最近百度为了推广自家编写对深度学习框架PaddlePaddle不断推出各种比赛。百度声称PaddlePaddle是一个“易学、易用”的开源深度学习框架,然而网上的资料少之又少。虽然百度很用心地提供了许多文档,而且还是中英双语具备,但是最关键的是报错了很难在网上找到相应的解决办法。为了明年备战百度的比赛,便开始学习以下PaddlePaddle。
1、安装
PaddlePaddle同样支持CUDA加速运算,但是如果没有NVIDIA的显卡,那就还是装CPU版本。
CPU版本安装:pip install paddlepaddle
GPU版本根据所安装的CUDA版本以及cuDNN版本有所不同:
CUDA9 + cuDNN7.0:pip install paddlepaddle-gpu
CUDA8 + cuDNN7.0 : pip install paddlepaddle-gpu==0.14.0.post87
CUDA8 + cuDNN5.0 : pip install paddlepaddle-gpu==0.14.0.post85
2、手写数字识别
其实,Paddle的GitHub提供了这个例程。但是,个人感觉这个例程部分直接调用PaddlePaddle内部类使得读者阅读起来十分困难。特别是数据输入(Feed)中的reader,如果直接看程序,它直接一个函数就完成了图像输入,完全搞不懂它是如何操作。这里也就重点将这里,个人感觉这是和Tensorflow较大的区别。
2.1、网络构建
程序中提供了三种网络模型,代码很明显,这里应该不用太多说,直接贴出来了。需要注意的是,PaddlePaddle将图像的通道数放在最前面,即为[C H W],区别于[H W C]。
(1)、单层全连接层+softmax
#a full-connect-layer network using softmax as activation function def softmax_regression(): img = fluid.layers.data(name='img',shape=[1,28,28],dtype='float32') predict = fluid.layers.fc(input=img,size=10,act='softmax') return predict
(2)、多层全连接层+softmax
#3 full-connect-layers network using softmax as activation function
def multilayer_perceptron(): img = fluid.layers.data(name='img',shape=[1,28,28],dtype='float32') hidden = fluid.layers.fc(input = img,size=128,act='softmax') hidden = fluid.layers.fc(input = hidden,size=64,act='softmax') prediction = fluid.layers.fc(input = hidden,size=10,act='softmax') return prediction
(3)、卷积神经网络
#traditional converlutional neural network
def cnn(): img = fluid.layers.data(name='img',shape=[1, 28, 28], dtype ='float32') # first conv pool conv_pool_1 = fluid.nets.simple_img_conv_pool( input = img, filter_size = 5, num_filters = 20, pool_size=2, pool_stride=2, act="relu") conv_pool_1 = fluid.layers.batch_norm(conv_pool_1) # second conv pool conv_pool_2 = fluid.nets.simple_img_conv_pool( input=conv_pool_1, filter_size=5, num_filters=50, pool_size=2, pool_stride=2, act="relu") # output layer with softmax activation function. size = 10 since there are only 10 possible digits. prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax') return prediction
2.2、构建损失函数
PaddlePaddle的损失函数的构建基本上与tensorflow没有太大的区别。但是需要指出的是:(1)在tensorflow中交叉熵的求解函数是使用[0 0 0 ... 1 ...]等长向量求解。但是在PaddlePaddle中,交叉熵是直接与一个整数求解;(2)标签(lable)的输入数据类型使用的是int64,尽管reader生成器返回的是int类型。笔者尝试将其改为int32类型,但是会出错。另外在其他实践过程中使用int32也是有相应的错误。
def train_program(): #if using dtype='int64', it reports errors! label = fluid.layers.data(name='label', shape=[1], dtype='int64') # Here we can build the prediction network in different ways. Please predict = cnn() #predict = softmax_regression() #predict = multilayer_perssion() # Calculate the cost from the prediction and label. cost = fluid.layers.cross_entropy(input=predict, label=label) avg_cost = fluid.layers.mean(cost) acc = fluid.layers.accuracy(input=predict, label=label) return [avg_cost, acc]
