HTTP请求协议与响应协议
请求方式: get与post请求
GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的请求体中.
GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制。
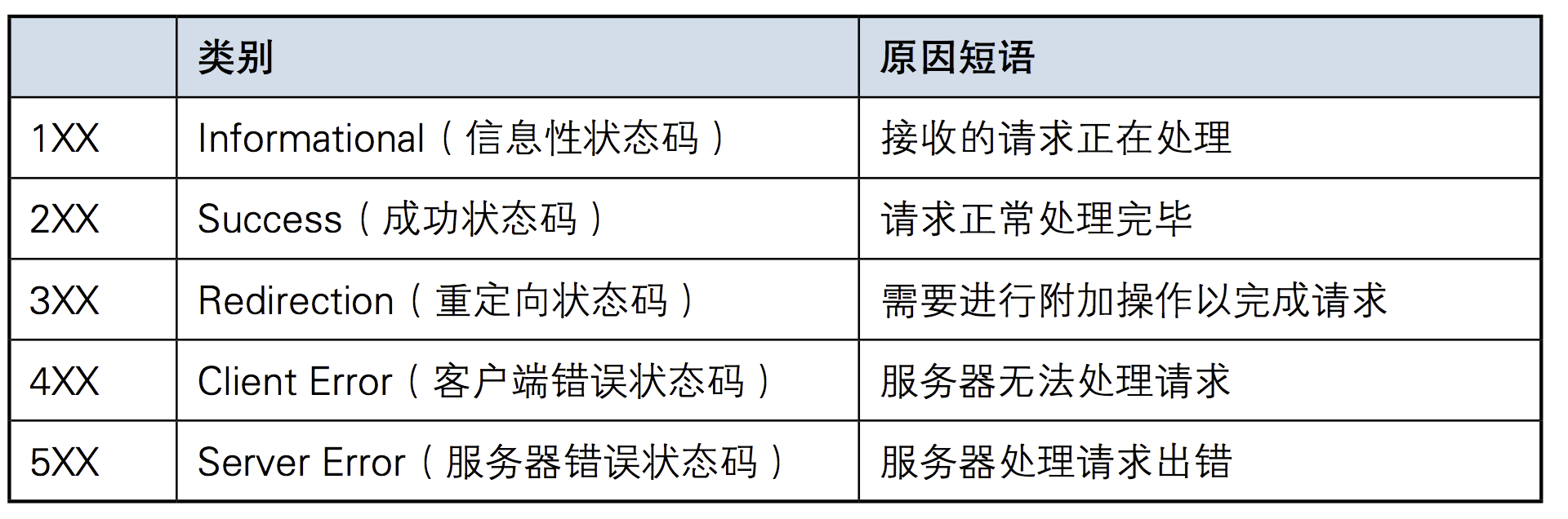
响应码
DIY一个web框架
web框架包含 urls views templates 等等
1、urls.py
from django.contrib import admin from django.urls import path,re_path from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('query/', views.query), path('book_list/', views.book_list, name="book_list"), # 查 path('add_book/', views.add_book, name="add_book"), # 增 re_path(r'^edit_book/(?P<book_id>d+)/$', views.edit_book, name="edit_book"), # 改 re_path(r'^del_book/(d+)/$', views.del_book, name="del_book"), # 删 ]
2、views.py
def book_list(request): books = models.Book.objects.all() return render(request, "book_list2.html", {"books": books}) def add_book(request): if request.method == "GET": publish_list = models.Publish.objects.all() authors_list = models.Author.objects.all() return render(request, "add_book2.html", {'publish_list':publish_list, "authors_list":authors_list}) else: # 方式一 title = request.POST.get('title') price = request.POST.get('price') pub_date = request.POST.get('pub_date') publish_id = request.POST.get('publish_id') author_list = request.POST.getlist('author_list') book = models.Book.objects.create(title=title, price=price, pub_date=pub_date,publish_id=publish_id) print(title, price, pub_date, publish_id, author_list) book.authors.add(*author_list) return redirect("/book_list/") def edit_book(request, book_id): pass def del_book(reqeust, bid): pass
3、templates模板目录
# book_list.html # add_book.html
Django简介
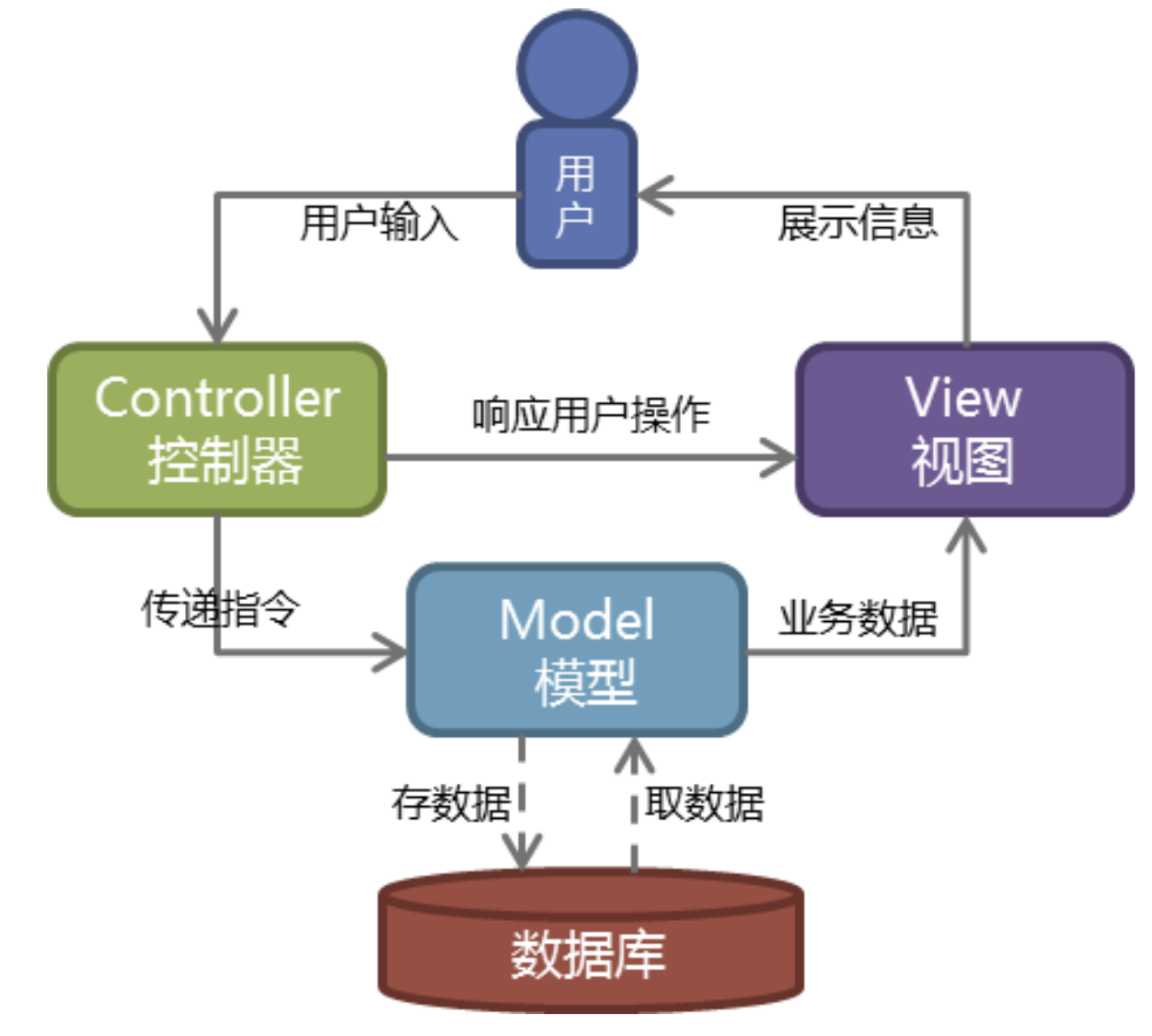
MVC模型 ---- WEB
MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,
