C# Alloc Free编程
首先Alloc Free这个词是我自创的, 来源于Lock Free. Lock Free是说通过原子操作来避免锁的使用, 从而来提高并行程序的性能; 与Lock Free类似, Alloc Free是说通过减少内存分配, 从而提高托管内存语言的性能.
基础理论
对于一个游戏服务器来讲, 玩家数量是一定的, 那么这些玩家的输入也就是一定的; 对于每一个输入, 处理逻辑的时候, 必然会产生一些临时对象, 那么就需要Alloc(New)对象; 然后每次Alloc的时候, 都有可能会触发GC的过程; GC又会将整个进程Stop一会儿(不管什么GC, 都会Stop一会儿, 只是长短不一样); 进而Stop又会影响到输入处理的速度.
这个链式反应循环, 就是一个假设. 只要每个过程产生下一步, 足够多(或者时间长了), 能够维持链式反应. 那么最终的表现就是系统过载. 消费速度越来越慢, 玩家的请求反应迟钝, 进程的内存越来越多, 进而OOM.
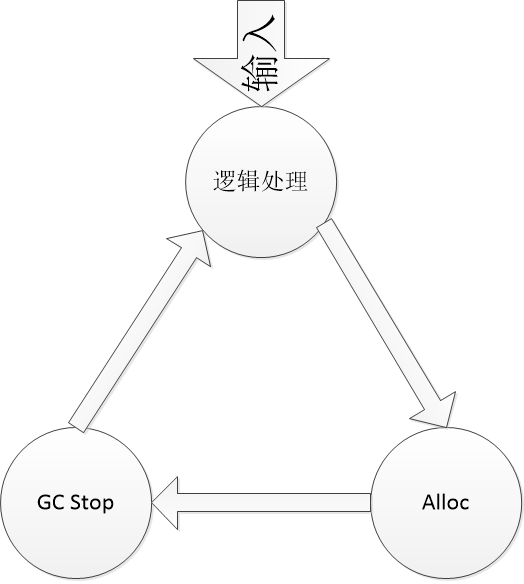
如果每个消息处理的耗时比较长, 那么堆积在一起的是输入; 如果每个消息处理的Alloc比较多, 那么堆积在一起的是GC. 这是两个基本的观点.
再回头考虑我们所要解决的问题, 我们要解决一个进程处理5000玩家Online. 那这5000个人, 一秒所能生产的消息数量也就是5000左右个消息, 而我们编程面对的CPU, 一秒处理可是上万甚至更高的数量级. 所以大概率不会堆积在输入这边.
但是Alloc就不一样, 每个业务逻辑消息, 都有其固然的复杂性, 很有可能一个消息处理, 产生了10个小的临时对象, 处理完成后就是垃圾对象. 那么就有10倍的系数, 瞬间将数量级提高一倍. 如果问题再复杂一点呢, 是不是有可能再提高到一个数量级?
这是有可能的!
某游戏服务器内部有物理引擎, 有ARPG的战斗计算, 每个法球/子弹都是一个对象, 中间所能产生的垃圾对象是非常多的, 所以大一两个数量级, 是很容易做到的.
最开始, 我在优化某游戏服务器的时候, 忽略了这一点, 花了很长时间才定位到真正的问题. 直到定位到问题, 可以解释问题, 然后fix掉之后, 整个过程就变得很容易理解, 也很容易理解这个混沌系统为何运行的比较慢.
优化前后的对比
最开始在Windows上面编译, 调试和优化服务器. 以为问题就这么简单, 但是实际上在Linux上面跑的时候, 还是碰到了一点问题.
这是服务器最开始用WorkStationGC跑2500人时候的火焰图, 最左面有很多一块时间在跑SpinLock, 问了微软的人, 微软的人也不知道.

然后当时相同的版本在Intel和AMD CPU下面跑起来, 有截然不同的效果(AMD SA2性能要高一些, 价格要低一些). 以至于以为是Intel CPU的BUG, 或者是其他原因.
WorkStationGC和ServerGC切换貌似对服务器性能影响也不是很大----都是过载, 机器人开了之后就无法正常的玩游戏, 延迟会非常高.
巧遇XLua
服务器内部有用XLua来封装和调用Lua脚本, 有很多脚本都是策划自己搞定的, 其中包括战斗公式和技能之类的.
我们都知道MMOG的战斗公式会很复杂, 可能一下砍怪, 会调获取玩家和怪物的属性几十次(因为有很多种不同的战斗属性). 然后又是一个无目标的ARPG, 加上物理之类的, 一次砍杀可能会调用十几次战斗公式, 所以数量级会有提升.
XLua在做FFI的时候, 会将对象的输入和输出保留在自己的XLua.ObjectTranslator对象上, 以至于该对象的字典里面包含了数百万个元素. 所以调用会变得非常慢, 然后内存占用也会比较高. 这是其一.
第二就是, 每个参数pass的时候, 可能都会产生new/delete. 因为服务器这边字符串传参用的非常多, 所以每次参数传递, 可能都会对Lua VM或者CLR产生额外的压力.
基于这两点原因, 我把战斗公式从Lua内挪到C#内, 然后对Lua GC参数做了相应的调整. 然后发现有明显的提升.
后来的事情
后来的事情就比较简单了, 因为发现减少这次大量的Alloc, 会极大的提高程序的性能. 所以后续的工作重点就放在了减少Alloc上, 然后火焰图上会有明显的对比差别.
这是中间一个版本, 左边pthread mutex的占比少了一些.
