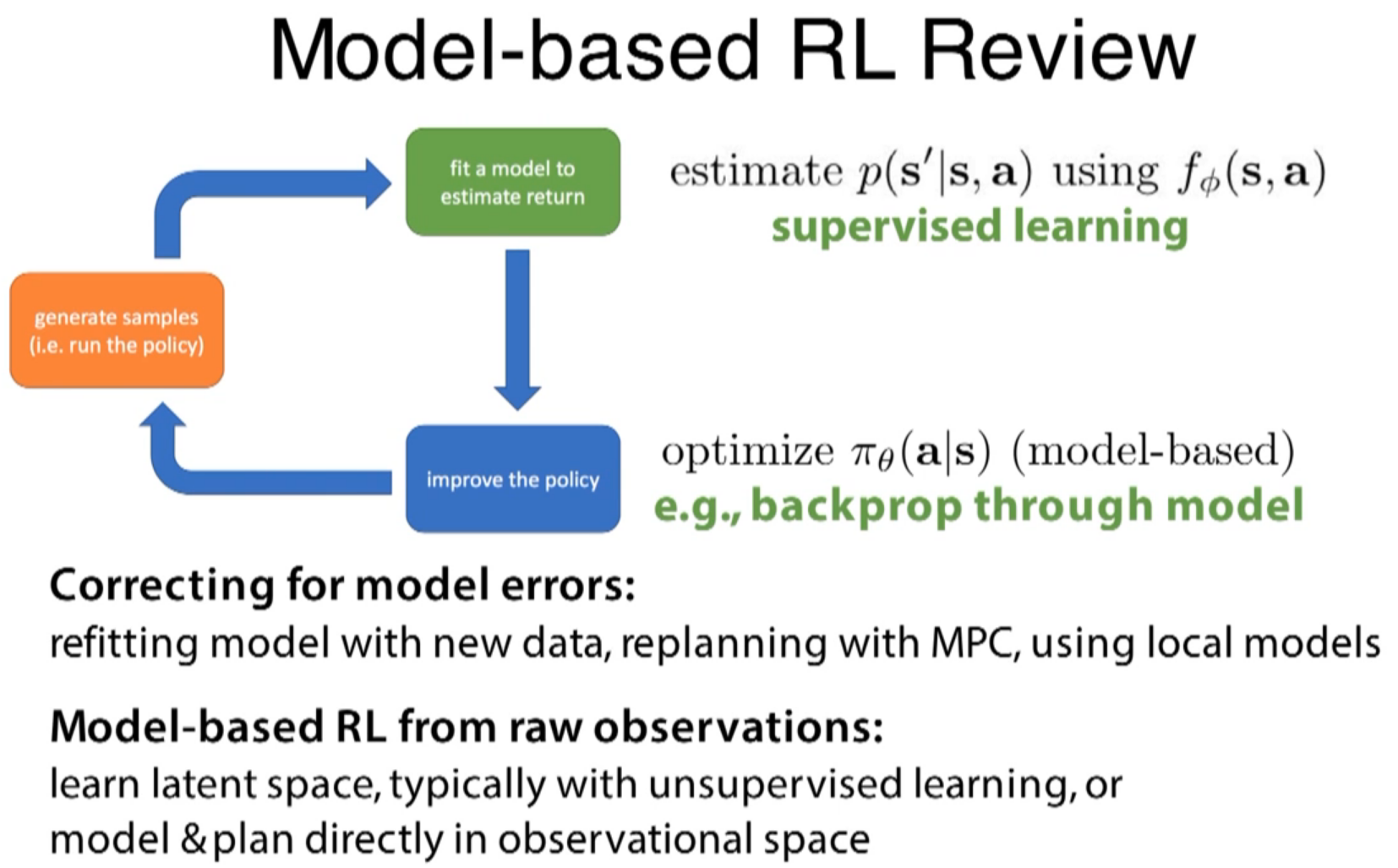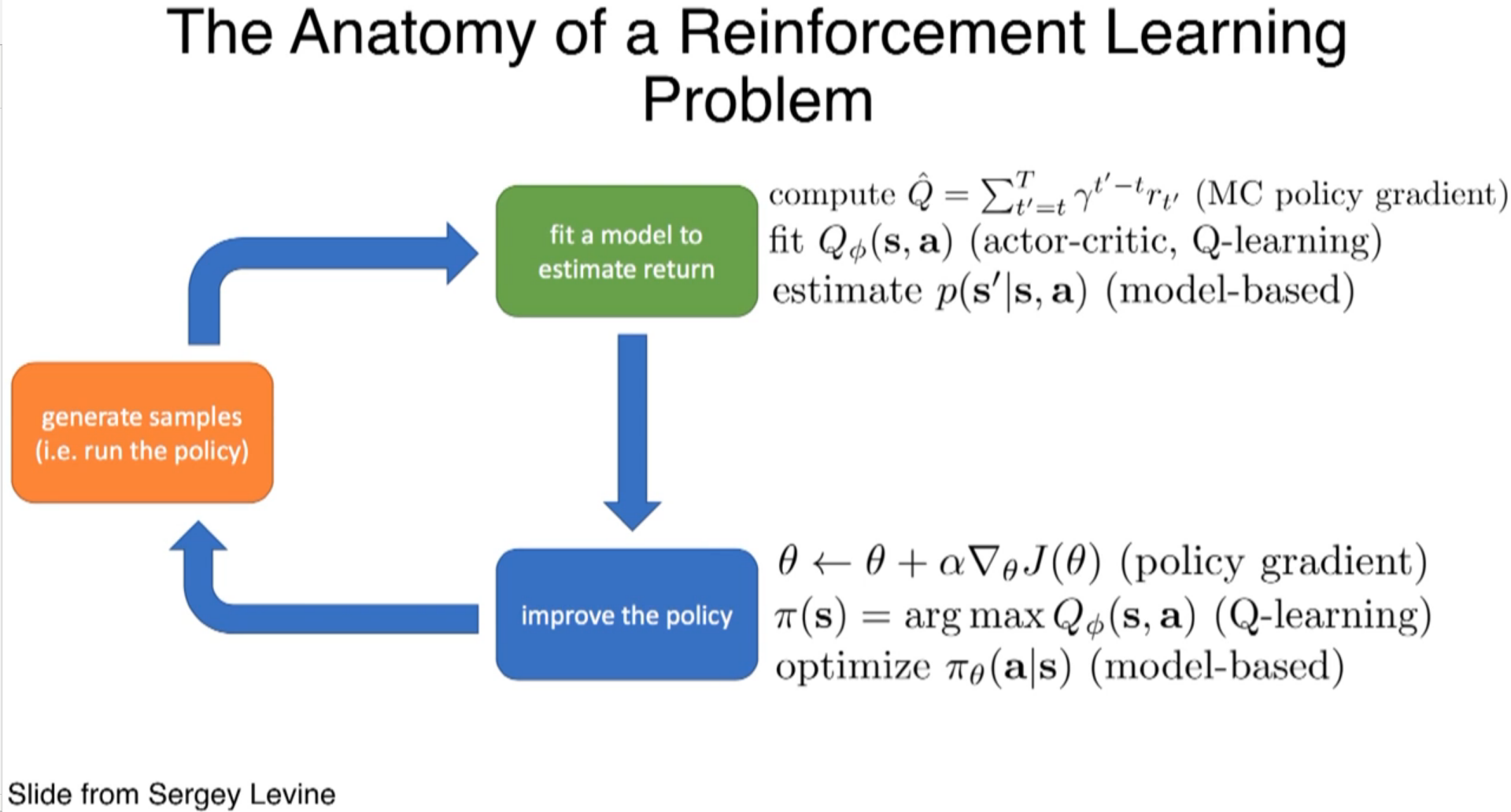