模型负责业务对象与数据库的映射(ORM),
视图负责与用户的交互(页面),
控制器接受用户的输入调用模型和视图完成用户的请求,其示意图如下所示:
MTV模型----Django
- M 代表模型(Model): 负责业务对象和数据库的关系映射(ORM)。
- T 代表模板 (Template):负责如何把页面展示给用户(html)。
- V 代表视图(View): 负责业务逻辑,并在适当时候调用Model和Template。
除了以上三层之外,还需要一个URL分发器,它的作用是将一个个URL的页面请求分发给不同的View处理,View再调用相应的Model和Template,MTV的响应模式如下所示:
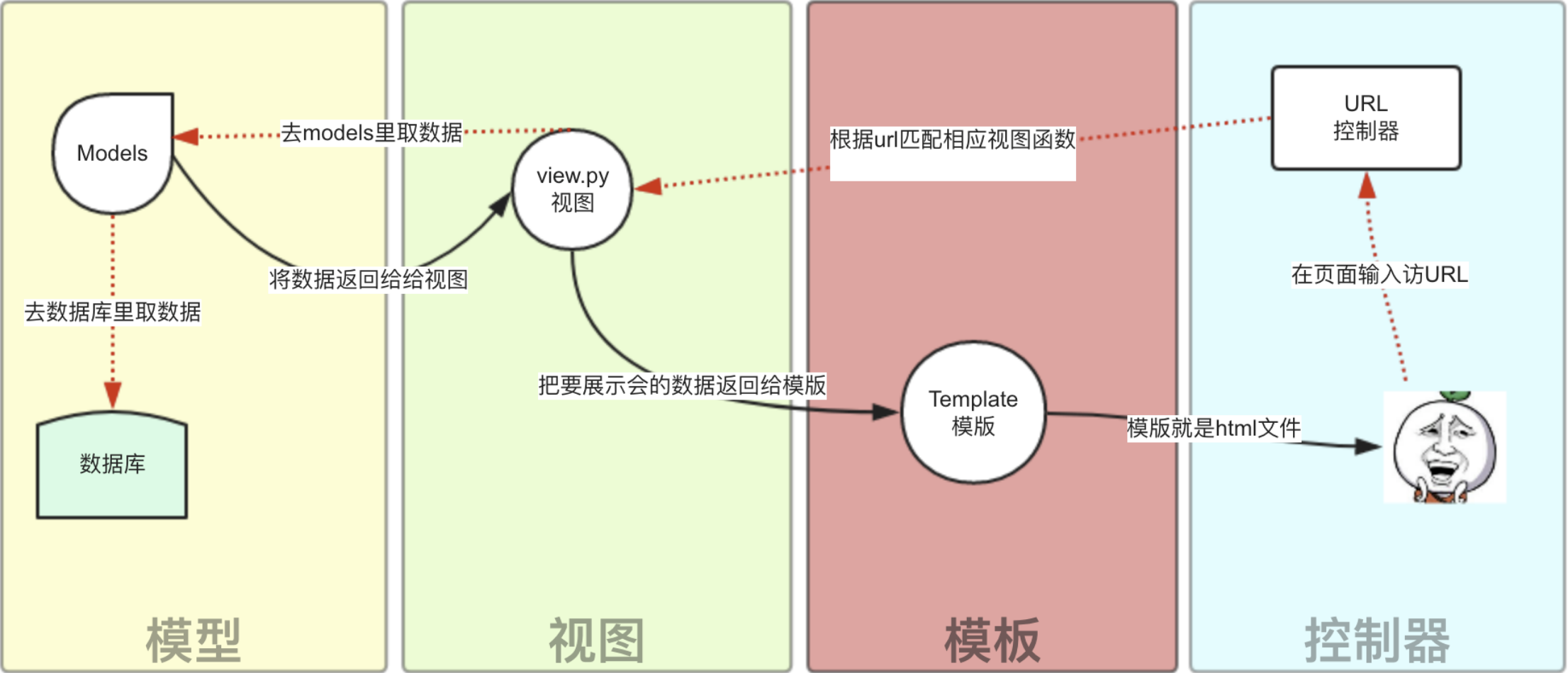
一般是用户通过浏览器向我们的服务器发起一个请求(request),这个请求回去访问视图函数,(如果不涉及到数据调用,那么这个时候视图函数返回一个模板也就是一个网页给用户),视图函数调用模型,模型去数据库查找数据,然后逐级返回,视图函数把返回的数据填充到模板中空格中,最后返回网页给用户。
Django安装下载 略。。。
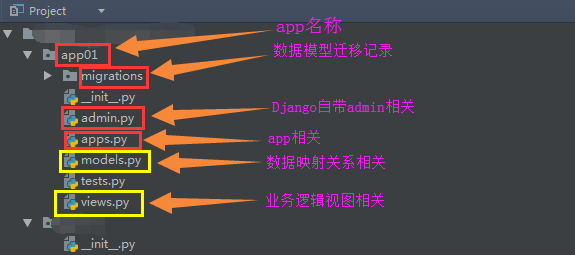
认识app目录结构
启动运行Django项目:
python manage.py runserver # 127.0.0.1:8000 python manage.py runserver 80 # 127.0.0.1:80 python manage.py runserver 0.0.0.0:8888 # 0.0.0.0:8888 # 注意:要在manage.py同级目录执行命令
路由层 url
urlpatterns = [ url(r'^admin/$', admin.site.urls), url(r'^articles/2003/$', views.special_case_2003), url(r'^articles/([0-9]{4})/$', views.year_archive), url(r'^articles/([0-9]{4})/([0-9]{2})/$', views.month_archive), url(r'^articles/([0-9]{4})/([0-9]{2})/([0-9]+)/$', views.article_detail), ]
注意:
若要从URL 中捕获一个值,只需要在它周围放置一对圆括号。
不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是^articles 而不是 ^/articles。
每个正则表达式前面的'r' 是可选的但是建议加上。它告诉Python 这个字符串是“原始的” —— 字符串中任何字符都不应该转义
2、有名分组
在Python 正则表达式中,命名正则表达式组的语法是(?P<name>pattern),其中name 是组的名称,pattern 是要匹配的模式
4、反向解析
目的:不把路径写死,便于修改
在模板中:使用url 模板标签。
在Python 代码中:使用from django.urls import reverse()函数
urls.py
urlpatterns = [ path('admin/', admin.site.urls), path('login/', views.login, name="Login"), # name命名 ]
login.html
<form action="{% url 'Login' %}" method="post"> # 用命名的名称 <p>用户名:<input type="text" name="user"></p> <p>密码:<input type="password" name="pwd"></p> <input type="submit"> </form>
views.py