PaddlePaddle使用Trainer进行训练,只需构建训练函数train_program作为Trainer参数(这个下面个再详细讲解)。这里要说一下,函数返回一个向量[arg_cost, acc],其中第一个元素作为损失函数,而后面几个元素则是可选的,用于在迭代过程中print出来。所以,返回arg_cost是必要的,其他是可选的。特别说明:不要作死将一个常量放在里面,也就是里面的元素必须是会随着训练而变化,如果作死“acc=1”,则在训练中会报错。
2.3、训练
PaddlePaddle使用fulid.Trainer来创建训练器。这里则需要配备好训练器的train_program(损失函数)、place(是否使用GPU)以及optimizer_program(优化器)。然后调用train函数来进行训练。详细可见下面程序:
def optimizer_program(): return fluid.optimizer.Adam(learning_rate=0.001) if __name__ == "__main__": print("run minst train ") minst_prefix = '/home/dzqiu/DataSet/minst/' train_image_path = minst_prefix + 'train-images-idx3-ubyte.gz' train_label_path = minst_prefix + 'train-labels-idx1-ubyte.gz' test_image_path = minst_prefix + 't10k-images-idx3-ubyte.gz' test_label_path = minst_prefix + 't10k-labels-idx1-ubyte.gz' #reader_creator在将在下面讲述 train_reader = paddle.batch(paddle.reader.shuffle(#shuffle用于打乱buffer的循序 reader_creator(train_image_path,train_label_path,buffer_size=100), buf_size=500), batch_size=64) test_reader = paddle.batch(
reader_creator(test_image_path,test_label_path,buffer_size=100), batch_size=64) #测试集就不用打乱了 #if use GPU, use 'export FLAGS_fraction_of_gpu_memory_to_use=0' at first use_cuda = True place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() trainer = fluid.Trainer(train_func=train_program,
place=place,
optimizer_func=optimizer_program) params_dirname = "recognize_digits_network.inference.model" lists = [] # def event_handler(event): if isinstance(event,fluid.EndStepEvent):#每步触发事件 if event.step % 100 == 0: print("Pass %d, Epoch %d, Cost %f, Acc %f" %(event.step, event.epoch, event.metrics[0],#train_program返回的第一个参数arg_cost event.metrics[1]))#train_program返回的第二个参数acc if isinstance(event,fluid.EndEpochEvent):#每次迭代触发事件 trainer.save_params(params_dirname) #使用test的时候,返回值就是train_program的返回,所以赋值需要对应 avg_cost, acc = trainer.test(reader=test_reader,
feed_order=['img','label']) print("Test with Epoch %d, avg_cost: %s, acc: %s" %(event.epoch, avg_cost, acc)) lists.append((event.epoch, avg_cost, acc)) # Train the model now trainer.train(num_epochs=5,event_handler=event_handler,
reader=train_reader,feed_order=['img', 'label']) # find the best pass best = sorted(lists, key=lambda list: float(list[1]))[0] print 'Best pass is %s, testing Avgcost is %s' % (best[0], best[1]) print 'The classification accuracy is %.2f%%' % (float(best[2]) * 100)
2.4、训练数据的读取 Reader
PaddlePaddle的训练数据读取仅用一个paddle.dataset.mnist.train()解决,封装起来难以理解其操作,更不能看出如何读取自己的训练集。这里,我将这个段函数从源码中挖出来简化为reader_creator,实现对minst数据集的读取,首先让我们看看minst数据集的格式:
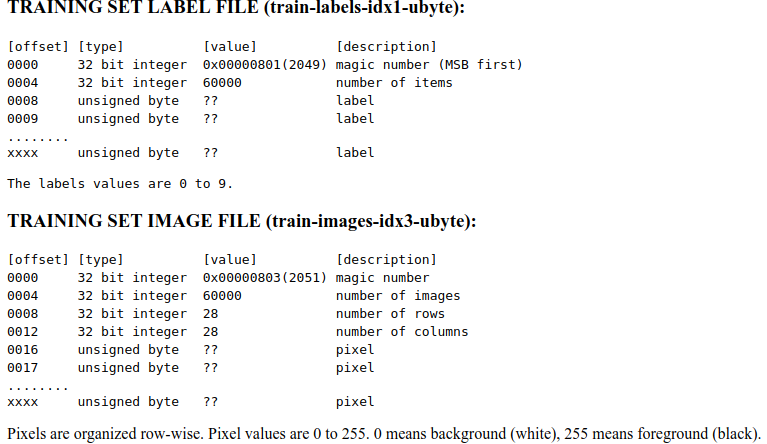