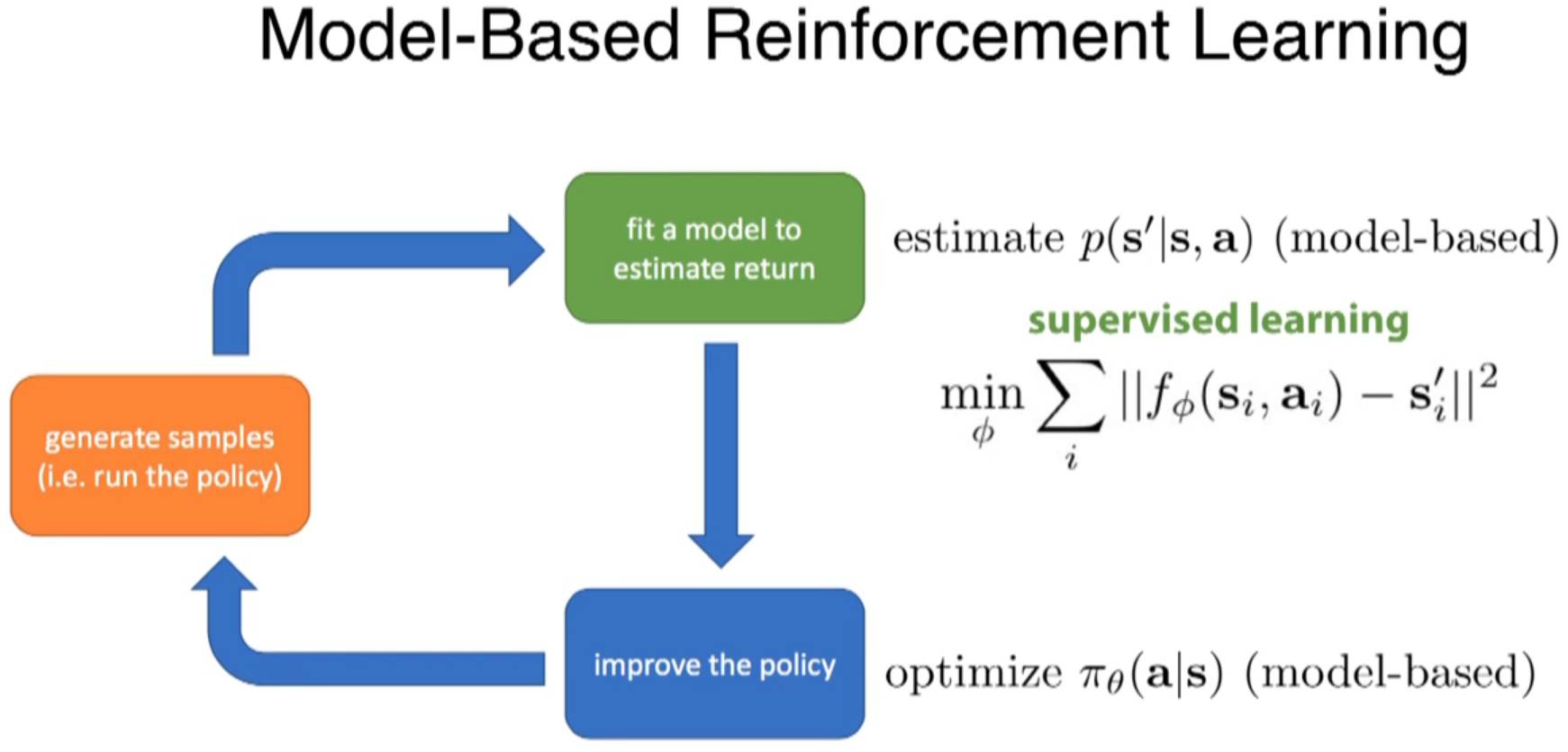






So, the process is similar to one-to-many RNN?