from django.shortcuts import render, HttpResponse, redirect from django.urls import reverse def login(request): if request.method == "POST": username = request.POST.get("user") #从页面获取数据 pwd = request.POST.get("pwd") # 从没页面获取数据 if username == "alex" and pwd == "123": return redirect(reverse("Index")) # 如果账号密码正确,则返回主页,反向解析 return render(request, "login.html") #账号密码不正确,则返回登录页面
5、名称空间
由于name没有作用域,Django在反解URL时,会在项目全局顺序搜索,当查找到第一个name指定URL时,立即返回。
project的urls.py
urlpatterns = [ re_path(r'^admin/', admin.site.urls), re_path(r'^app01/', include(("app01.urls", "app01"))), re_path(r'^app02/', include(("app02.urls", "app02"))), ]
app01.urls
urlpatterns = [ re_path(r'^index/', index,name="index"), ]
app02.urls
urlpatterns = [ re_path(r'^index/', index,name="index"), ]
app01.views
from django.core.urlresolvers import reverse def index(request): return HttpResponse(reverse("app01:index"))
app02.views
from django.core.urlresolvers import reverse def index(request): return HttpResponse(reverse("app02:index"))
在模板中也是同理
<form action="{% url 'app01:Login' %}" method="post"> <p>用户名:<input type="text" name="user"></p> <p>密码:<input type="password" name="pwd"></p> <input type="submit"> </form>
HttpRequest对象
1.HttpRequest.GET 一个类似于字典的对象,包含 HTTP GET 的所有参数。详情请参考 QueryDict 对象。 2.HttpRequest.POST 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成 QueryDict 对象。 POST 请求可以带有空的 POST 字典 —— 如果通过 HTTP POST 方法发送一个表单,但是表单中没有任何的数据,QueryDict 对象依然会被创建。 因此,不应该使用 if request.POST 来检查使用的是否是POST 方法;应该使用 if request.method == "POST" 另外:如果使用 POST 上传文件的话,文件信息将包含在 FILES 属性中。 注意:键值对的值是多个的时候,比如checkbox类型的input标签,select标签,需要用: request.POST.getlist("hobby") 3.HttpRequest.body 一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,例如:二进制图片、XML,Json等。 