训练集中,标签集前8个字节是magic和数目,后面每个字节代表数字0-9的标签;图像集中前16字节是一些数据集信息,包括magic、图像数目、行数和列数,后面每个字节代表每个像素点,也就是说我们连续取出28*28个字节安顺序就可以组成28*28的图片。弄清楚文件如何读取,那么就可以编写reader:
def reader_creator(image_filename,label_filename,buffer_size): def reader(): #调用命令读取文件,Linux下使用zcat if platform.system()=='Linux': zcat_cmd = 'zcat' elif paltform.system()=='Windows': zcat_cmd = 'gzcat' else: raise NotImplementedError("This program is suported on Windows or Linux, but your platform is" + platform.system()) #create a subprocess to read the images sub_img = subprocess.Popen([zcat_cmd, image_filename], stdout = subprocess.PIPE) sub_img.stdout.read(16) #skip some magic bytes 这里我们已经知道,所以我们不在需要前16字节 #create a subprocess to read the labels sub_lab = subprocess.Popen([zcat_cmd, label_filename], stdout = subprocess.PIPE) sub_lab.stdout.read(8) #skip some magic bytes 同理 try: while True: #前面使用try,故若再读取过程中遇到结束则会退出 #label is a pixel repersented by a unsigned byte,so just read a byte labels = numpy.fromfile( sub_lab.stdout,'ubyte',count=buffer_size).astype("int") if labels.size != buffer_size: break #read 28*28 byte as array,and then resize it images = numpy.fromfile( sub_img.stdout,'ubyte',
count=buffer_size * 28 * 28)
.reshape(buffer_size, 28, 28).astype("float32") #mapping each pixel into (-1,1) images = images / 255.0 * 2.0 - 1.0; for i in xrange(buffer_size): yield images[i,:],int(labels[i]) #将图像与标签抛出,循序与feed_order对应! finally: try: #terminate the reader subprocess sub_img.terminate() except: pass try: #terminate the reader subprocess sub_lable.terminate() except: pass return reader
2.5、运行结果
训练集中有60000张图片,buffer_size为100,batch_size为64,所以应该Pass了900多次。


Pass 0, Batch 0, Cost 4.250958, Acc 0.062500 Pass 100, Batch 0, Cost 0.249865, Acc 0.953125 Pass 200, Batch 0, Cost 0.281933, Acc 0.906250 Pass 300, Batch 0, Cost 0.147851, Acc 0.953125 Pass 400, Batch 0, Cost 0.144059, Acc 0.968750 Pass 500, Batch 0, Cost 0.082035, Acc 0.953125 Pass 600, Batch 0, Cost 0.105593, Acc 0.984375 Pass 700, Batch 0, Cost 0.148170, Acc 0.968750 Pass 800, Batch 0, Cost 0.182150, Acc 0.937500 Pass 900, Batch 0, Cost 0.066323, Acc 0.968750 Test with Epoch 0, avg_cost: 0.07329441363440427, acc: 0.9762620192307693 Pass 0, Batch 1, Cost 0.157396, Acc 0.953125 Pass 100, Batch 1, Cost 0.050120, Acc 0.968750 Pass 200, Batch 1, Cost 0.086324, Acc 0.984375 Pass 300, Batch 1, Cost 0.002137, Acc 1.000000 Pass 400, Batch 1, Cost 0.173876, Acc 0.984375 Pass 500, Batch 1, Cost 0.059772, Acc 0.968750 Pass 600, Batch 1, Cost 0.035788, Acc 0.984375 Pass 700, Batch 1, Cost 0.008351, Acc 1.000000 Pass 800, Batch 1, Cost 0.022678, Acc 0.984375 Pass 900, Batch 1, Cost 0.021835, Acc 1.000000 Test with Epoch 1, avg_cost: 0.06836433922317389, acc: 0.9774639423076923 Pass 