




fast feedback to robot with better shape reward func, and learning could be much faster


open ai baseline
rllab


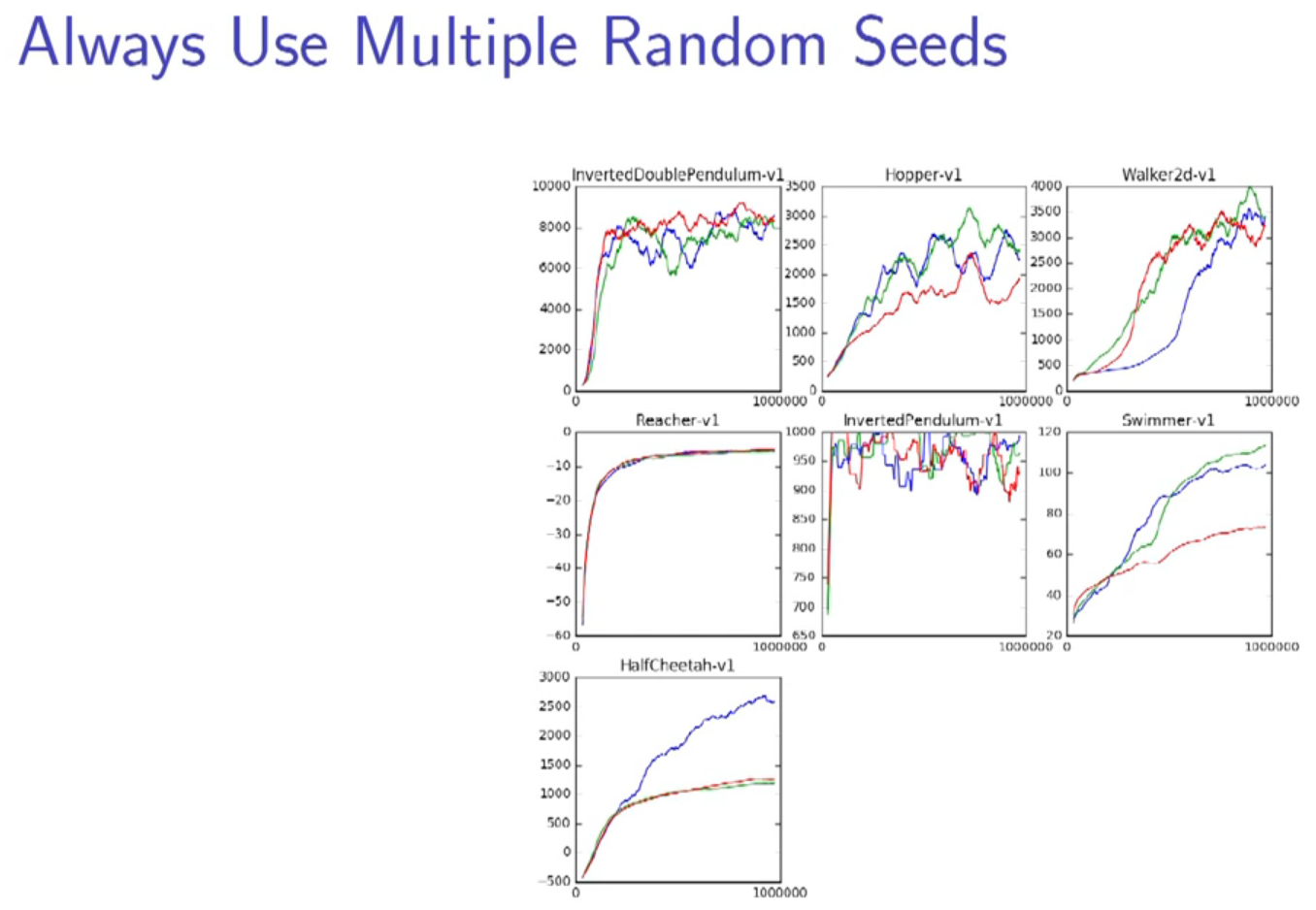
multiple tasks and multiple seeds to test the robustness.
don't believe only one trial's result, it could just be a fortunate trial, unless the imporvement is huge.







KL = 0.1 is a small update
KL = 10 is a large update




DQN is not effective enough in many problems, especially on continuous control problem.
But that doesn't mean it's a bad algorithm.
So you shouldn't expect an algorithm solving everything without tunning, at least now.
batch norm, dropout, or big networks? no, we try 2 layers with 64 units.
at least now these techniques are not suitable for RL.
if you don't care much about sample complexity, PG are probably the way to go.
qlearning is more implicit what is going in it , while PG is just gradient descent
dqn and it relatives work well game like image as input, while policy based works better on continuous control tasks, like locomotion
https://en.wikipedia.org/wiki/Sample_complexity

I use randomly initialization of hyperparameters........
audience laugh....