但是,如果要处理表单数据的时候,推荐还是使用 HttpRequest.POST 。 4.HttpRequest.path 一个字符串,表示请求的路径组件(不含域名)。 例如:"/music/bands/the_beatles/" 5.HttpRequest.method 一个字符串,表示请求使用的HTTP 方法。必须使用大写。 例如:"GET"、"POST" 1.HttpRequest.get_full_path() 返回 path,如果可以将加上查询字符串。 例如:"/music/bands/the_beatles/?print=true" 2.HttpRequest.is_ajax() 如果请求是通过XMLHttpRequest 发起的,则返回True,方法是检查 HTTP_X_REQUESTED_WITH 相应的首部是否是字符串'XMLHttpRequest'。 大部分现代的 JavaScript 库都会发送这个头部。如果你编写自己的 XMLHttpRequest 调用(在浏览器端),你必须手工设置这个值来让 is_ajax() 可以工作。 如果一个响应需要根据请求是否是通过AJAX 发起的,并且你正在使用某种形式的缓存例如Django 的 cache middleware, 你应该使用 vary_on_headers('HTTP_X_REQUESTED_WITH') 装饰你的视图以让响应能够正确地缓存。 */
HttpResponse对象
响应对象主要有三种形式(响应三剑客):
HttpResponse()
render()
redirect()
render方法:
render(request, template_name[, context])
结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
request: 用于生成响应的请求对象。
template_name:要使用的模板的完整名称,可选的参数
context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
render方法就是将一个模板页面中的模板语法进行渲染,最终渲染成一个html页面作为响应体。
redirect方法
传递要重定向的一个硬编码的URL
def my_view(request): ... return redirect('/some/url/') # 也可以是一个完整的URL def my_view(request): ... return redirect('http://example.com/')


1)301和302的区别。 301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,这个地址可以从响应的Location首部中获取 (用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。 他们的不同在于。301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址; 302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,搜索引擎会抓取新的内容而保存旧的网址。 SEO302好于301 2)重定向原因: (1)网站调整(如改变网页目录结构); (2)网页被移到一个新地址; (3)网页扩展名改变(如应用需要把.php改成.Html或.shtml)。 这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的 网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。 关于301与302
三、模板层
1、模板语法之变量
{{ var_name }}