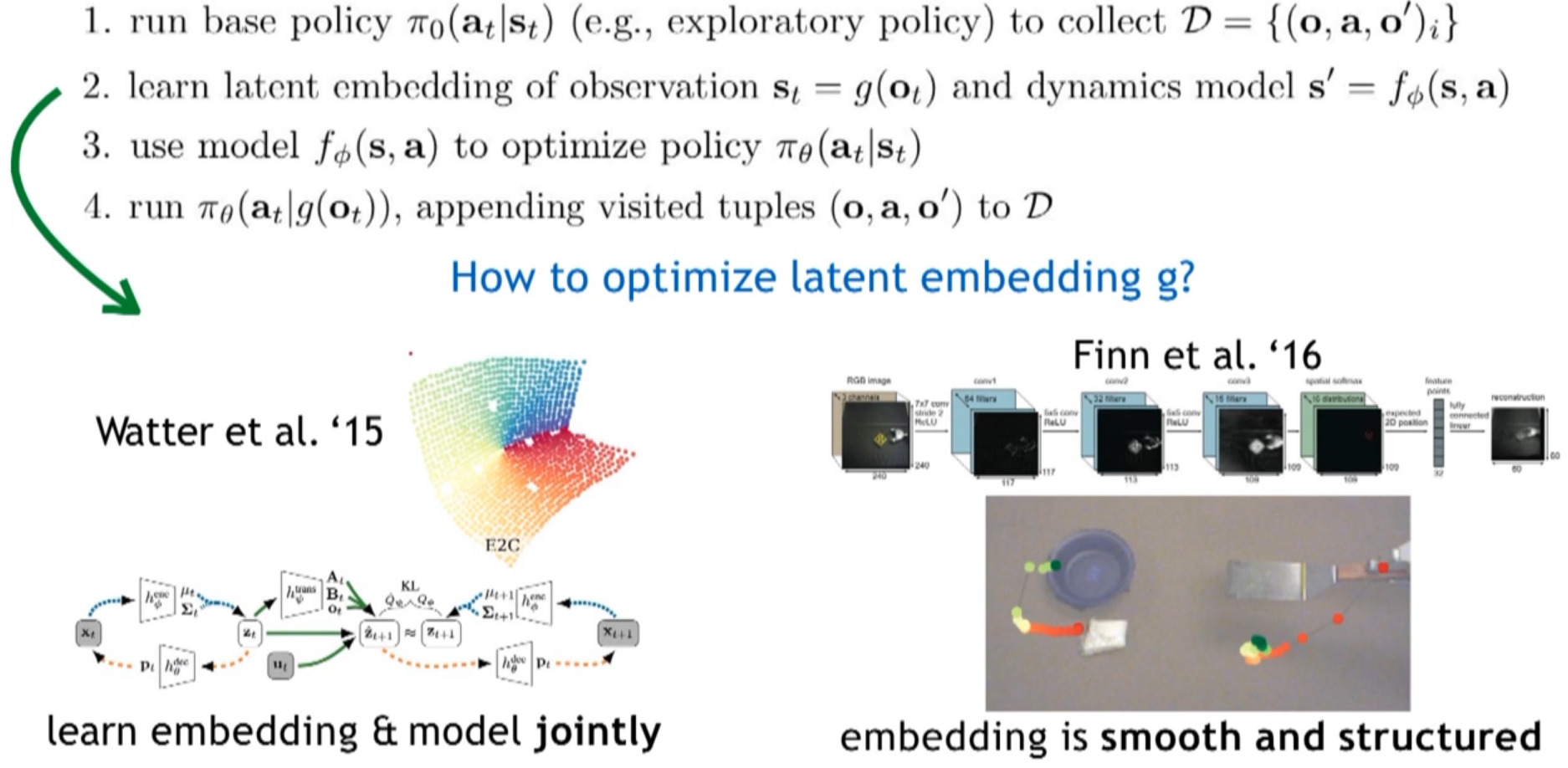
 learn much more efficiently than model-free method
learn much more efficiently than model-free method





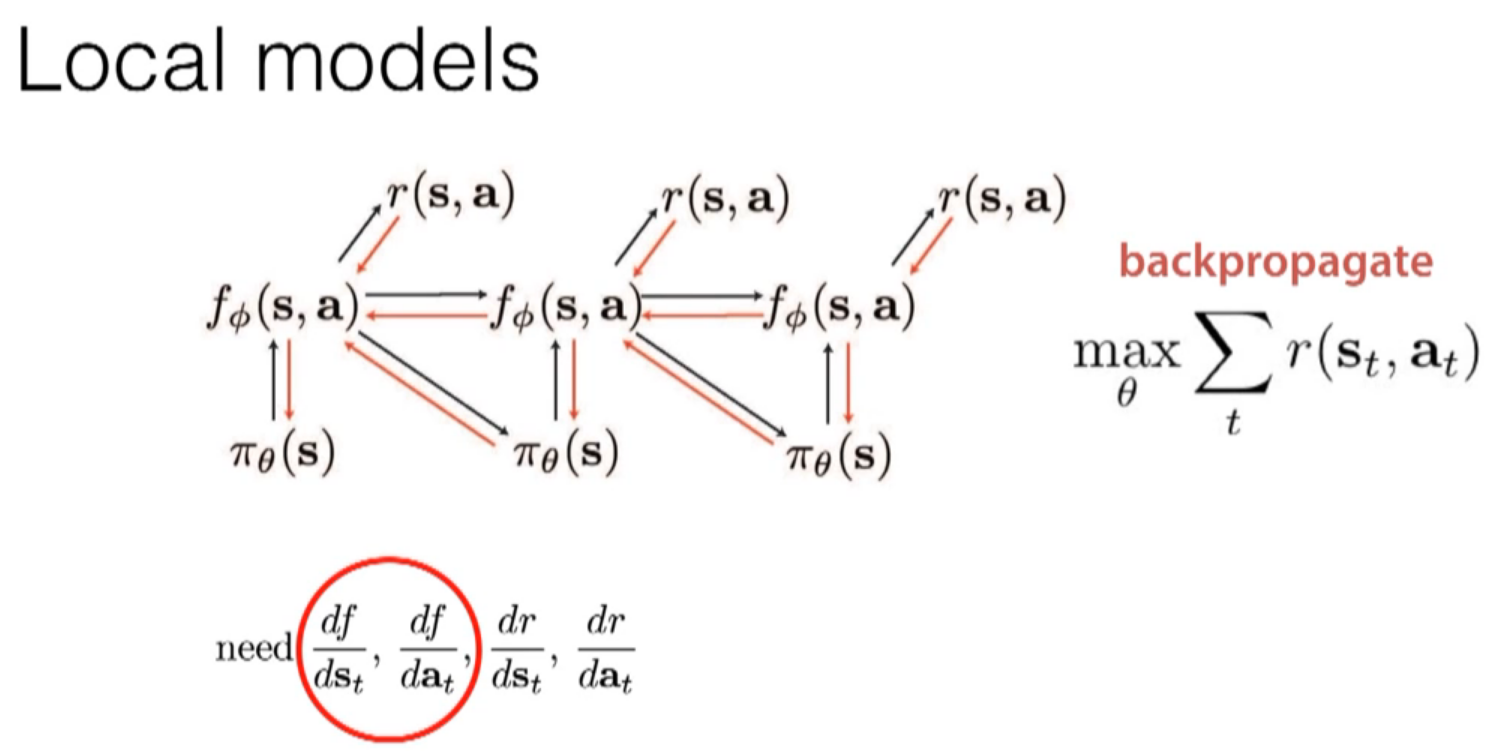
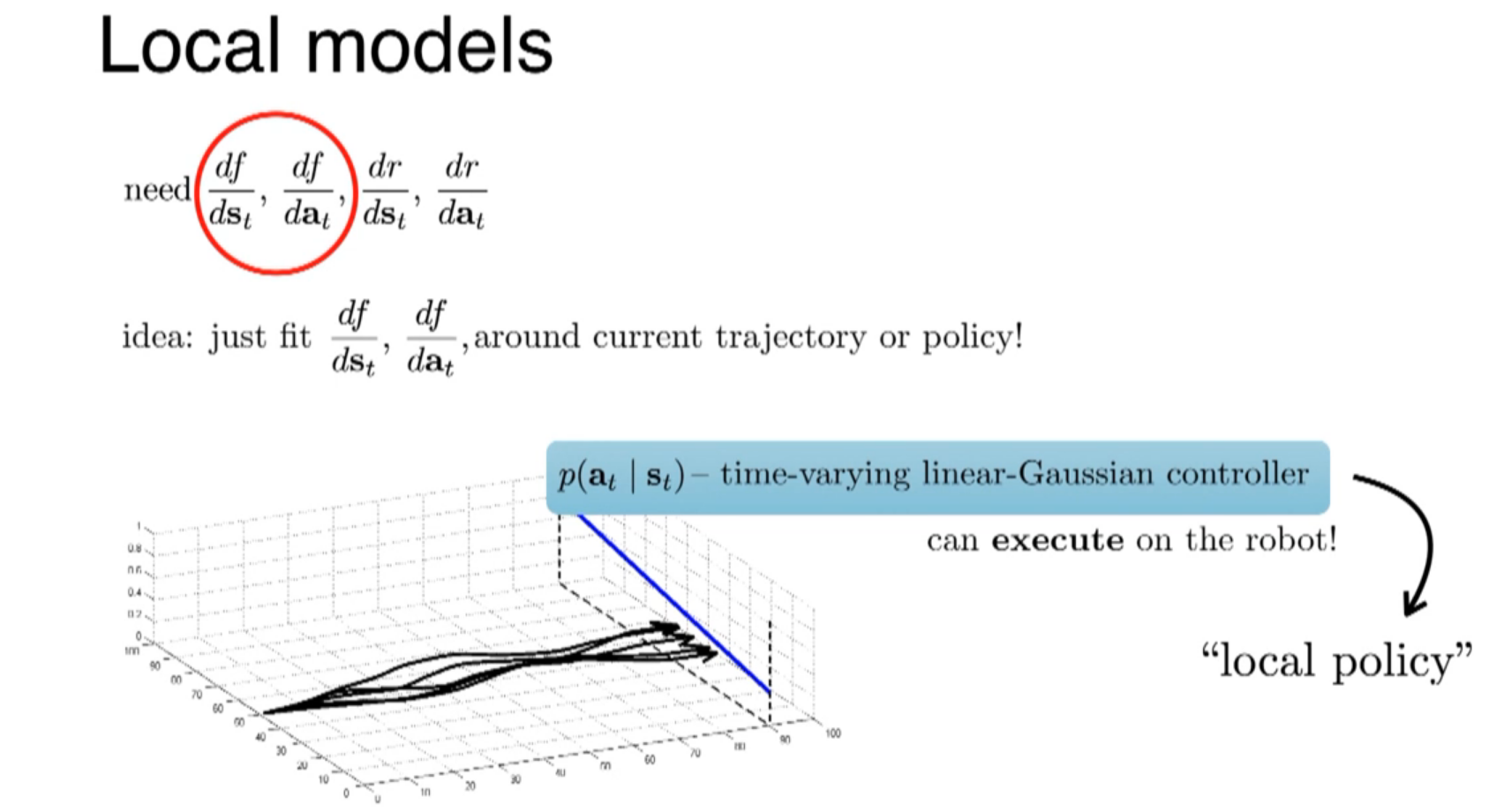





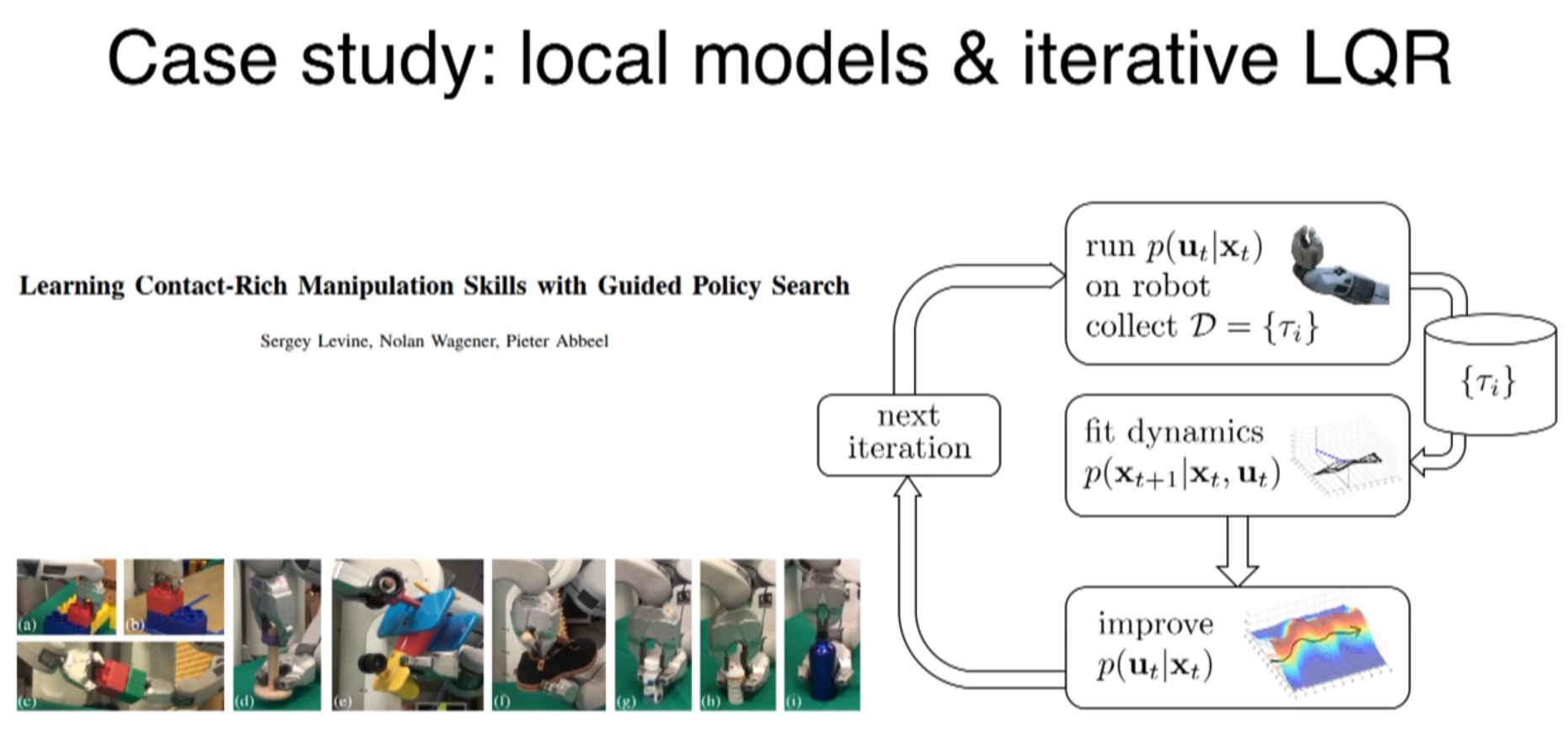

