算法原理
由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选到一个类上,一定程度上克服了算法陷入局部最优状态。
二分KMeans(Bisecting KMeans)算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二。之后选择能最大限度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目k为止。以上隐含的一个原则就是:因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点越接近于他们的质心,聚类效果就越好。所以我们就需要对误差平方和最大的簇进行再一次划分,因为误差平方和越大,表示该簇聚类效果越不好,越有可能是多个簇被当成了一个簇,所以我们首先需要对这个簇进行划分。
代码实现
本文在实现过程中采用数据集4k2_far.txt,聚类算法实现过程中默认的类别数量为4。其中辅助函数存于myUtil.py文件和K均值核心函数存于kmeans.py文件,具体参考《KMeans (K均值)算法讲解及实现》。
二分K均值主函数逻辑思想如下代码所示:
# -*- encoding:utf-8 -*- from kmeans import * import matplotlib.pyplot as plt dataMat = file2matrix("testData/4k2_far.txt", " ") # 从文件构建的数据集 dataSet = dataMat[:, 1:] # 提取数据集中的特征列 k = 4 # 外部指定1,2,3...通过观察数据集有4个聚类中心 m = shape(dataSet)[0] # 返回矩阵的行数 # 初始化第一个聚类中心: 每一列的均值 centroid0 = mean(dataSet, axis=0).tolist()[0] centList =[centroid0] # 把均值聚类中心加入中心表中 # 初始化聚类距离表,距离方差 # 列1:数据集对应的聚类中心,列2:数据集行向量到聚类中心距离的平方 ClustDist = mat(zeros((m, 2))) for j in range(m): ClustDist[j,1] = distEclud(centroid0,dataSet[j,:])**2 ''' color_cluster(ClustDist[:, 0:1], dataSet, plt) drawScatter(plt, mat(centList), size=60, color='red', mrkr='D') plt.show() ''' # 依次生成k个聚类中心 while (len(centList) < k): lowestSSE = inf # 初始化最小误差平方和。核心参数,这个值越小就说明聚类的效果越好。 # 遍历cenList的每个向量 #----1. 使用ClustDist计算lowestSSE,以此确定:bestCentToSplit、bestNewCents、bestClustAss----# for i in xrange(len(centList)): # 从dataSet中提取类别号为i的数据构成一个新数据集 ptsInCurrCluster = dataSet[nonzero(ClustDist[:, 0].A == i)[0], :] # 应用标准kMeans算法(k=2),将ptsInCurrCluster划分出两个聚类中心,以及对应的聚类距离表 centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2) # 计算splitClustAss的距离平方和 sseSplit = sum(multiply(splitClustAss[:, 1], splitClustAss[:, 1])) # 此处求欧式距离的平方和 # 计算ClustDist[ClustDist第1列!=i的距离平方和 sseNotSplit = sum(ClustDist[nonzero(ClustDist[:, 0].A != i)[0], 1]) if (sseSplit + sseNotSplit) < lowestSSE: # 算法公式: lowestSSE = sseSplit + sseNotSplit bestCentToSplit = i # 确定聚类中心的最优分隔点 bestNewCents = centroidMat # 用新的聚类中心更新最优聚类中心 bestClustAss = splitClustAss.copy() # 深拷贝聚类距离表为最优聚类距离表 lowestSSE = sseSplit + sseNotSplit # 更新lowestSSE # 回到外循环 # ----2. 计算新的ClustDist----# # 计算bestClustAss 分了两部分: # 第一部分为bestClustAss[bIndx0,0]赋值为聚类中心的索引 bestClustAss[nonzero(bestClustAss[:, 0].A == 1)[0], 0] = len(centList) # 第二部分 用最优分隔点的指定聚类中心索引 bestClustAss[nonzero(bestClustAss[:, 0].A == 0)[0], 0] = bestCentToSplit # 以上为计算bestClustAss # ----3. 用最优分隔点来重构聚类中心----# # 覆盖: bestNewCents[0,:].tolist()[0]附加到原有聚类中心的bestCentToSplit位置 # 增加: 聚类中心增加一个新的bestNewCents[1,:].tolist()[0]向量 centList[bestCentToSplit] = bestNewCents[0, :].tolist()[0] centList.append(bestNewCents[1, :].tolist()[0]) # 以上为计算centList # 将bestCentToSplit所对应的类重新更新类别 ClustDist[nonzero(ClustDist[:, 0].A == bestCentToSplit)[0], :] = bestClustAss ''' color_cluster(ClustDist[:, 0:1], dataSet, plt) drawScatter(plt, mat(centList), size=60, color='red', mrkr='D') plt.show() ''' # 输出生成的ClustDist:对应的聚类中心(列1),到聚类中心的距离(列2),行与dataSet一一对应 color_cluster(ClustDist[:, 0:1], dataSet, plt) print "cenList:",mat(centList) # 绘制聚类中心图形 drawScatter(plt, mat(centList), size=60, color='red', mrkr='D') plt.show()
评估分类结果
上述代码的”’注释部分给出了每次迭代时,聚类中心的变化情况,如下所示:
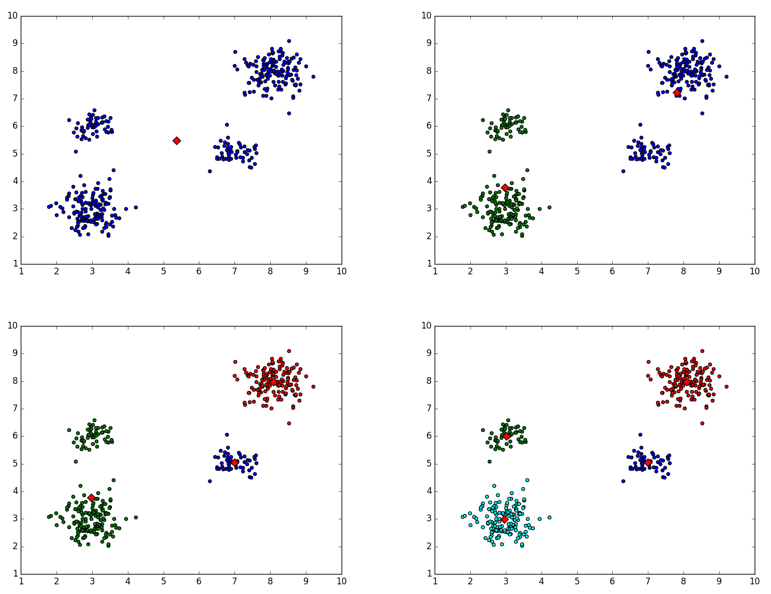
二分K均值聚类中心变化情况
相关