views.py:
def index(request): import datetime s="hello" l=[111,222,333] # 列表 dic={"name":"yuan","age":18} # 字典 date = datetime.date(1993, 5, 2) # 日期对象 class Person(object): def __init__(self,name): self.name=name person_yuan=Person("yuan") # 自定义类对象 person_egon=Person("egon") person_alex=Person("alex") person_list=[person_yuan,person_egon,person_alex] return render(request,"index.html",{"l":l,"dic":dic,"date":date,"person_list":person_list})
template:
<h4>{{ s }}</h4> # return render 中没有返回 s, 所以拿不到s的值
<h4>列表:{{ l.0 }}</h4> # l.0 根据列表l的索引取值
<h4>列表:{{ 111122 }}</h4> # 输出数字
<h4>字符串:{{ ‘你好’ }}</h4> # 输出字符串
<h4>字典:{{ dic.name }}</h4> # 输出字典键name的值
<h4>日期:{{ date.year }}</h4> #
<h4>类对象列表:{{ person_list.0.name }}</h4> # person列表,索引为0的对象的name值
<h4>字典:{{ dic.name.upper }}</h4> # 这个也是可用的
2、模板语法之过滤器
length ,返回值长度 {{ value|length }} {{ list|length }}
date
{{ value|date:"Y-m-d"}}
safe
Django的模板中会对HTML标签和JS等语法标签进行自动转义,原因显而易见,
这样是为了安全。但是有的时候我们可能不希望这些HTML元素被转义,
比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,
这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,
如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,
如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。比如:
value="<a href="">点击</a>" {{ value|safe }} # 不转义
3、模板之标签
for标签
# 遍历每一个元素
{% for person in person_list %} <p>{{ person.name }}</p> {% endfor %}
可以利用{% for obj in list reversed %}反向完成循环
# 遍历一个字典 {% for key,val in dic.items %} <p>{{ key }}:{{ val }}</p> {% endfor %}
注:循环序号可以通过{{ forloop }}显示
forloop.counter The current iteration of the loop (1-indexed) forloop.counter0 The current iteration of the loop (0-indexed) forloop.revcounter The number of iterations from the end of the loop (1-indexed) forloop.revcounter0 The number of iterations from the end of the loop (0-indexed) forloop.first True if this is the first time through the loop forloop.last True if this is the last time through the loop
