思考:
数组由于内存地址连续,是一种查询快增删慢的数据结构;
链表由于内存地址不连续,是一种查询慢增删快的数据结构;
那么怎么实现查询又快,增删也快的数据结构呢?
要是把数组和链表结合起来会怎么样?
如下图所示这就是散列表的数据结构图,它由数组和链表构成,拥有数组和链表的优点。
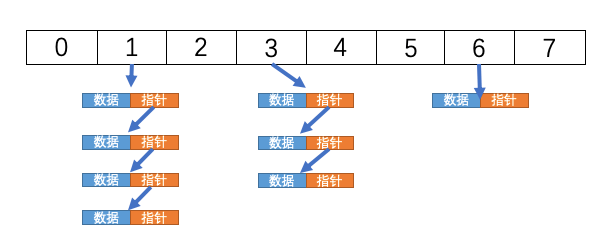
那么散列表是怎么实现数据的快速查找和增删的呢?
举个例子 现在你要查找1-50之间的数45,你需要依次遍历每个元素直到找到45为止;
0->1->2->3->4->5->6->7->8->9->10->11->12->13->14->15->16->17->18->19->20->21->22->23->24->25->26->27->28->29->30->31->32->33->34->35->36->37->38->39->40->41->42->43->44->45
现在有一种新的存储方式,在查找之前你需要先计算一次,再通过计算得到的值去查找,比如说先把要查找的数除以5得到余数,通过余数去查找:
0->5->10->15->20->25->30->35->40->45
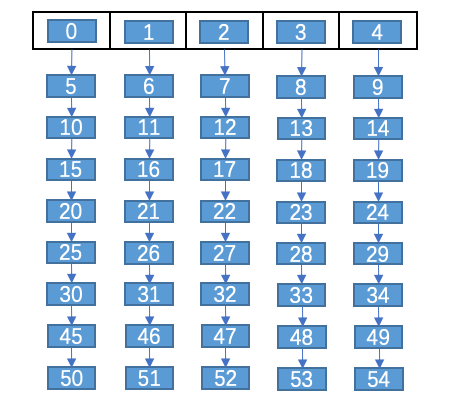
通过对比是不是查找快很多了呢,而且由于是链式储存的增删过程也要快很多。
这时再回顾这个过程,先通过计算得到查询的起点,再在起点依次查询,这个计算实际上就是一次hash运算也叫做Hash函数,在实际应用中函数函数要比上面的取模运算复杂得多,但是原理是一样的。
散列表又叫做哈希表(HashTable),是根据关键码值(即键值对)而直接访问的数据结构。也就是说,它通过把关键码映射到表中一个位置来访问记录,以加快查找速度。
暂时写到这里!