iteratively get better

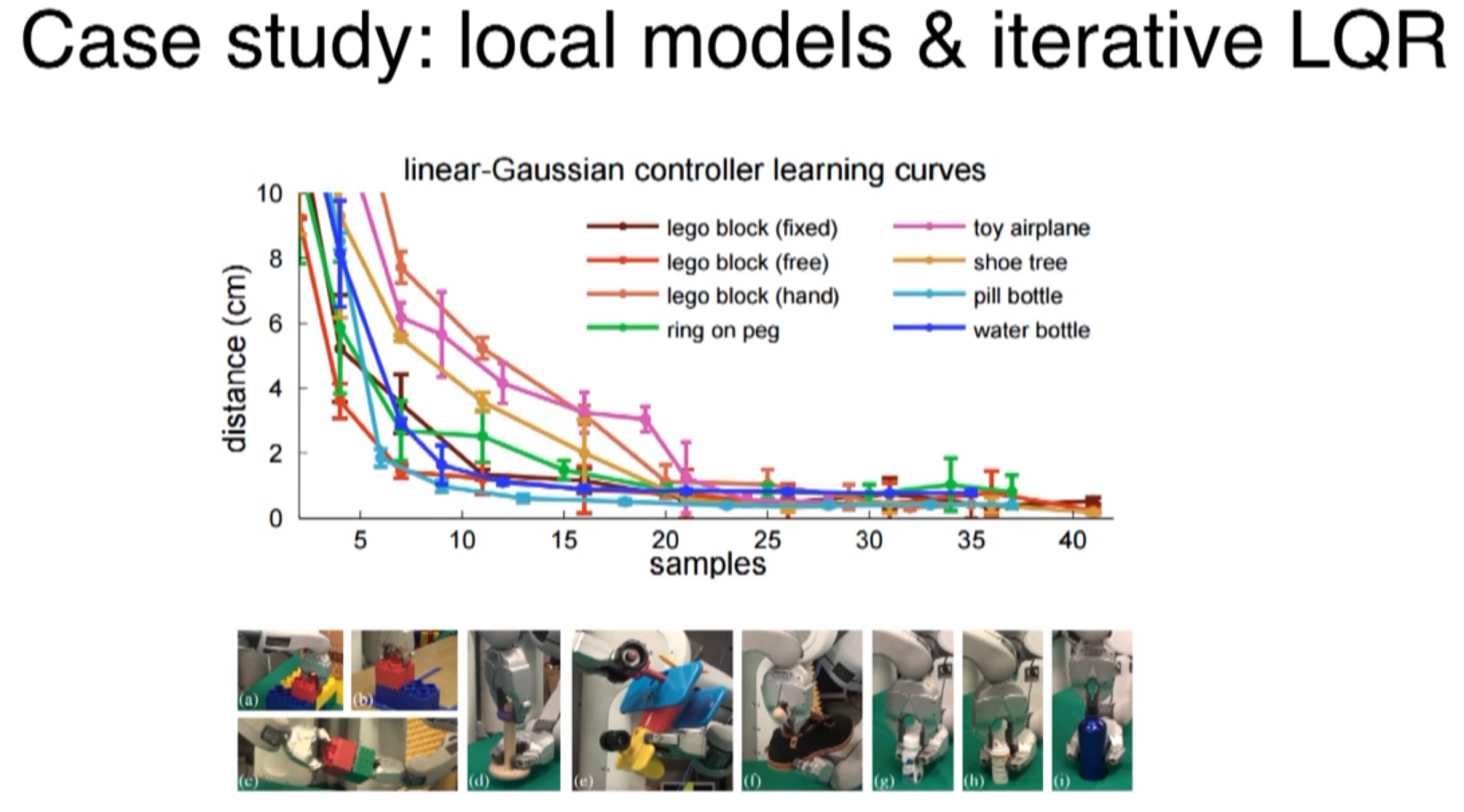




less than 300 trials ~ 25min robot time per task

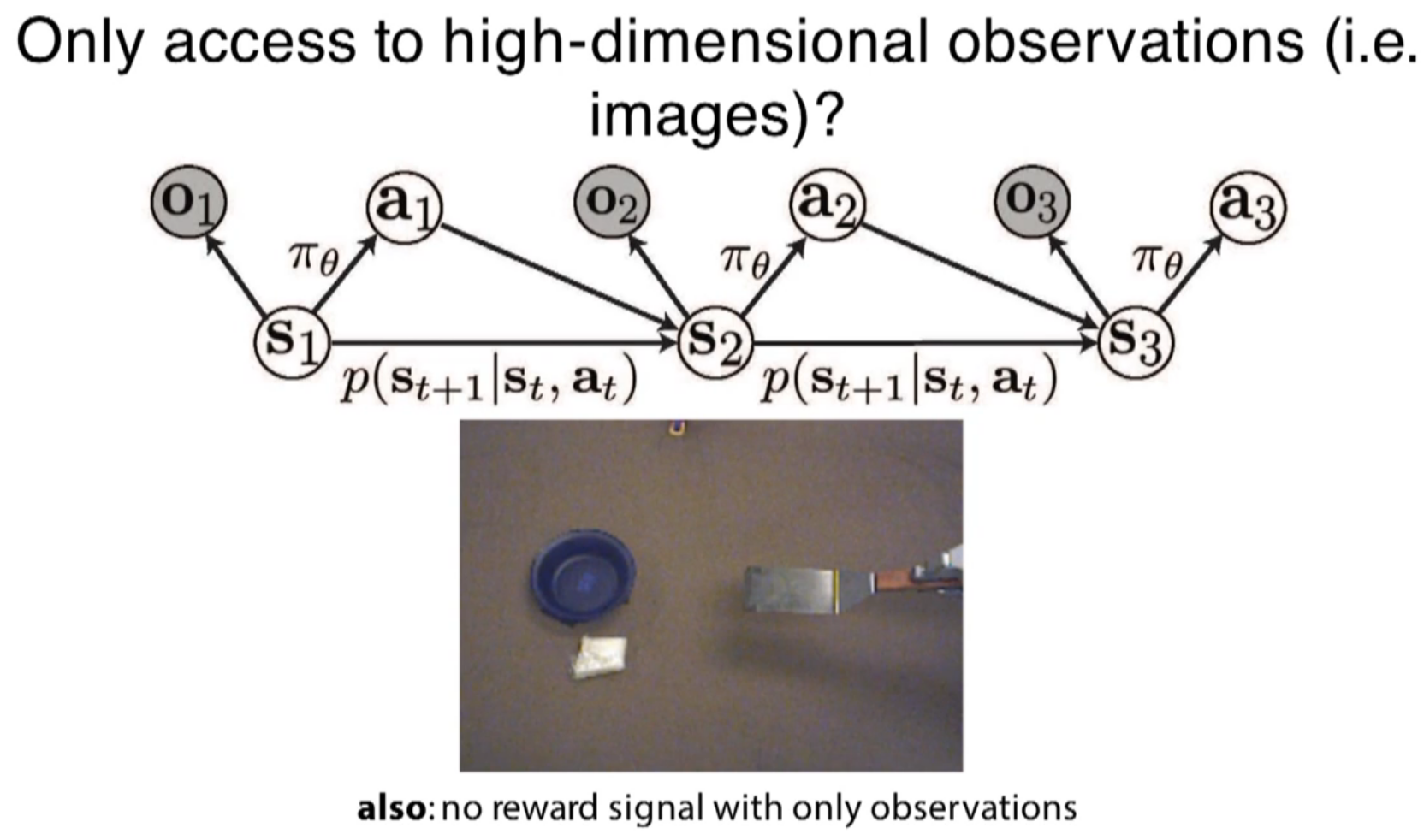

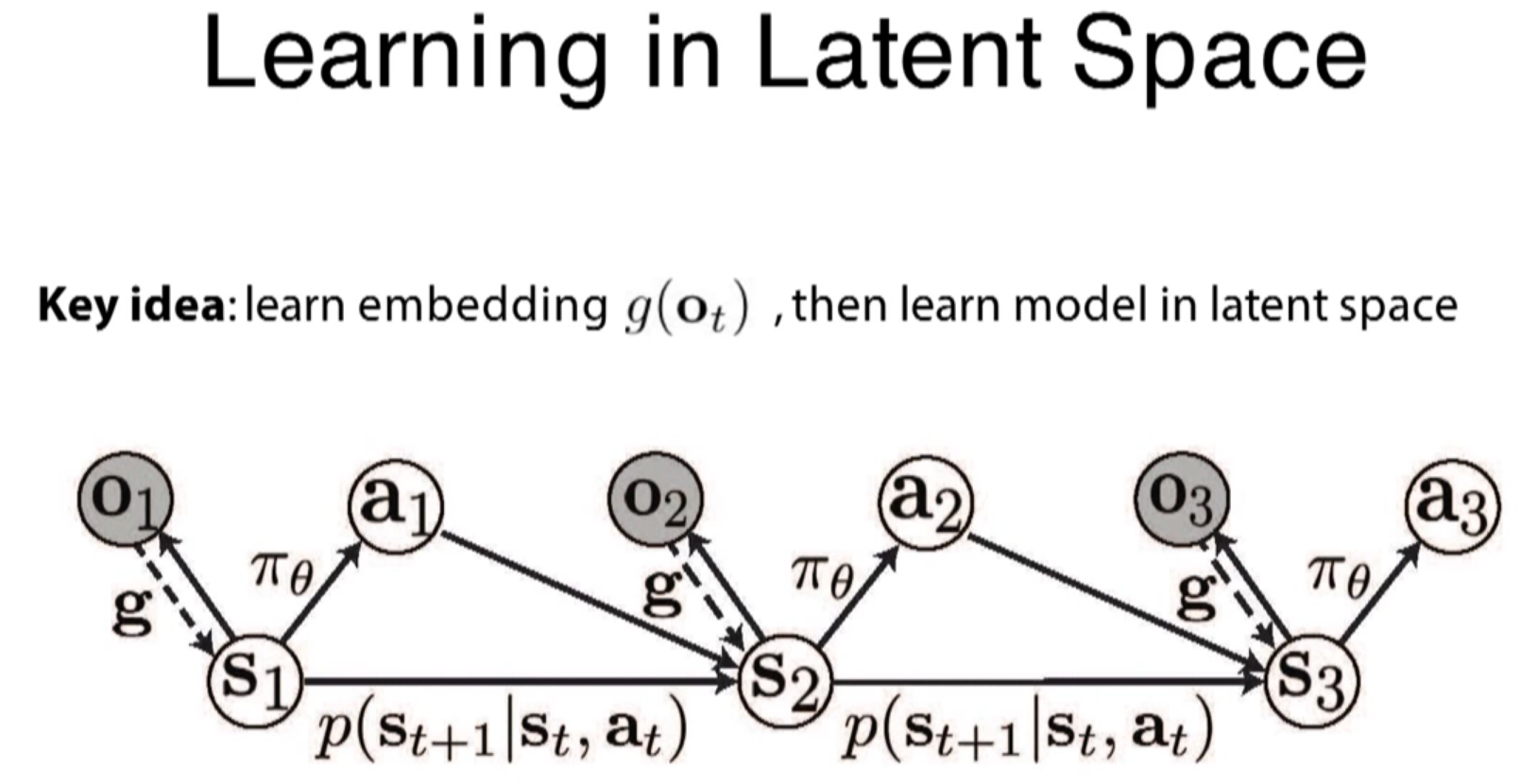


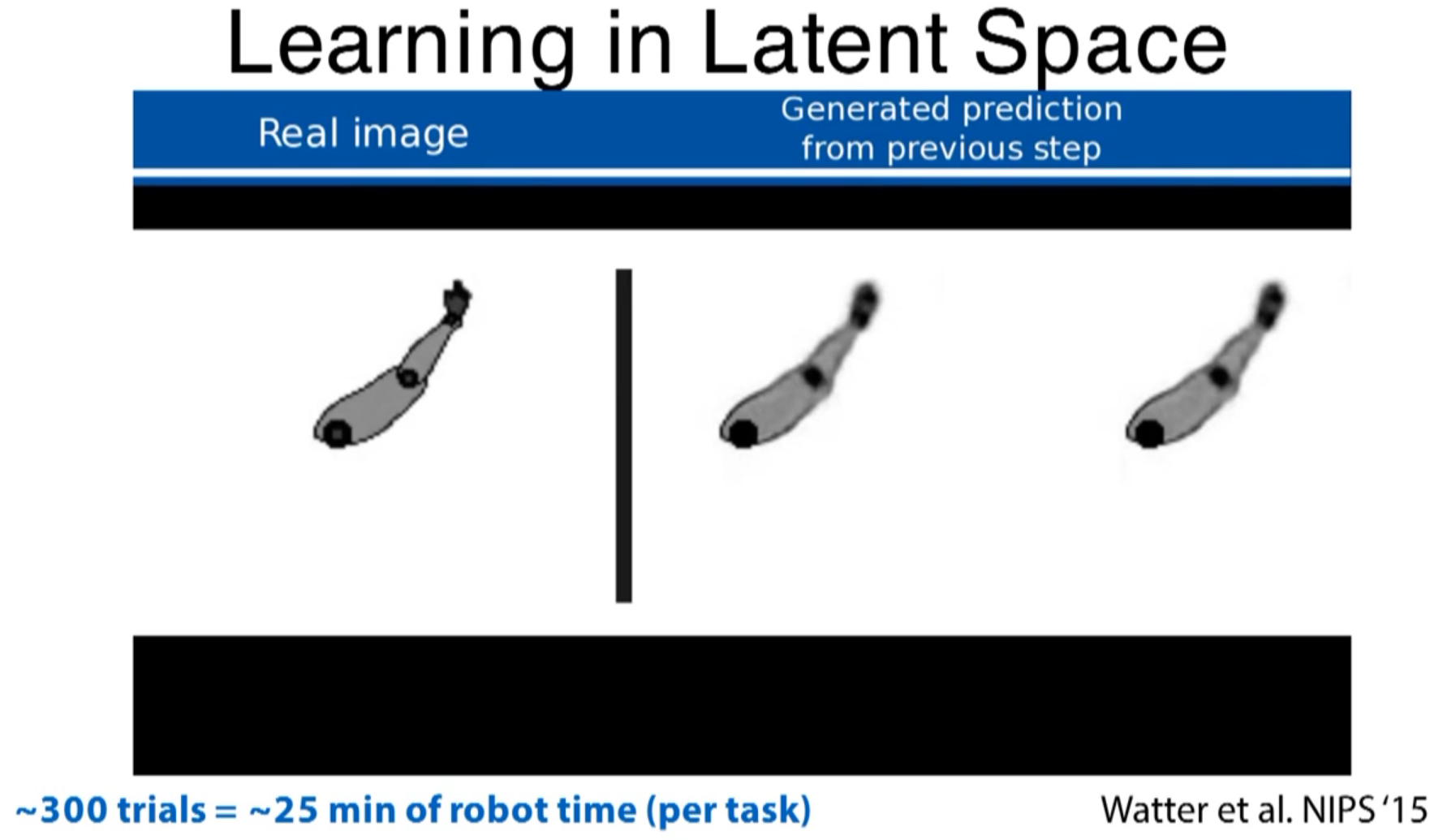





visual prediction from the observation
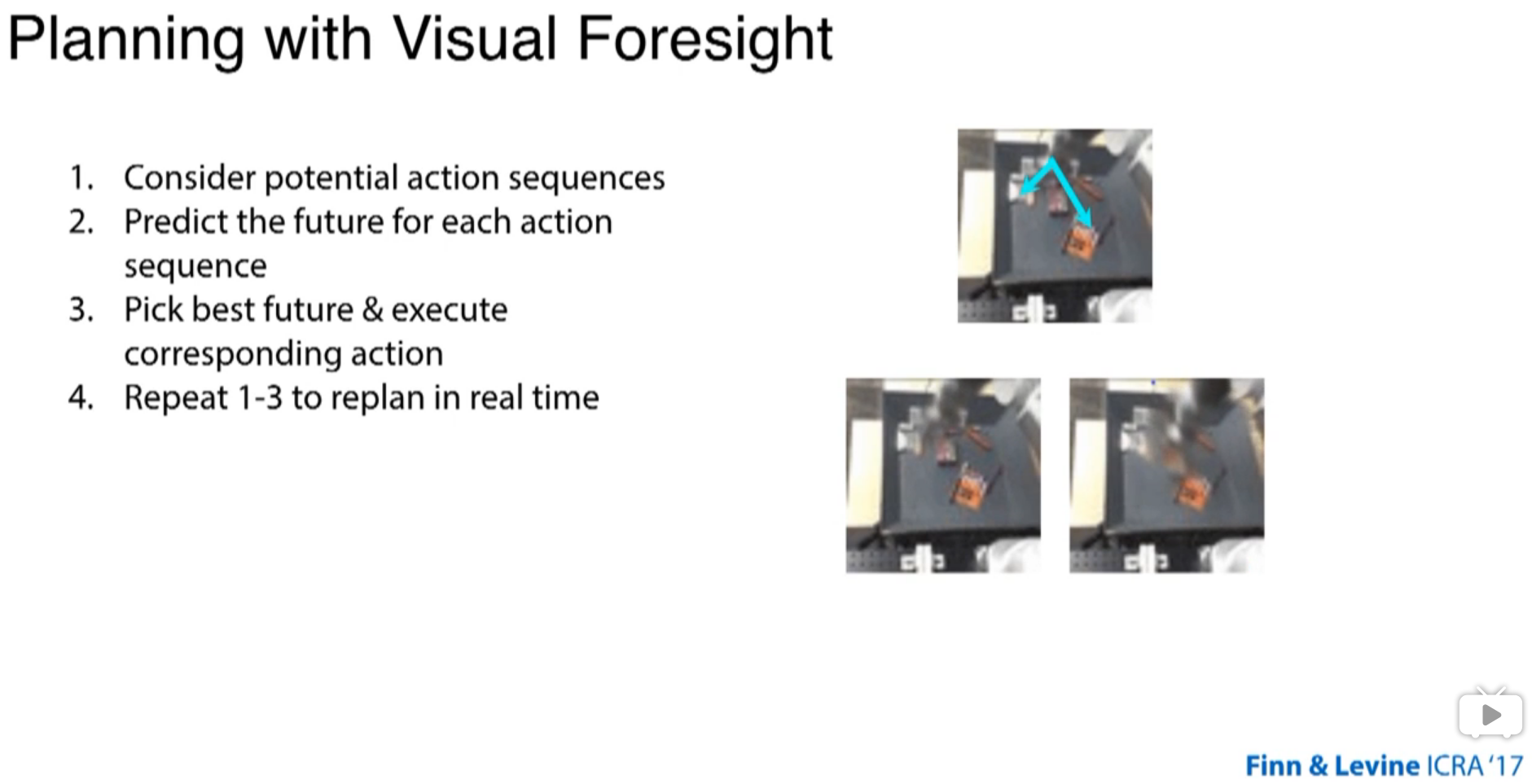



during train of model, there is no reward. Some random motions are programmed. at the task time, there is a reward function, basically trying to move a pixel to the goal position.