概述
本文主要介绍scrapy架构图、组建、工作流程,以及结合selenium boss直聘爬虫案例分析
架构图
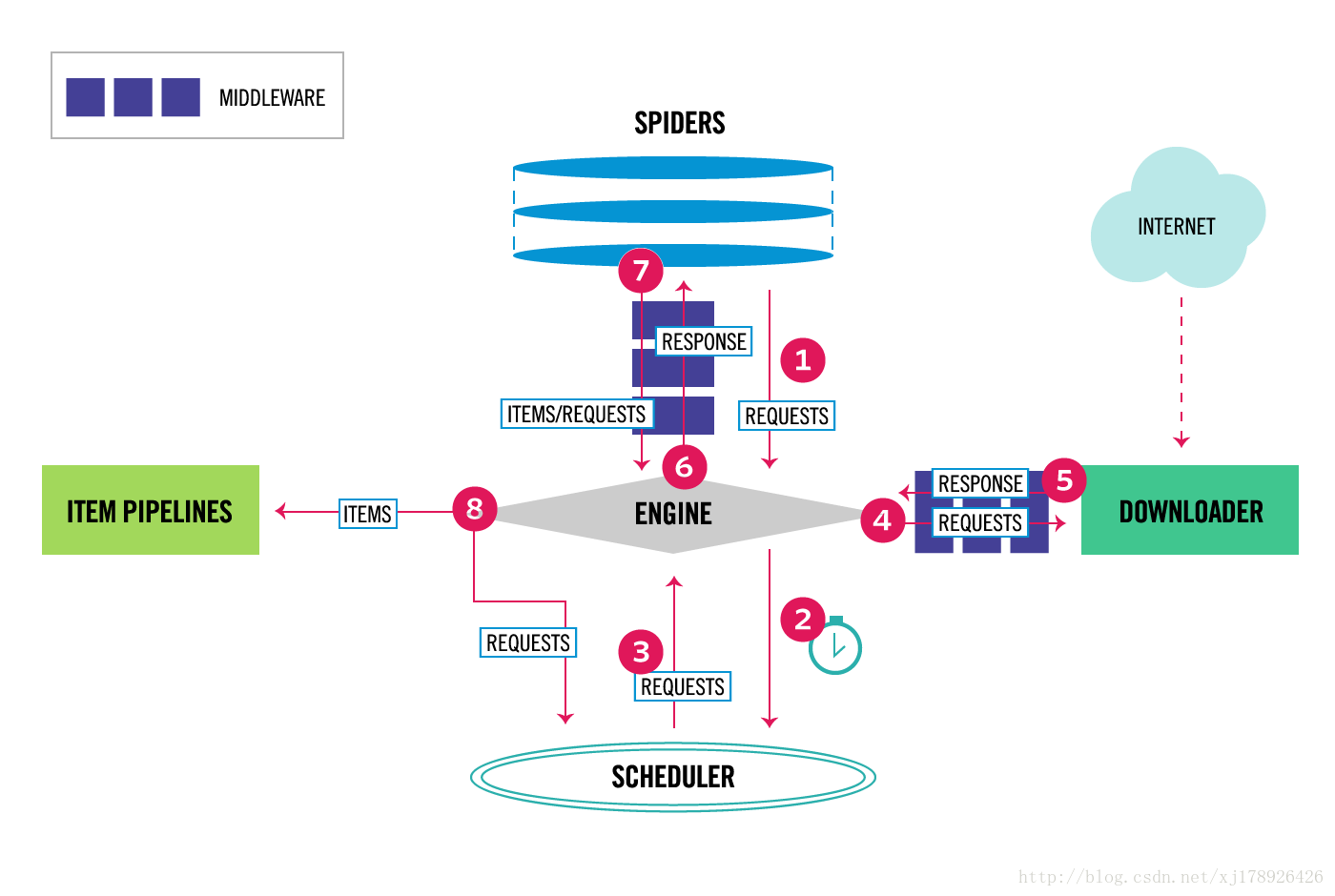
组件
Scrapy 引擎(Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件.
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎.
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider.
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类. 每个spider负责处理一个特定(或一些)网站,我们前面几篇文章中,通过Scrapy框架实现的爬虫例子都是在Spiders这个组件中实现. 更多内容请看 Spiders .
下载器中间件(Downloader Middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response. 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能.更多内容请看 Downloader Middleware .
Spider中间件(Spider Middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests). 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能
管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item.典型的处理有清理、 验证及持久化(例如存取到数据库中). 更多内容查看 Item Pipeline .
工作流程
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎从Spiders中获取到最初的要爬取的请求(Requests).
- 引擎安排请求(Requests)到调度器中,并向调度器请求下一个要爬取的请求(Requests).
- 调度器返回下一个要爬取的请求(Requests)给引擎.
- 引擎将上步中得到的请求(Requests)通过下载器中间件(Downloader Middlewares)发送给下载器(Downloader ),这个过程中下载器中间件(Downloader Middlewares)中的process_request()函数会被调用到.
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(Downloader Middlewares)发送给引擎,这个过程中下载器中间件(Downloader Middlewares)中的process_response()函数会被调用到.
- 引擎从下载器中得到上步中的Response并通过Spider中间件(Spider Middlewares)发送给Spider处理,这个过程中Spider中间件(Spider Middlewares)中的process_spider_input()函数会被调用到.
- Spider处理Response并通过Spider中间件(Spider Middlewares)返回爬取到的Item及(跟进的)新的Request给引擎,这个过程中Spider中间件(Spider Middlewares)的process_spider_output()函数会被调用到.
- 引擎将上步中Spider处理的其爬取到的Item给Item 管道(Pipeline),将Spider处理的Request发送给调度器,并向调度器请求可能存在的下一个要爬取的请求(Requests).
- (从第二步)重复直到调度器中没有更多的请求(Requests).
案例分析:BOSS直聘
- 定义Item
# -*- coding: utf-8 -*-
import scrapy
# 继承Item: items.py
class Boss(scrapy.Item):
"""
定义需要爬取的字段及类型
"""
position = scrapy.Field(serializer=str) # 招聘职位
salary = scrapy.Field(serializer=str) # 薪资
addr = scrapy.Field(serializer=str) # 工作地址
years = scrapy.Field(serializer=str) # 工作年限
education = scrapy.Field(serializer=str) # 学历
company = scrapy.Field(serializer=str) # 招聘公司
industry = scrapy.Field(serializer=str) # 行业
nature = scrapy.Field(serializer=str) # 性质:是否上市
scale = scrapy.Field(serializer=str) # 规模:人数
publisher = scrapy.Field(serializer=str) # 招牌者
publisherPosition = scrapy.Field(serializer=str) # 招聘者岗位
publishDateDesc = scrapy.Field(serializer=str) # 发布时间
- 定义scrapy爬虫: myspider.py
# -*- coding: utf-8 -*-
import scrapy
from spider.items import Boss
class BossSpider(scrapy.Spider):
name = "boss"
# 设定域名
allowed_domains = ["www.zhipin.com"]
def start_requests(self):
"""
设置第一个爬取的URL,即boss直聘第一页
"""
urls = [
'https://www.zhipin.com/c101210100/h_101210100/?page=1&ka=page-1',
]
# 每次yield都会调用下载器中间件,即 mySpiderMiddleware.SeleniumMiddleware
# 这里由selenium进行动态抓取招聘信息
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
"""
初始化Item:Boss
:param response:
:return:
"""
boss = Boss()
# 利用xpath筛选想要爬取的数据
for box in response.xpath('//div[@class="job-primary"]'):
boss['position'] = box.xpath('.//div[@class="job-title"]/text()').extract()[0]
boss['salary'] = box.xpath('.//span[@class="red"]/text()').extract()[0]
boss['addr'] = box.xpath('.//p[1]/text()').extract()[0]
boss['years'] = box.xpath('.//p[1]/text()').extract()[1]
boss['education'] = box.xpath('.//p[1]/text()').extract()[2]
boss['company'] = box.xpath('.//div[@class="info-company"]//a/text()').extract()[0]
boss['industry'] = box.xpath('.//p[1]//text()').extract()[3]
boss['nature'] = box.xpath('.//p[1]//text()').extract()[4]
boss['scale'] = box.xpath('.//p[1]//text()').extract()[5]
boss['publisher'] = box.xpath('.//div[@class="info-publis"]//h3/text()').extract()[0]
boss['publisherPosition'] = box.xpath('.//div[@class="info-publis"]//h3/text()').extract()[1]
boss['publishDateDesc'] = box.xpath('.//div[@class="info-publis"]//p/text()').extract()[0]
# 将Item:Boss传递给Spider中间件,由它进行数据清洗(去空,去重)等操作
# 每次yield都将调用SpiderMiddleware, 这里是 mySpiderMiddleware.MyFirstSpiderMiddleware
yield boss
# 分页
url = response.xpath('//div[@class="page"]//a[@class="next"]/@href').extract()
if url:
page = 'https://www.zhipin.com' + url[0]
yield scrapy.Request(page, callback=self.parse)
- 定义下载器中间件(DownloadMiddleware): myDownloadMiddleware.py
# -*- coding: utf-8 -*-
from scrapy.http import HtmlResponse
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
class SeleniumMiddleware(object):
"""
下载器中间件
"""
@classmethod
def process_request(cls, request, spider):
if spider.name == 'boss':
if request.url == 'https://www.zhipin.com/c101210100/h_101210100/?page=1&ka=page-1':
options = Options()
options.add_argument('-headless')
# geckodriver需要手动下载
driver = Firefox(executable_path='/ddhome/bin/geckodriver', firefox_options=options)
driver.get(request.url)
searchText = driver.find_element_by_xpath('//div[@class="search-form-con"]//input[1]')
searchText.send_keys(unicode("大数据研发工程师"))
searchBtn = driver.find_element_by_xpath('//div[@class="search-form "]//button[@class="btn btn-search"]')
searchBtn.click()
html = driver.page_source
driver.quit()
# 构建response, 将它发送给spider引擎
return HtmlResponse(url=request.url, body=html, request=request, encoding='utf-8')
- 定义Spider中间件(SpiderMiddleware): mySpiderMiddleware.py
# -*- coding: utf-8 -*-
import logging
logger = logging.getLogger(__name__)
class MyFirstSpiderMiddleware(object):
@staticmethod
def process_start_requests(start_requests, spider):
"""
第一次发送请求前调用,之后不再调用
:param start_requests:
:param spider:
:return:
"""
logging.debug("#### 2222222 start_requests %s , spider %s ####" % (start_requests, spider))
last_request = []
for one_request in start_requests:
logging.debug("#### one_request %s , spider %s ####" % (one_request, spider))
last_request.append(one_request)
logging.debug("#### last_request %s ####" % last_request)
return last_request
@staticmethod
def process_spider_input(response, spider):
logging.debug("#### 33333 response %s , spider %s ####" % (response, spider))
return
@staticmethod
def process_spider_output(response, result, spider):
logging.debug("#### 44444 response %s , result %s , spider %s ####" % (response, result, spider))
return result
- 定义管道(Pipeline): pipelines.py
# -*- coding: utf-8 -*-
import json
import codecs
from scrapy.contrib.exporter import CsvItemExporter
from scrapy import signals
import os
class CSVPipeline(object):
"""
导出CSV格式
"""
def __init__(self):
self.file = {}
self.csvpath = os.path.dirname(__file__) + '/spiders/output'
self.exporter = None
@classmethod
def from_crawler(cls, crawler):
pipeline = cls()
crawler.signals.connect(pipeline.spider_opened, signals.spider_opened)
crawler.signals.connect(pipeline.spider_closed, signals.spider_closed)
return pipeline
def spider_opened(self, spider):
"""
当蜘蛛启动时自动执行
:param spider:
:return:
"""
f = open('%s/%s_items.csv' % (self.csvpath, spider.name), 'a') # r只读, w可写, a追加
self.file[spider] = f
self.exporter = CsvItemExporter(f)
self.exporter.fields_to_export = spider.settings['FIELDS_TO_EXPORT']
self.exporter.start_exporting()
def process_item(self, item, spider):
"""
蜘蛛每yield一个item,这个方法执行一次
:param item:
:param spider:
:return:
"""
self.exporter.export_item(item)
return item
def spider_closed(self, spider):
self.exporter.finish_exporting()
f = self.file.pop(spider)
f.close()
class JSONPipeline(object):
"""
导出JSON格式
"""
def __init__(self):
self.file = None
self.csvpath = os.path.dirname(__file__) + '/spiders/output'
def process_item(self, item, spider):
self.file = codecs.open('%s/%s_items.json' % (self.csvpath, spider.name), 'a', encoding='utf-8')
line = json.dumps(dict(item), ensure_ascii=False) + '
'
self.file.write(line)
# return item
def spider_closed(self, spider):
self.file.close()
- settings.py配置
BOT_NAME = 'spider'
SPIDER_MODULES = ['spider.spiders']
NEWSPIDER_MODULE = 'spider.spiders'
FEED_EXPORT_ENCODING = 'utf-8'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'spider.middlewares.mySpiderMiddleware.MyFirstSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'spider.middlewares.myDownloadMiddleware.SeleniumMiddleware': 542,
'spider.middlewares.myDownloadMiddleware.PhantomJSMiddleware': 543, # 键为中间件类的路径,值为中间件的顺序
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, # 禁止内置的中间件
}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'spider.pipelines.CSVPipeline': 300,
'spider.pipelines.JSONPipeline': 301
}
FEED_EXPORTERS = {
'csv': 'spider.spiders.csv_item_exporter.MyProjectCsvItemExporter',
}
CSV_DELIMITER = ','
FIELDS_TO_EXPORT = [
'position',
'salary',
'addr',
'years',
'education',
'company',
'industry',
'nature',
'scale',
'publisher',
'publisherPosition',
'publishDateDesc'
]