for ... empty
for 标签带有一个可选的{% empty %} 从句,以便在给出的组是空的或者没有被找到时,可以有所操作。 {% for person in person_list %} <p>{{ person.name }}</p> # 不需要用python中的print {% empty %} # 类似 for....else中的else <p>sorry,no person here</p> {% endfor %}
if 标签
num = 60 # num可以在这里定义,也可以通过后端传值
{% if num > 100 or num < 0 %} <p>无效</p> {% elif num > 80 and num < 100 %} <p>优秀</p> {% else %} <p>凑活吧</p> {% endif %}
with
使用一个简单地名字缓存一个复杂的变量,当你需要使用一个“昂贵的”方法(比如访问数据库)很多次的时候是非常有用的 类似起别名 {% with total=business.employees.count %} {{ total }} employee{{ total|pluralize }} {% endwith %}
csrf_token
这个标签用于跨站请求伪造保护
4、自定义标签和过滤器
参考:https://www.cnblogs.com/Michael--chen/p/10503456.html
5、模板继承 (extend)
母版
<!DOCTYPE html> <html lang="en"> <head> <link rel="stylesheet" href="style.css" /> <title>{% block title %}My amazing site{% endblock %}</title> {% block css %} // 预留css给子模板写css {% endblock css %} </head> <style> .div1 { width: 200px; height: 200px; background-color: red; } </style> <body> <div class="div1"></div> <div id="sidebar"> {% block sidebar %} //有变化的内容写在 {% block name %}里面 <ul> <li><a href="/">Home</a></li> <li><a href="/blog/">Blog</a></li> </ul> {% endblock %} // 要有结束符 {% endblock name %} </div> <div id="content"> {% block content %} {% endblock %} </div> </body> {% block js %} // 预留给子模板写js {% endblock js %} </html>
子网页:
{% extends "base.html" %} <!-- 必须写extends,代表继承base.html -->
{% block sidebar %}
{{ block.super }} <!--继承父模板{% block name%} 里面的内容 -->
<h4>我是继承的</h4>
{% endblock %} //模板结束语
{% block content %}
<p>我是基础末班的</p>
{% endblock %}