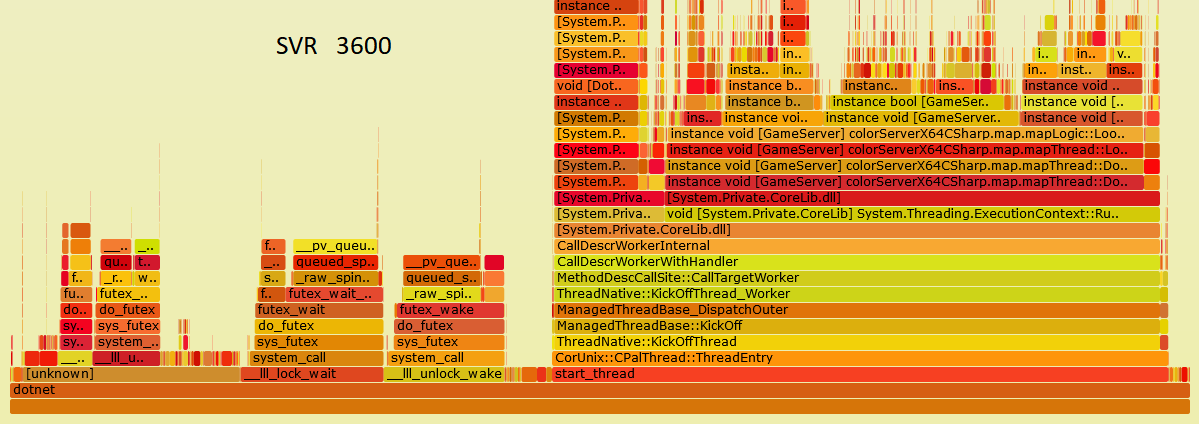
这是4月优化后的版本, pthread mutex占比已经小于10%, 可能在5%以内.

而服务器目前的版本, pthread mutex占比已经小于2%. 几乎没有高频的内存分配.
这就是我说的Alloc Free.
现象, 解释和最优化编程
继续回到最开始的那个图, 如果不砍断Alloc, 那么就会GC Stop, 进而就会影响到处理速度.
这是C#在Programming Language Benchmark Game上的测试, 可以看到C#单纯讨论计算性能, 和C++的差距已经不是很大.
而某游戏服务器内, 数百人跑在一个Server进程内, 都会都会出现处理速度不足, 猜想起来核心的问题就在GC Stop. 这是一个业务内找到AllocateString耗时的细节, 其中大部分在做WKS::gc_heap::garbage_collect. 这种情况在WorkStationGC下面比较突出, ServerGC下面也会有明显的问题. 核心的矛盾还是要减少不必要的内存分配, 降到CLR的负载.
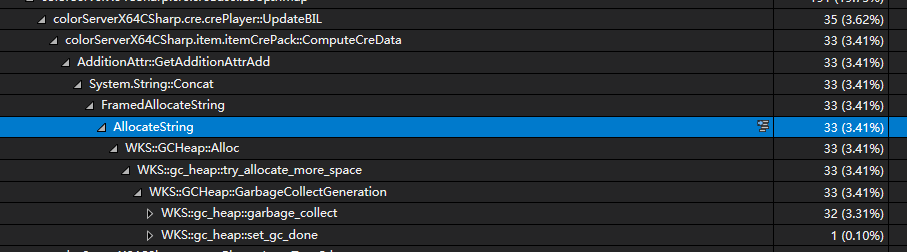
当然这个例子比较极端, 从优化过程的经验来看, 10%的Alloc大概有5%的GC消耗. 当一个服务器进程有30%+的Alloc时, 服务器的性能无论如何也上不去.
这是最核心的矛盾. 只有CPU大部分时间都在处理业务逻辑, 才能尽可能的消费更多的消息, 进而系统才不会出现过载现象, 文章最开始说的链式反应也就不会发生.
C#性能的最优化编程
实际上就变成了怎么减少内存分配的次数. 这里面就需要知道一些最基本的最佳实践, 例如优先使用struct, 少装箱拆箱, 不要拼接字符串(而是使用StringBuilder)等等等等.
但是单单有这些还是不够的, 还需要解决复杂业务逻辑内部产生的垃圾对象, 还需要不影响正常业务逻辑的开发. 关于这部分, 在后面一文中会详细讨论, 此处就不做展开.
非托管内存
C#程序内存的分配, 实际上还包含Native部分alloc的内存, 这一点是比较隐性的. 而且由于Windows libc的内存分配器和Linux内存分配器的差异性, 会导致一些不同.
我们在使用dotMemory软件获取进程Snapshot的时候, 可以获得完整托管对象的个数, 数据, 以及统计信息; 但是对非托管内存的统计信息缺没有. 由于服务器在Windows Server上面经过长时间的测试, 例如开4000个机器人跑几天, 内存都没有明显的上涨, 那么可以大概判断出来大部分逻辑是没有内存泄漏的.
Linux上应用和Windows上不一样的, 还有glog的日志上报, 但是关闭测试之后发现也没有影响. 所以问题就回到了, Windows和Linux有什么差异?
带着这个问题搜索了一番, 发现Java程序有类似的问题. Java程序也会因为Linux内存分配器而导致非托管堆变大的问题, 具体可以看Java堆外内存增长问题排查Case.
后来将Linux的启动命令改成:
LD_PRELOAD=/usr/lib/libjemalloc.so $(pwd)/GameServer之后, 跑了一晚上发现内存占用稳定. 基本上就可以断定该问题和Java在Linux上碰到的问题一样.
后来经过搜索, 发现大部分托管内存语言在Linux都有类似的优化技巧. 包括.net core github内某些issue提到的. 这一点可以为公司后续用Lua做逻辑开发的项目提供一点经验, 而不必再走一次弯路.
参考: