SGD:现在的SGD一般都指mini-batch gradient descent 最小批量梯度下降
缺点:(正因为有这些缺点才让这么多大神发展出了后续的各种算法)
- 选择合适的learning rate比较困难 - 对所有的参数更新使用同样的learning rate。对于稀疏数据或者特征,有时我们可能想更新快一些对于不经常出现的特征,对于常出现的特征更新慢一些,这时候SGD就不太能满足要求了
- SGD容易收敛到局部最优,并且在某些情况下可能被困在鞍点
Adagrad:
对学习率进行了一个约束。
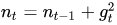
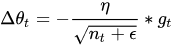
此处,对从1到
进行一个递推形成一个约束项regularizer,
,
用来保证分母非0
特点:
- 前期
较小的时候, regularizer较大,能够放大梯度
- 后期
- 适合处理稀疏梯度
Adadelta:
Adadelta
Adadelta是对Adagrad的扩展,最初方案依然是对学习率进行自适应约束,但是进行了计算上的简化。 Adagrad会累加之前所有的梯度平方,而Adadelta只累加固定大小的项,并且也不直接存储这些项,仅仅是近似计算对应的平均值。即:
在此处Adadelta其实还是依赖于全局学习率的,但是作者做了一定处理,经过近似牛顿迭代法之后:
其中,代表求期望。
此时,可以看出Adadelta已经不用依赖于全局学习率了。
特点:
- 训练初中期,加速效果不错,很快
- 训练后期,反复在局部最小值附近抖动
RSMprop:
RMSprop可以算作Adadelta的一个特例:
当时,
就变为了求梯度平方和的平均数。
如果再求根的话,就变成了RMS(均方根):
此时,这个RMS就可以作为学习率的一个约束:
特点:
- 其实RMSprop依然依赖于全局学习率
- RMSprop算是Adagrad的一种发展,和Adadelta的变体,效果趋于二者之间
- 适合处理非平稳目标 - 对于RNN效果很好
参考资料:
https://zhuanlan.zhihu.com/p/22252270