KNN做回归和分类的主要区别在于最后做预测时候的决策方式不同。KNN做分类预测时,一般是选择多数表决法,即训练集里和预测的样本特征最近的K个样本,预测为里面有最多类别数的类别。而KNN做回归时,一般是选择平均法,即最近的K个样本的样本输出的平均值作为回归预测值。
KNN的三要素:k值的选取,距离度量的方式和分类决策规则
可以通过交叉验证选择一个合适的k值。对于距离的度量,我们最常用的是欧式距离,即对于两个n维向量x和y,两者的欧式距离定义为:
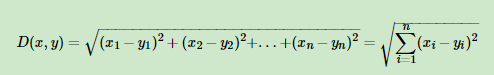
KNN的实现方式:
1)蛮力实现:即为计算预测样本和训练样本中所有点的距离,选择距离最小的前K个元素。利用投票表决法确定预测样本的类别。(或利用均值法确定预测样本的值)
其优点是实现简单,但是其缺点是当数据过大时计算量太大。
2)KD树:具体参考https://www.cnblogs.com/pinard/p/6061661.html
KNN算法的优缺点分析:
优点:
第一、简单好用,容易理解,精度高,理论成熟,既可以用来做分类也可以用来做回归;第二、对异常值不敏感
缺点:
第一、计算复杂性高;空间复杂性高;第二、样本不平衡会造成很大影响。第三、最大的缺点是无法给出数据的内在含义。