0, Batch 2, Cost 0.214221, Acc 0.937500 Pass 100, Batch 2, Cost 0.212448, Acc 0.953125 Pass 200, Batch 2, Cost 0.007266, Acc 1.000000 Pass 300, Batch 2, Cost 0.015241, Acc 1.000000 Pass 400, Batch 2, Cost 0.061948, Acc 0.984375 Pass 500, Batch 2, Cost 0.043950, Acc 0.984375 Pass 600, Batch 2, Cost 0.018946, Acc 0.984375 Pass 700, Batch 2, Cost 0.015527, Acc 0.984375 Pass 800, Batch 2, Cost 0.035185, Acc 0.984375 Pass 900, Batch 2, Cost 0.004890, Acc 1.000000 Test with Epoch 2, avg_cost: 0.05774364945361809, acc: 0.9822716346153846 Pass 0, Batch 3, Cost 0.031849, Acc 0.984375 Pass 100, Batch 3, Cost 0.059525, Acc 0.953125 Pass 200, Batch 3, Cost 0.022106, Acc 0.984375 Pass 300, Batch 3, Cost 0.006763, Acc 1.000000 Pass 400, Batch 3, Cost 0.056089, Acc 0.984375 Pass 500, Batch 3, Cost 0.018876, Acc 1.000000 Pass 600, Batch 3, Cost 0.010325, Acc 1.000000 Pass 700, Batch 3, Cost 0.010989, Acc 1.000000 Pass 800, Batch 3, Cost 0.026476, Acc 0.984375 Pass 900, Batch 3, Cost 0.007792, Acc 1.000000 Test with Epoch 3, avg_cost: 0.05476908334449968, acc: 0.9830729166666666 Pass 0, Batch 4, Cost 0.061547, Acc 0.984375 Pass 100, Batch 4, Cost 0.002315, Acc 1.000000 Pass 200, Batch 4, Cost 0.009715, Acc 1.000000 Pass 300, Batch 4, Cost 0.024202, Acc 0.984375 Pass 400, Batch 4, Cost 0.150663, Acc 0.968750 Pass 500, Batch 4, Cost 0.082586, Acc 0.984375 Pass 600, Batch 4, Cost 0.012232, Acc 1.000000 Pass 700, Batch 4, Cost 0.055258, Acc 0.984375 Pass 800, Batch 4, Cost 0.016068, Acc 1.000000 Pass 900, Batch 4, Cost 0.004945, Acc 1.000000 Test with Epoch 4, avg_cost: 0.041706092633705505, acc: 0.9865785256410257 Best pass is 4, testing Avgcost is 0.041706092633705505 The classification accuracy is 98.66%
2.6 测试接口
PaddlePaddle提供接口函数,调用接口即可。特别的是,图像需要转化为[N C H W]的张量,如果是一张图像,这里N当然是1,因为是灰度图C也便是1。具体看下面代码:
def load_image(file): im = Image.open(file).convert('L') im = im.resize((28, 28), Image.ANTIALIAS) im = numpy.array(im).reshape(1, 1, 28, 28).astype(np.float32) #[N C H W] 这里多了一个N im = im / 255.0 * 2.0 - 1.0 return im cur_dir = os.path.dirname(os.path.realpath(__file__)) img = load_image(cur_dir + '/infer_3.png') inferencer = fluid.Inferencer( # infer_func=softmax_regression, # uncomment for softmax regression # infer_func=multilayer_perceptron, # uncomment for MLP infer_func=cnn, # uncomment for LeNet5 param_path=params_dirname, place=place) results = inferencer.infer({'img': img}) lab = numpy.argsort(results) # probs and lab are the results of one batch data print "Label of infer_3.png is: %d" % lab[0][0][-1]
测试结果如下:
Label of infer_3.png is: 3
3、结语
PaddlePaddle与tensorflow还是有一定的区别,而且除了错误很难搜到解决方法,笔者会另外开一篇博客整理总结PaddlePaddle遇到的各种问题,这个对于例程的讲解也将会继续下去,坚持每周三更新,快开学了,还加把劲。
源码地址:Github