1、俩种表复制语句
SELECT INTO和INSERT INTO SELECT两种表复制语句 CT: create table <new table> as select * from <exists table> 要求目标表不存在,因为在插入时会自动创建表,并将查询表中指定字段数据复制到新建的表中 IS: insert into table2 (f1,f2,..) select v1,v2.... from table1 要求目标表table2必须存在,由于目标表table2已经存在,所以我们除了插入源表 table1的字段外,还可以插入常量

2、merge into 用法
MERGE INTO用法:
merge into表A
using与表A产生关联字段值
on进行和表A关联
when matched then
update set...
when not matched then
insert ...) values


create table PRODUCTS(PRODUCT_ID INTEGER, REQ_NO VARCHAR(32), PRODUCT_NAME VARCHAR2(60), CATEGORY VARCHAR2(60)); insert into PRODUCTS values (1501, '001', 'vIVITAR 35Mм', 'ELECTRNCS'); insert into PRODUCTS values (1502, '002', 'oLYMPUS I85o', 'ELECTRNCS'); insert into PRODUCTS values (1600, '003', 'PIAY GYм', 'тoYS'); insert into PRODUCTS values (1601, '003', 'LAMAZE', 'moYs'); insert into PRODUCTS values (1717, '001', 'HARRY POTTER', 'DVD'); insert into PRODUCTS values (1666, '002', 'HARRY POTTER', 'DVD'); commit; --drop table PRODUCTS; select * from PRODUCTS; merge into PRODUCTS a using (select 1717 product_id, '001' req_no from dual) b on (a.product_id = b.product_id and a.req_no = b.req_no) when matched then update set product_name = '进行更新啦' , category = '新的category' when not matched then insert (product_id ,req_no , product_name , category) values(1717, '002' , '新产品' , 'CCA'); commit;
3、递归函数
select * from emp
--where empno = 79391 or
start with empno = 7369 or empno = 7934
connect by prior mgr = empno
order by sal desc;
--PID在前面ID在后 (向上查询) --ID在前PI在后(向下查询)

4、分析函数
over函数 over partition by组合 over partition by order by组合 row_number函数 rollup函数 cube函数 grouping函数

over是分组函数
order by 是按什么连续求和
partition by 按什么分区

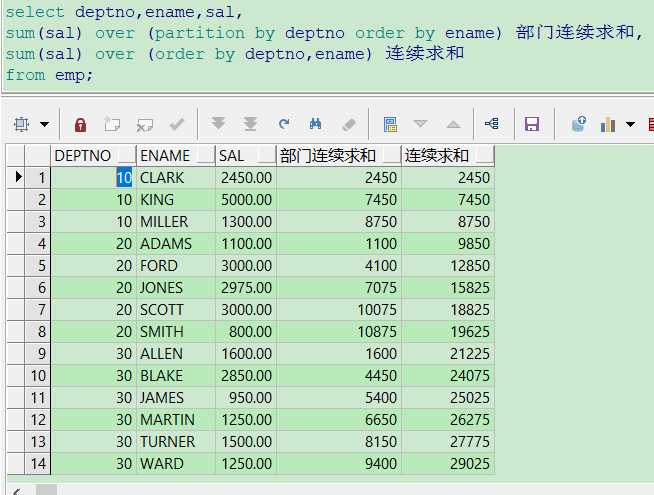
select deptno,ename, sal, sum(sal) over (order by deptno) 连续求和, sum(sal) over() 总和, 100*round(sal/sum(sal) over (),5) 份额 from emp;
select deptno,ename,sal, sum(sal) over (partition by deptno order by ename) 部门连续求和, sum(sal) over (partition by deptno) 部门总和, 100*round(sal/sum(sal) over (partition by deptno),4) "部门份额(%)", sum(sal) over (order by deptno,ename) 连续求和, sum(sal) over() 总和, 100*round(sal/sum(sal) over (),4) "份额(%)" from emp;
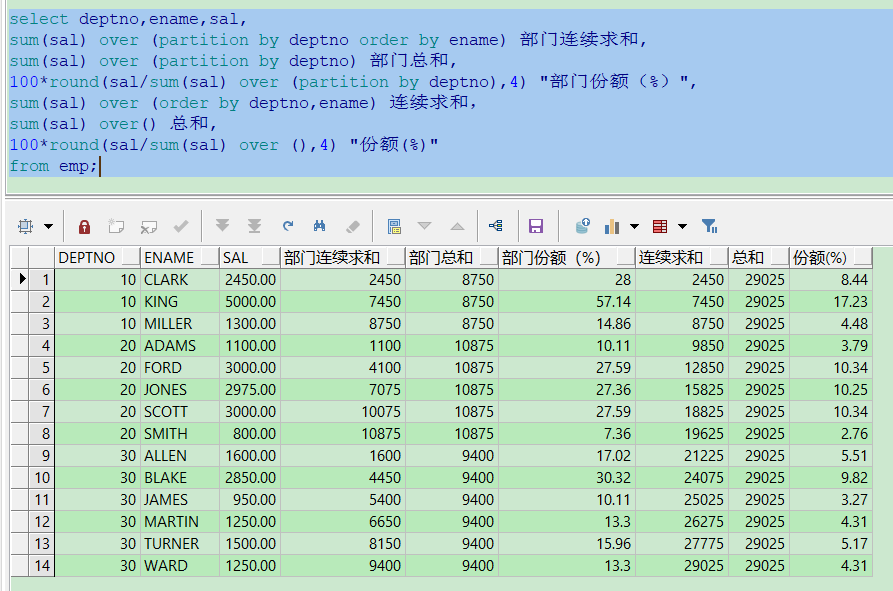
求和规则有按部门分区的,有不分区的例子

5、row_number()分组排名

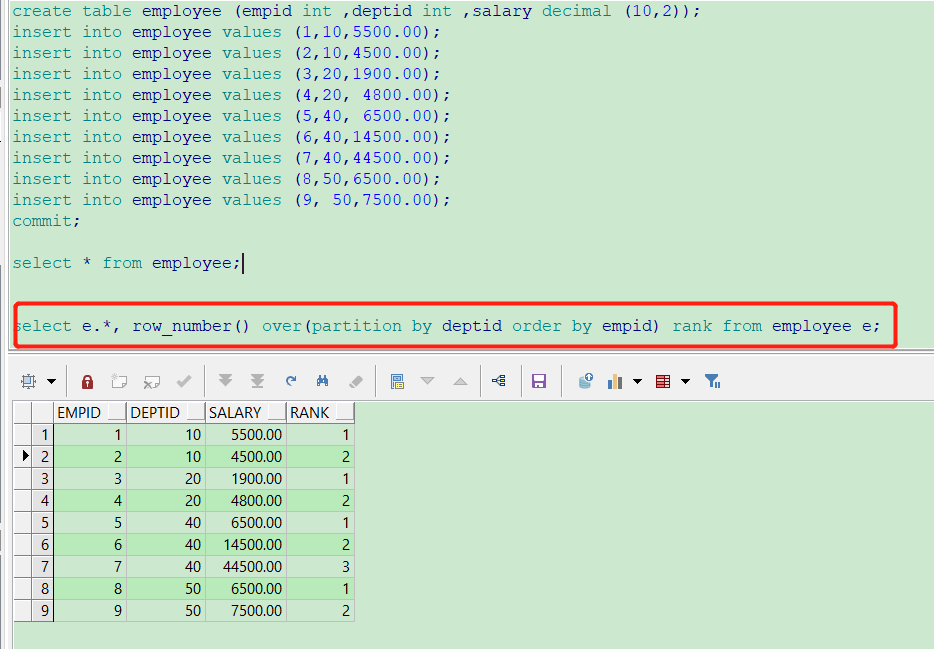
create table employee (empid int ,deptid int ,salary decimal (10,2)); insert into employee values (1,10,5500.00); insert into employee values (2,10,4500.00); insert into employee values (3,20,1900.00); insert into employee values (4,20, 4800.00); insert into employee values (5,40, 6500.00); insert into employee values (6,40,14500.00); insert into employee values (7,40,44500.00); insert into employee values (8,50,6500.00); insert into employee values (9, 50,7500.00); commit; select * from employee; select e.*, row_number() over(partition by deptid order by empid) rank from employee e;
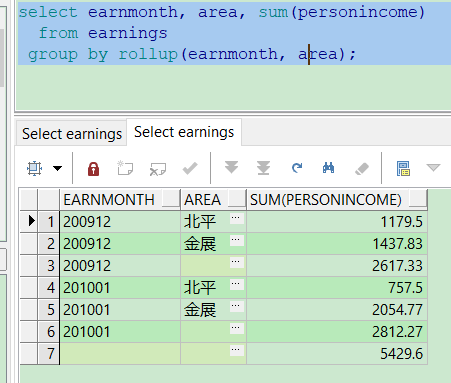
6、rollup()
在group by 分组上在加上对earnmonth的汇总统计


create table earnings--打工赚线表
(earnmonth varchar2 (6), --打工月份
area varchar2 (20),--打工地区
sno varchar2 (10),--打工者續号
sname varchar2 (20), --打工者姓名
times int,--本月打工次数
singieincome number (10,2), --、每次漠多少钱
personincome number (10,2) --当月总收入
);
-- truncate table earnings;
insert into earnings values ('200912','北平','511601','大',11,30,11*30);
insert into earnings values ('200912','北平','511602','大',8,25,8*25);
insert into earnings values ('200912','北平','511603','小素',30,6.25,30*6.25);
insert into earnings values ('200912','北平','511604','大亮',16,8.25,16*8.25);
insert into earnings values ('200912','北平','511605','搜藏',30,11,30*11);
insert into earnings values ('200912','金展','511301','小玉',15,12.25,15*12.25);
insert into earnings values ('200912','金展','511302','小凡',27,16.67,27*16.67);
insert into earnings values ('200912','金展','511303','小妮',7,39.33,7*99.33);
insert into earnings values ('200912','金展','511304','小角',0,18,0);
insert into earnings values ('200912','金展','511305','儿',11,9.88,11*9.88);
insert into earnings values ('201001','北平','511601','大鬼',0,30,0);
insert into earnings values ('201001','北平','511602','大肌',14,25,14*25);
insert into earnings values ('201001','北平','511603','小',19,6.25,19*6.25);
insert into earnings values ('201001','北平','511604','大亮',7,8.25,7*8.25);
insert into earnings values ('201001','北平','511605','硬載',21,11,21*11);
insert into earnings values ('201001','金展','511301','小玉',6,12,25.6*12.25) ;
insert into earnings values ('201001','金展','511302','小凡',17,16.67,17*16.67);
insert into earnings values ('201001','金展','511303','小班',27,33.33,27*39.3);
insert into earnings values ('201001','金展','511304','小角',16,18,16*18);
insert into earnings values ('201001','金展','511305','儿',11,9.8,11*9.88);
commit;
select earnmonth, area, sum(personincome)
from earnings
group by earnmonth, area ;
select earnmonth, area, sum(personincome)
from earnings
group by rollup(earnmonth, area);
7、cube()分组

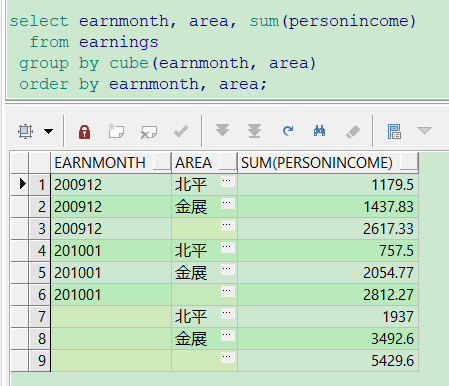
select earnmonth, area, sum(personincome) from earnings group by cube(earnmonth, area) order by earnmonth, area;
8、grouping()
别名


select earnmonth,
(case
when ((grouping(area) = 1) and (grouping(earnmonth) = 0)) then
'月份小计'
when ((grouping(area) = 1) and (grouping(earnmonth) = 1)) then
'总计'
else
area
end) as area,
sum(personincome)
from earnings
group by rollup(earnmonth, area);
9、排名 rank() dense_rank() row_number()
rank() 相同的值排名相同,但是下一位排名需要算上前面的,跳跃式排名

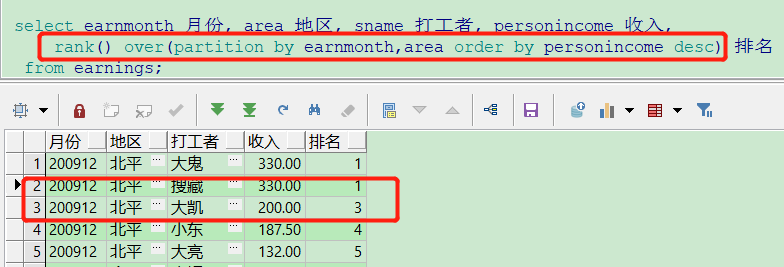
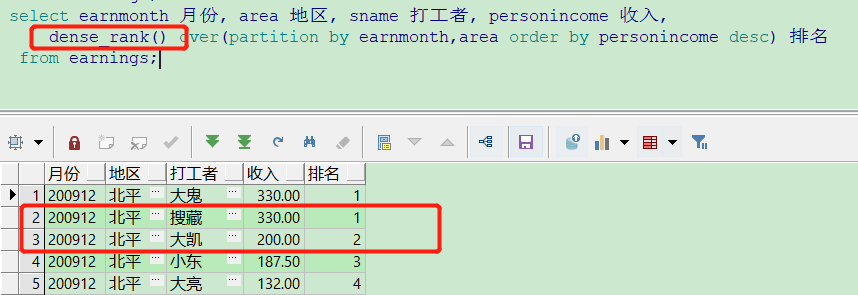
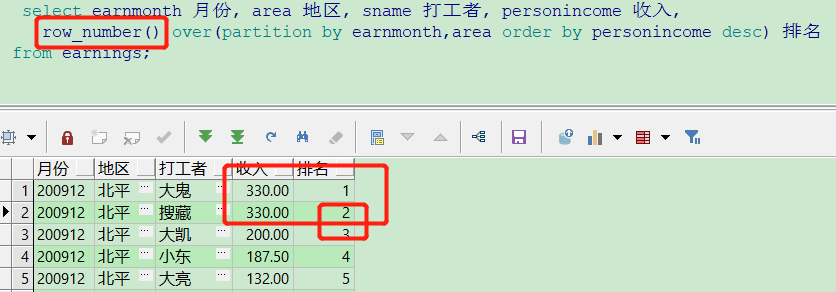
elect earnmonth 月份, area 地区, sname 打工者, personincome 收入, rank() over(partition by earnmonth,area order by personincome desc) 排名 from earnings; select earnmonth 月份, area 地区, sname 打工者, personincome 收入, dense_rank() over(partition by earnmonth,area order by personincome desc) 排名 from earnings; select earnmonth 月份, area 地区, sname 打工者, personincome 收入, row_number() over(partition by earnmonth,area order by personincome desc) 排名 from earnings;
10、sum()
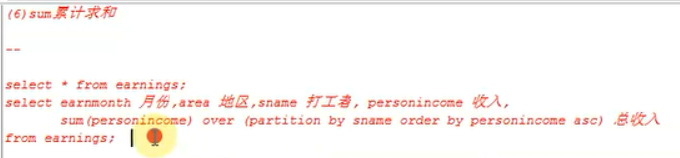
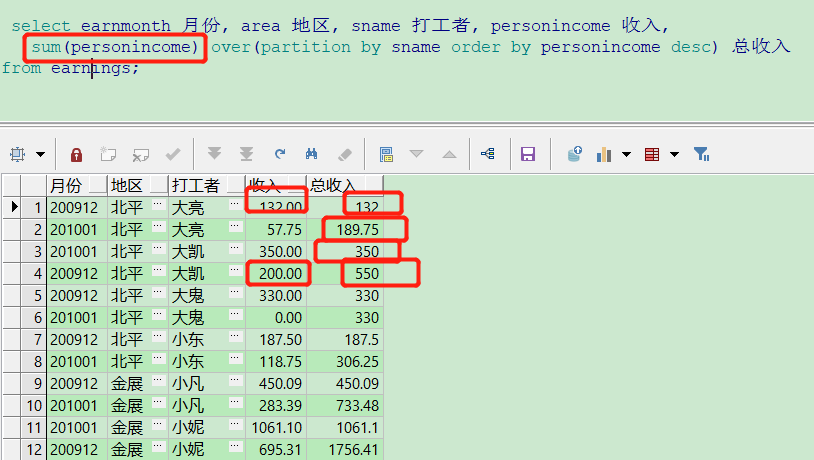
select earnmonth 月份, area 地区, sname 打工者, personincome 收入, sum(personincome) over(partition by sname order by personincome desc) 总收入 from earnings;
11、多行函数参与分组


select distinct earnmonth 月份, area 地区, max(personincome) over(partition by earnmonth, area) 最高值, min(personincome) over(partition by earnmonth, area) 最低值, avg(personincome) over(partition by earnmonth, area) 平均值, sum(personincome) over(partition by earnmonth, area) 总收入 from earnings;