几乎处处可微(即仅在有限个点处不可微)。对于SGD算法来说,由于几乎不可能收敛到梯度接近零的位置,有限的不可微点对于优化结果不会有很大影响[1]。
3. 计算简单:正如题主所说,非线性函数有很多。极端的说,一个多层神经网络也可以作为一个非线性函数,类似于Network In Network[2]中把它当做卷积操作的做法。但激活函数在神经网络前向的计算次数与神经元的个数成正比,因此简单的非线性函数自然更适合用作激活函数。这也是ReLU之流比其它使用Exp等操作的激活函数更受欢迎的其中一个原因。
4. 非饱和性(saturation):饱和指的是在某些区间梯度接近于零(即梯度消失),使得参数无法继续更新的问题。最经典的例子是Sigmoid,它的导数在x为比较大的正值和比较小的负值时都会接近于0。更极端的例子是阶跃函数,由于它在几乎所有位置的梯度都为0,因此处处饱和,无法作为激活函数。ReLU在x>0时导数恒为1,因此对于再大的正值也不会饱和。但同时对于x<0,其梯度恒为0,这时候它也会出现饱和的现象(在这种情况下通常称为dying ReLU)。Leaky ReLU[3]和PReLU[4]的提出正是为了解决这一问题。
5. 单调性(monotonic):即导数符号不变。这个性质大部分激活函数都有,除了诸如sin、cos等。个人理解,单调性使得在激活函数处的梯度方向不会经常改变,从而让训练更容易收敛。
6. 输出范围有限:有限的输出范围使得网络对于一些比较大的输入也会比较稳定,这也是为什么早期的激活函数都以此类函数为主,如Sigmoid、TanH。但这导致了前面提到的梯度消失问题,而且强行让每一层的输出限制到固定范围会限制其表达能力。因此现在这类函数仅用于某些需要特定输出范围的场合,比如概率输出(此时loss函数中的log操作能够抵消其梯度消失的影响[1])、LSTM里的gate函数。
7. 接近恒等变换(identity):即约等于x。这样的好处是使得输出的幅值不会随着深度的增加而发生显著的增加,从而使网络更为稳定,同时梯度也能够更容易地回传。这个与非线性是有点矛盾的,因此激活函数基本只是部分满足这个条件,比如TanH只在原点附近有线性区(在原点为0且在原点的导数为1),而ReLU只在x>0时为线性。这个性质也让初始化参数范围的推导更为简单[5][4]。额外提一句,这种恒等变换的性质也被其他一些网络结构设计所借鉴,比如CNN中的ResNet[6]和RNN中的LSTM。
8. 参数少:大部分激活函数都是没有参数的。像PReLU带单个参数会略微增加网络的大小。还有一个例外是Maxout[7],尽管本身没有参数,但在同样输出通道数下k路Maxout需要的输入通道数是其它函数的k倍,这意味着神经元数目也需要变为k倍;但如果不考虑维持输出通道数的情况下,该激活函数又能将参数个数减少为原来的k倍。
9. 归一化(normalization):这个是最近才出来的概念,对应的激活函数是SELU[8],主要思想是使样本分布自动归一化到零均值、单位方差的分布,从而稳定训练。在这之前,这种归一化的思想也被用于网络结构的设计,比如Batch Normalization[9]。
3)常用的激活函数及其优缺点
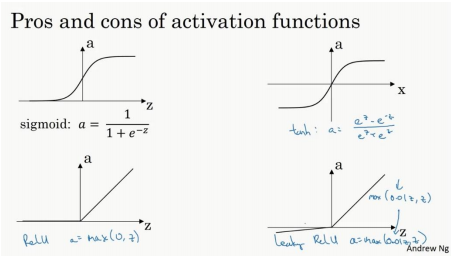
Sigmoid['sɪgmɔɪd]激活函数的缺点
Sigmoid函数饱和使梯度消失。sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。
Sigmoid函数的输出不是零中心的。这个性质并不是我们想要的,因为在神经网络后面层中的神经元得到的数据将不是零中心的。这一情况将影响梯度下降的运作,因为如果输入神经元的数据总是正数,那么梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数。这将会导致梯度下降权重更新时出现z字型的下降。然而,可以看到整个批量的数据的梯度被加起来后,对于权重的最终更新将会有不同的正负,这样就从一定程度上减轻了这个问题。因此,该问题相对于上面的神经元饱和问题来说只是个小麻烦,没有那么严重。
Tanh(双曲正切)函数的缺点:
tanh非线性函数图像如上图右边所示。它将实数值压缩到[-1,1]之间。和sigmoid神经元一样,它也存在饱和问题,但是和sigmoid神经元不同的是,它的输出是零中心的。
Relu(线性整流函数Rectified Linear Unit又称修正线性单元)激活函数,修正指取不小于0的值,相对于sigmoid以及tanh函数的优点以及自身的缺点
优点:相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用( Krizhevsky 等的论文指出有6倍之多)。这是由它的线性,非饱和的公式导致的。采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),这种现象称为饱和,从而无法完成深层网络的训练。而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
缺点:主要是因为x<0时梯度为0导致的。 在x<0 时硬饱和。(即为会一直使得梯度为0,出现梯度消失现象而使得神经元失活,即为无法得到更新从而失去活性)由于 x>0时导数为 1,所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失和梯度爆炸问题。但随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。但是通过合理的设置学习率能够有效的解决这一问题.
Relu激活函数之所以能够得到广泛的应用因为其运算简单,大大的提升了机器的运行效率。由于 x>0时导数为 1,所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失和梯度爆炸问题。且其处理后的数据有更好的稀疏性,将数据转化为只有最大数值,其它都为0.这种变换可以近似程度的最大保留数据特征,用大多数元素为0的稀疏矩阵来实现。至于其会使得部分神经元失活(这正是L1正则化所做的)如果想避免这一现象可以通过设置合理的学习率,同时目前使用最广泛的Adam优化算法,是基于动量的能够自动的调节学习率,从而可以解决这一问题。