“希希敬敬对”百度贴吧小爬虫任务计划:
今天的团队讨论照片:

龙江腾(队长) 201810775001
完成“爬取发帖主题人的主题回复数据”代码review,明天完成代码,实现“把10个页面的数据整合到一个数据组中,并进行排序”的功能。
杨希 201810812008
完成代码,实现“爬取发帖主题人的主题回复数据”功能,明天完成“把10个页面的数据整合到一个数据组中,并进行排序”的代码review。
何敬上 201810812004
完成“爬取发帖主题人的主题回复数据”代码review,明天完成代码,实现“把10个页面的数据整合到一个数据组中,并进行排序”的功能。
遇到的问题:
暂无
燃尽图:

程序代码(基于昨天代码的基础上的更新):
# 找到数据对应的网页,分析网页结构找到数据所在的标签位置
#模拟HTTP请求,向服务器发送这个请求,获取到服务器返回给我们的HTML
import re
from urllib import request
class BDTBCrawler():
url = "http://tieba.baidu.com/f?kw=%E4%B8%9C%E5%8D%8E%E7%90%86%E5%B7%A5%E5%A4%A7%E5%AD%A6&ie=utf-8"
Name_num_list = []
def __init__(self, url):
BDTBCrawler.url = url
#匹配到包含了主题作者和帖子回复数关键字的标签
root_pattern = '<span class="threadlist_rep_num center_text"([sS]*?)data-field='
# 匹配到对应的帖子回复数
num_pattern = 'title="回复">([sS]*?)</span>'
# 匹配到主题作者
name_pattern = 'title="主题作者: ([sS]*?)"'
#模拟HTTP请求,向服务器发送请求,获取到服务器返回给我们的HTML
def __fetch_content(self):
r = request.urlopen(BDTBCrawler.url)
htmls = r.read()
# 将服务器返回的字节码转换成字符串格式
htmls = str(htmls, encoding='utf-8')
return htmls
def __analysis(self, htmls):
#root_html获取包含了主题作者和帖子回复数关键字的标签
root_html = re.findall(BDTBCrawler.root_pattern, htmls)
# 用anchors这个列表来存放提取出来的主题作者和帖子回复数组成的字典
anchors = []
for html in root_html:
# 提取主题作者(列表类型)
name = re.findall(BDTBCrawler.name_pattern, html)
# #提取回复数(列表类型)
number = re.findall(BDTBCrawler.num_pattern, html)
anchor = {'name': name, 'number': number}
anchors.append(anchor)
# print(anchors)
return anchors
def go(self):
#使用for循环爬取前10页
htmls = ''
for i in range(0, 10):
pn = i * 50
#page记录当前爬取页面需要在URL上添加的字符串
page = '&pn=' + str(pn)
BDTBCrawler.url += page
htmls += self.__fetch_content()
anchors = self.__analysis(htmls)
for i in anchors:
print(i)
crawler = BDTBCrawler(BDTBCrawler.url)
crawler.go()
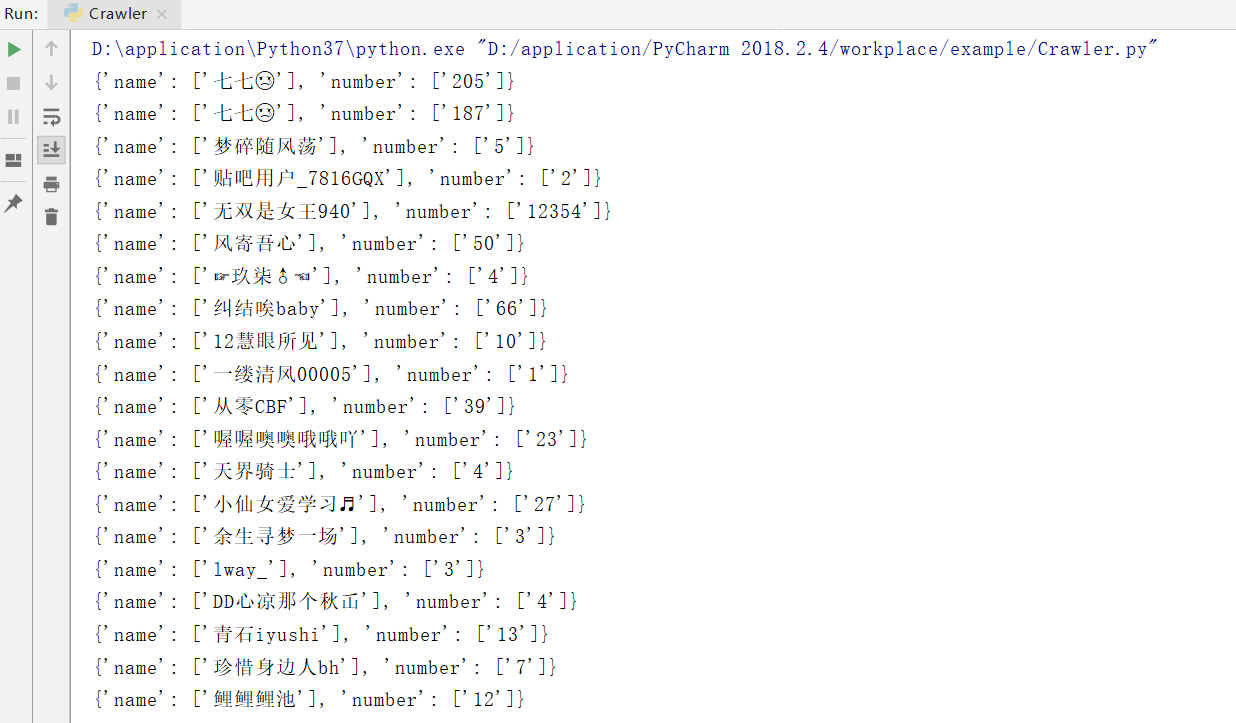
程序运行结果部分截图: