转载自 http://download.csdn.net/source/858994
源地址下是 Word 文档,这里转换成HTML 格式
Lucene 源码剖析
3.3 每个Segment包含的文件
剩下的文件(remaining files)都是per-segment(每个片断文件),因此(thus)都用后缀来定义(defined by suffix)。
3.3.1 Fields域数据文件
3.3.1.1 Field信息(.fnm)
Field的名字都存储在Field信息文件中,后缀是.fnm。
|
文件 |
包含的项 |
数目 |
类型 |
版本 |
描述 |
|
FieldsInfo(.fnm) |
FieldsCount |
1 |
VInt |
|
|
|
FieldName |
FieldsCount |
String |
|
|
|
|
FieldBits |
FieldsCount |
Byte |
|
最低阶的bit位(low-order bit)值为1表示是被索引的Fields,0表示非索引的Fields。 |
|
|
|
第二个最低阶的bit位(second lowest-order bit)值为1表示该Field有term向量存储(term vectors stored),0表示该field没有term向量。 |
||||
|
>=1.9 |
如果第三个最低阶的bit位(third lowest-order bit)设置(0×04),term的位置(term positions)将和term向量一起被存储(stored with term vectors)。 |
||||
|
>=1.9 |
如果第四个最低阶的bit位(fourth lowest-order bit)设置(0×08),term的偏移(term offsets)将和term向量一起被存储(stored with term vectors)。 |
||||
|
>=1.9 |
如果第五个最低阶的bit位(fifth lowest-order bit)设置(0×10),norms将对索引的field忽略掉(norms are omitted for the indexed field)。 |
||||
|
>=1.9 |
如果第六个最低阶的bit位(sixth lowest-order bit)设置(0×20),payloads将为索引的field存储(payloads are stored for the indexed field)。 |
注明:payloads概念:
词条载荷(payloads)――允许用户将任意二进制数据和索引中的任意词条(term)相关联。
词条载荷是一个允许信息在索引中按逐词条储存的新特性。例如,当索引Web页面时,储存某个关键词的额外信息可能会很有用,例如这个关键词关联的URL或者经过文字分析后得出的权重系数。在更高级的应用中,为了突出语句中的名次成分相对于其它成分的重要性,储存语句中这个关键词出现的部分可能会很有帮助。我今年在ApacheCon Europe会议上的演讲中就有几张讲述词条载荷的幻灯片,感兴趣的读者可以去看看。
Fields将使用它们在这个文件中的顺序来编号(fields are numbered by their order in this file)。需要注意的是,就像文档编号(document numbers)一样,field编号(field numbers)与片断是相关的(are segment relative)。结构如下图所示:

3.3.1.2 存储的Field(.fdx和.fdt)
存储的fields(stored fields)通过两个文件来呈现(represented by two files),即field索引文件(.fdx)和field数据文件(.fdt)。
|
文件 |
包含的项 |
父项 |
数目 |
类型 |
版本 |
描述 |
|
Fields Index(.fdx) 对每个文档来说,存储指向它的fields数据的指针(pointer) |
FieldValuesPosition |
|
SegSize |
UInt64 |
|
用于找详细文档(a particular document)的所有fields的field数据文件中的位置(position),因为它包含的(contains)是固定长度的数据(fixed-length data),这个文件可以很容易地进行随机访问(randomly accessed)。 |
|
|
文档n的field数据的位置是在该文件中n*8的位置中(UInt64类型)。 |
|||||
|
Fields Data(.fdt)这个文件存储每个文档的field数据 |
DocFieldData |
|
SegSize |
|
|
|
|
FieldCount |
DocFieldData |
1 |
VInt |
|
|
|
|
FieldNum |
DocFieldData |
FieldCount |
VInt |
|
|
|
|
Bits |
DocFieldData |
FieldCount |
Byte |
<=1.4 |
只有最低阶的bit位(low-order bits of Bits)被使用,值为1表示tokenized field(分解过的field),0表示non-tokenized field。 |
|
|
Byte |
>=1.9 |
最低阶的bit位表示tokenized field |
||||
|
>=1.9 |
第二个bit(second bit)用于表示该field存储binary数据。 |
|||||
|
>=1.9 |
第三个bit(third bit)表示该field的压缩选项被开启(field with compression enabled),如果压缩选项开启,采用的压缩算法(algorithm)是ZLIB |
|||||
|
Value |
DocFieldData |
FieldCount |
String |
<=1.4 |
|
|
|
String | BinaryValue |
>=1.9 |
依赖于Bits的值 |
||||
|
BinaryValue |
>=1.9 |
ValueSize,<Byte>^ValueSize |
||||
|
ValueSize |
Value |
1 |
VInt |
>=1.9 |
|
结构如下图所示:

3.3.2 存储的term字典(.tii和.tis)
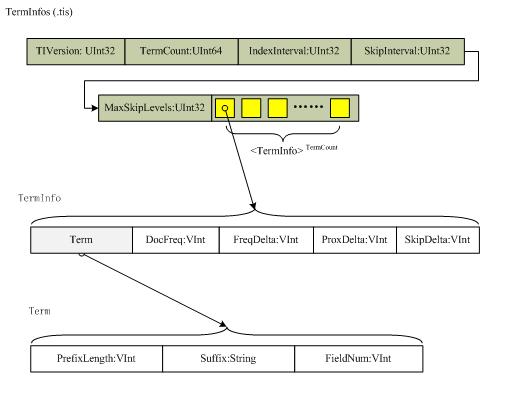
Term字典使用如下两种文件存储,第一种是存储term信息(TermInfoFile)的文件,即.tis文件,格式如下:
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
全部版本 |
TIVersion |
1 |
UInt32 |
记录该文件的版本,1.4版本中为-2 |
|
TermCount |
1 |
UInt64 |
|
|
|
IndexInterval |
1 |
UInt32 |
|
|
|
SkipInterval |
1 |
UInt32 |
|
|
|
MaxSkipLevels |
1 |
UInt32 |
|
|
|
TermInfos |
1 |
TermInfo… |
|
|
|
TermInfos->TermInfo |
TermCount |
TermInfo |
|
|
|
TermInfo->Term |
TermCount |
Term |
|
|
|
Term->PrefixLength |
TermCount |
VInt |
Term文本的前缀可以共享,该项的值表示根据前一个term的文本来初始化的字符串前缀长度,前一个term必须已经预设成后缀文本以便构成该term的文本。比如,如果前一个term为“bone”,而当前term为“boy”,则该PrefixLength值为2,suffix值为“y” |
|
|
Term->Suffix |
TermCount |
String |
如上 |
|
|
Term->FieldNum |
TermCount |
VInt |
用来确定term的field,它们存储在.fdt文件中。 |
|
|
TermInfo->DocFreq |
TermCount |
VInt |
包含该term的文档数目 |
|
|
TermInfo->FreqDelta |
TermCount |
VInt |
用来确定包含在.frq文件中该term的TermFreqs的位置。特别指出,它是该term的数据在文件中位置与前一个term的位置的差值,当为第一个term时,该值为0 |
|
|
TermInfo->ProxDelta |
TermCount |
VInt |
用来确定包含在.prx文件中该term的TermPositions的位置。特别指出,它是该term的数据在文件中的位置与前一个term的位置地差值,当为第一个term时,该值为0。如果fields的omitTF设置为true,该值也为0,因为prox信息没有被存储。 |
|
|
TermInfo->SkipDelta |
TermCount |
VInt |
用来确定包含在.frq文件中该term的SkipData的位置。特别指出,它是TermFreqs之后即SkipData开始的字节数目,换句话说,它是TermFreq的长度。SkipDelta只有在DocFreq不比SkipInteval小的情况下才会存储。 |
TermInfoFile文件按照Term来排序,排序方法首先按照Term的field名称(按照UTF-16字符编码)排序,然后按照Term的Text字符串(UTF-16编码)排序。 结构如下图所示:
另一种是存储term信息的索引文件,即.tii文件,该文件包含.tis文件中每一个IndexInterval的值,与它在.tis中的位置一起被存储,这被设计来完全地读进内存中(read entirely into memory),以便用来提供随机访问.tis文件。该文件的结构与.tis文件非常相似,只是添加了一项数据,即IndexDelta。格式如下
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
全部版本 |
TIVersion |
1 |
UInt32 |
同tis |
|
IndexTermCount |
1 |
UInt64 |
同tis |
|
|
IndexInterval |
1 |
UInt32 |
同tis |
|
|
SkipInterval |
1 |
UInt32 |
是TermDocs存储在skip表中的分数(fraction),用来加速(accelerable)TermDocs.skipTo(int)的调用。在更小的索引中获得更大的结果值(larger values result),将获得更高的速度,但却更小开销?(fewer accelerable cases while smaller values result in bigger indexes, less acceleration (in case of a small value for MaxSkipLevels) |
|
|
MaxSkipLevels |
1 |
UInt32 |
是.frq文件中为每一个term存储的skip levels的最大数目,A low value results in smaller indexes but less acceleration, a larger value results in slighly larger indexes but greater acceleration.参见.frq文件格式中关于skip levels的详细介绍。 |
|
|
TermIndices |
IndexTermCount |
TermIndice |
同tis |
|
|
TermIndice->TermInfo |
IndexTermCount |
TermInfo |
同tis |
|
|
TermIndice->IndexDelta |
IndexTermCount |
VLong |
用来确定该Term的TermInfo在.tis文件中的位置,特别指出,它是该term的数据的位置与前一个term位置的差值。 |
结构如下图所示:
