什么是Solr搜索
我们经常会用到搜索功能,所以也比较熟悉,这里就简单的介绍一下搜索的原理。
当然只是介绍solr的原理,并不是搜索引擎的原理,那会更复杂。
流程图
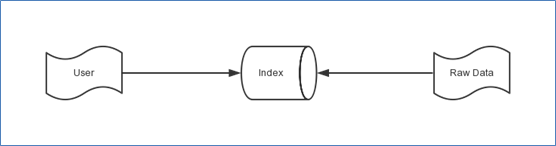
这是一个非常简单的流程图:
User:即需要搜索的用户。
Raw Data:需要搜索的内容,当然是源数据,可能是文本文件,可能是数据库的数据,可能是XML等等。
Index:有格式的数据。
其实从图中可以看出来:
- Solr搜索非常类似于读写数据库的过程。
-
Solr搜索最主要的两个问题(细节已经封装好):
- 怎样从元数据合理组织格式化成Index
- 怎样根据关键字从Index中调取相关数据(排序、模糊查询等等)。
类比一下,Index就相当于数据表,里面有很多记录,我们需要做的就是设计数据表的格式,有哪些列。并且根据关键字搜索。
Solr综述
Solr其实是一个WebApp,在官网下载后将war包放在web'容器下便可以直接运行,你自己的web项目通过HTTP请求的方式和Solr交互。当然需要现在Solr中生成索引库(类似不同的数据表)。HTTP请求中带有相关参数(关键字、需要搜索的索引库、排序规则….)。那么想爱先简单介绍下一些相关的概念:
索引Index,文档Docements,域Fields
Solr中数据最小单元为Field,比如Name、Age。Documents是一个具体的对象,如人。举例说明:Edwin是一个人,那么可以将Edwin抽象为一个Document,这个Document包含很多Fields,Name、Age、Sex….。一个索引库Index由许多Documents组成。
Index(Student) ß Docements(Edwin、AngelaBaby…) ß Fields(Name、Age…)
是不是很像数据库的模型? 其实完全可以把这个理解为数据库… 并且Index还真的有主键的概念,叫做Unique Field。
查询Query
上面解决了数据格式化成Index的问题,那么还剩下怎样根据关键字查询搜索结果的问题,先举个例子:
http://localhost:8983/solr/Artist/select?q=Artist_Name:周杰伦 &wt=json&indent=true
这就是web项目和Solr交互的一个Url
Localhost:8983/solr 这个事Solr项目
Artist是索引库Index
q=Artist_Name:周杰伦
q代表Query 意思是查询Artist_Name为周杰伦的数据
wt=json 指结果按照Json形式返回
indent=true 返回的数据格式化(也就是好看一点~)
通过这一个简单的请求,即可以明白Solr请求的一个基本过程了,有什么需求加什么参数,之后Solr解析请求,根据自己的匹配规则,一个很复杂的公式,计算所有Documents的得分,得分高的优先返回。最后Web项目获得得到搜索结果,格式化输出。
两个重要的文件
Schema.xml
这个文件其实就是对Index的配置,包括Field的类型,Unique Field,分词等等。
先看看整体结构:
-
-
<schema name="Artist" version="1.1">
-
<fieldtype name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true"/>
-
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
-
<fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/>
-
<field name="ID" type="int" indexed="true" stored="true" multiValued="false" required="true"/>
-
<field name="Name" type="text_ik" indexed="true" stored="true"/>
-
<field name="Name_Exact" type="string" indexed="true" stored="true" />
-
<field name="SpaceID" type="long" indexed="true" stored="true"/>
-
<field name="PinYin" type="text_general" indexed="true" stored="true"/>
-
<field name="SongNum" type="int" indexed="true" stored="true"/>
-
-
<copyField source="Artist_Name" dest="Artist_Name_Exact" />
-
<!-- field to use to determine and enforce document uniqueness. -->
-
<uniqueKey>ID</uniqueKey>
-
-
<!-- field for the QueryParser to use when an explicit fieldname is absent -->
-
<defaultSearchField>ID</defaultSearchField>
-
-
<!-- Chinese -->
-
<fieldType name="text_ik" class="solr.TextField">
-
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
-
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
-
</fieldType>
-
-
<!-- SolrQueryParser configuration: defaultOperator="AND|OR" -->
-
<solrQueryParser defaultOperator="OR"/>
-
</schema>
FieldType代表Field的类型,可以自定义也可以使用Solr提供的Type,具体支持的Type可以参考Solr文档,其中需要稍微解释一下的是string,实现的class是solr.StrField,string的意思是将Field当成字符串,那么如果在搜索时,不会进行分词。只能整体匹配,例如将Name设置为string,那么当搜索周杰伦的时候,只有Name完全和周杰伦相同才会被匹配,周杰,周杰伦你好…这些都不会匹配,这个在精确查找时很有用。
Unique Field :其实是主键的意思,就是说在所有的Documents中被设置成Unique的Field只能有唯一值。当然在Index生成的时候,不用去重,Solr并不会报错,比如向Solr输入
ID:1 Name:张三
ID:1 Name:李四
如果ID为Unique Field,那么Solr可能会根据先后顺序,只会存储一个ID为1的Document,剩余重复ID的Document会被忽略。
Field中还有很多属性:
Name和Type就不说了
Indexed:表示此Field是否索引,意思就是能否被搜索到,如果Name设置为false,那么搜索Name=周杰伦是没有结果的。
Stored:表示此Field是否被存储。
multiValued:表示此Field能否有多值,即Category可以有多个值:如原创歌手、华语男歌手等等。默认false,Unique Field必须显式设置为false。
Required:表示此Field是否能为空,默认false,Unique Field必须设置为true。
-
<copyField source="Name" dest="Name_Exact" />
这是一个很有用的东西,从名字就能看出来是赋值Field,最大的作用便是可以让一个Field有多个不同的Type。
比如Name一个可以设置为text_ik(分词器,可以看我的博客:三、Solr多核心及分词器(IK)配置)
一个设置为string
那么模糊搜索时,可以使用Name,精确搜索时使用Name_Exact。
Solrconfig.xml
Scheme.xml是对索引库中Documents的配置,那么solrconfig就是对索引库的整体配置。配置requestHandler,有点类似于filter,就是在请求前后对请求进行预处理。这个之后碰到具体情况再具体分析,因为一般情况下设置好了之后,极少需要改动此文件。
总结
其实我个人使用Solr后觉得,如上面画的简单的流程图,最重要的两个问题:
-
查询条件
查询哪些Field,用什么方式查询,什么排序,比如按照更新时间排序,还是在搜索歌曲时HQ、SQ优先等等,主要用到了Url参数、solrconfig中的requestHandler。
-
Index的设计
这是重中之重,我觉得大部分情况下应该都是使用solr从数据库中读取数据生成索引,这就要求原来的数据库设计就要比较合理,如果原来的数据库比较乱,那么就需要大量的SQL将表联结等等操作,并且出错的概率也高。